Как сделать SEO самому - Часть 2: Техническая оптимизация
Содержание:
- Зачем нужна техническая оптимизация
- Как поисковые системы сканируют и индексируют сайты
- Задача SEO-специалиста или веб-мастера
- Проблема дублирования:
- Страницы сайта доступны в нескольких вариантах
- Особенности архитектуры сайта
- Get-параметры
- В чем проблема дублей для поиска
- Простая настройка Яндекс Вебмастера и Google Search Console
- Robots.txt:
- Полезные материалы
- Запрет параметров
- Обработка параметров с помощью Clean-param
- Обработка параметров с Google Search Console
- Дополнительные рекомендации по настройке
- Canonical:
- Что это
- Зачем нужен canonical
- Как действует робот
- Как реализовать canonical
- В каких ситуациях использовать canonical
- Sitemap
- Что делать с пагинацией
- Микроразметка
- HTML
- Как осуществлять проверку
- Выводы
Предыдущая статья: Как сделать SEO самому - Часть 1: Введение, что такое SEO
В этой статье речь пойдет о том, как подготовить сайт для сканирования поисковыми системами.
Для чего это нужно и почему важно
Чтобы сайт ранжировался в поисковой выдаче он должен быть просканирован и добавлен в базу данных поисковой системы. Нет страницы сайта в поисковой базе – нет на нее трафика из органической выдачи.
Для обхода и сканирования всего интернета используются поисковые роботы (краулеры, пауки, боты) – автономные программы, которые делают запросы к каждому URL, получают ответ, анализируют содержимое и сохраняют на своем сервере. Этот процесс принято называть индексированием.
Сайт должен быть пригоден для сканирования и индексирования.
Как примерно это происходит (поверхностно)
Точно не известно, как именно работает поисковая система, и что конкретно ищет на страницах поисковой робот. SEO – это, вообще, самая настоящая абстракция, работа с большой неизвестностью. Чтобы немного конкретизировать работу и перейти к каким-то осмысленным действиям, можно попытаться смоделировать работу поисковиков, т.е. мысленно упростить и разделить на этапы.
Итак, наша модель будет состоять из четырех аспектов:
-
выполнение роботом запроса и получение ответа,
-
извлечение содержимого страницы,
-
добавление извлеченного контента в базу данных (индексирование),
-
анализ и ранжирование.
Шаг 1 - Программа выполняет запрос к URL и получает ответ
Что такое запрос, методы (виды запросов).
Пример:
Простейшая программа на python выполняет get-запрос к главной странице нашего сайта:
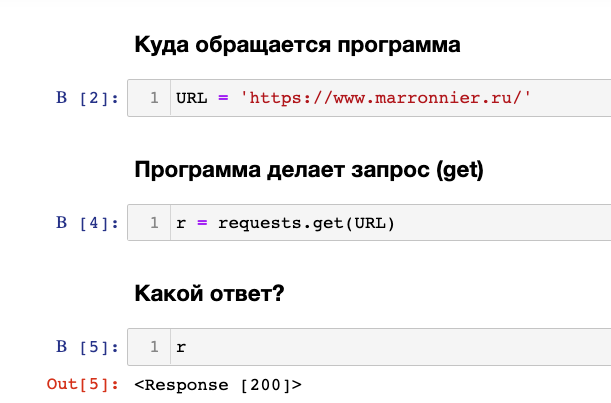
Вместе с кодом ответа робот получает тело ответа. В нашем случае (ответ 200 - ОК) это весь html-код запрашиваемой страницы.

Шаг 2 – Робот извлекает содержимое
Программа осуществляет парсинг – так принято называть анализ полученного html-содержимого. Таким образом поисковая система пытается разобраться, какой контент содержит страница: заголовки, тексты, картинки, цены, функциональные элементы и т.д.
Пример:
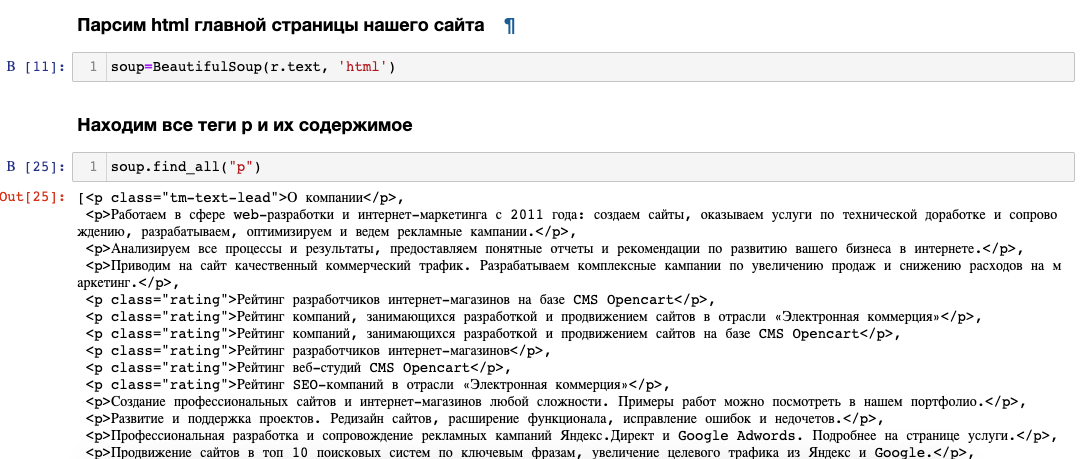
Шаг 3 - Отправляет на сервер
Робот извлекает необходимую информацию и добавляет в базу данных. База данных представляет из себя таблицу, состоящую из строк (записей) и столбцов (полей). В одном из столбцов хранится индекс - уникальное значение, например, номер или id. При создании новой структуры в базе назначается новый индекс, по которому можно осуществлять сортировку, слияние и последующий анализ.

Шаг 4 - Анализирует и ранжирует
Когда страница сайта просканирована и отправлена на сервер, в дело вступают поисковые алгоритмы – сложнейшая система оценок, в результате которых URL получает ранг и участвует в поисковой выдаче. По каким именно критериям производится оценка и дается шанс оказаться поближе к топ-10 - никто не знает, не знают даже специалисты компаний-разработчиков поисковых систем. Это коммерческая тайна.
Этими самыми алгоритмами, вернее формулировкой, что кто-то из сеошников разбирается в поисковых алгоритмах, часто спекулируют:
-
агентства говорят своим клиентам, что им доступно это тайное знание, и они знают, как «подкрутить сайт», чтобы он ворвался в топ;
-
бесчисленные обучатели всему подряд гарантируют, что они сделают из тебя SEO-специалиста, а на выходе ты будешь обладать знаниями о поисковых алгоритмах;
-
почти в каждой вакансии в требованиях к соискателю на должность поискового продвигателя обозначено знание алгоритмов.
Если имеется ввиду знание названий, которые анонсируют сами поисковики, тогда все понятно. Баден-Баден – не пиши бессмысленные тексты ради ключевых слов, Минусинск – не покупай ссылки, Арзамас – в регионах отдается приоритет региональным сайтам и т.п. Это просто осведомленность, что некоторые технологии существуют, накладывают ограничения или регламентируют что-либо. Возможно, близкими к пониманию поисковых алгоритмов могут быть специалисты по машинному обучению и нейронным сетям, но они не занимаются продвижением сайтов.
Кстати, иногда поисковики выкладывают репозитории с реальными моделями машинного обучения (модели необученные), которые используются в таинственной глобальной системе поисковых алгоритмов.
Пример:
Ссылка на GitHub с рабочим кодом алгоритма BERT от Google.
Статья об использовании этого алгоритма для SEO.
Можно попытаться понять, как устроена модель, какую функцию выполняет и попробовать провести какое-нибудь исследование. Однако «люстры в СПб» это вряд ли поможет продвинуть.
Задача SEO-специалиста, веб-мастера
Не преследую цели обесценить чьи-либо знания и успехи в продвижении сайтов, заявляя кто и чем должен заниматься. В SEO существует проблема искаженного восприятия и спекуляций, которую попытался раскрыть в первой вводной статье. В этой – рассказываю о том, как «скормить» сайт поисковику, поэтому особое значение имеют первые два пункта, перечисленные выше: запрос к страницам и получение ответа, извлечение содержимого.
Считаю, что одна из важных задач, которая стоит перед сеошником или веб-мастером - сделать так, чтобы поиск проиндексировал нужные нам страницы, а ненужные обошел стороной или исключил из своей базы.
«Ненужные» с точки зрения SEO – это дубли страниц.
Проблема дублирования
Дублирование может произойти по множеству причин.
Пример 1: страницы сайта доступны в нескольких вариантах
С www и без:
-
www.site.ru
-
site.ru
URL доступны в различных вариантах написания:
-
site.ru/page
-
site.ru/page/
-
site.ru/page.html
С http и https:
-
http://site.ru
-
https://site.ru
Могут быть и другие варианты. Решается очень просто - необходимо сделать постоянное перенаправление (301 redirect) на конечный вариант URL. Это может быть решено настройками внутри вашей CMS или непосредственно в файле дополнительной конфигурации веб-сервера, например в .htaccess.
Пример 2: так решил разработчик
Несколько раз сталкивался с ситуацией, когда один и тот же товар в интернет-магазине может иметь множество URL, но при этом контент и мета-информация будут идентичными. Например, есть крем для лица от морщин Ahava, админы вкладывают этот товар в категории, для которых он подходит: кремы для лица, кремы от морщин, страница бренда Ahava, кремы Ahava. В результате один и тот же товар доступен по адресам:
-
site.ru/catalog/kremy-dlya-lica/kartochka-tovara-ahava
-
site.ru/catalog/kremy-ot-morshin/kartochka-tovara-ahava
-
site.ru/brands/ahava/kartochka-tovara-ahava
-
site.ru/brands/ahava/kremy/kartochka-tovara-ahava
И еще может появиться сколько угодно адресов, если админы сайта начнут развивать структуру дальше.
Такое встречал на Битриксе и самописных сайтах. Сам Битрикс обвинять в непригодности для SEO нельзя, потому что эта система предоставляет большой спектр возможностей, почти как самописное решение. Просто разработчик решил не запариваться, потому что закрепить за одной карточкой один каноничный URL и осуществлять на него роутинг из любой категории чуть сложнее. Ведь все работает и так, а без ясного ТЗ результат непредсказуем.
В целом, так лучше не делать. Такой нюанс необходимо предусмотреть на этапе проектирования сайта. Если такая ситуация сложилась, ее можно решить с помощью canonical – об этом будет написано ниже.
Пример 3: get-параметры
Дубли могут быть образованы функциональными частями сайта, которые существуют для удобства пользователя, например, пагинацией, сортировками, фильтрацией (get-параметрами).
site.ru/category ? page=2 – так может выглядеть пагинация,
site.ru/category ? sort=price & order=ASC – сортировка по возрастанию цены,
site.ru/category ? limit=30 – ограничение по количество выводимого контент,
site.ru/category ? fliter=param1 & param2… -фильтрация по выбранным параметрам.
Или все и сразу: site.ru/category ? fliter=param1 & param2… & limit=30 & sort=price & order=ASC & page=2
С помощью get-параметров на сервер передается запрос о выводе соответствующей информации, которая указана в URL. В результате на странице меняется контент, появляется новый URL, но важная для поисковиков метаинформация остается неизменной. Таким образом может быть проиндексировано неограниченное количество дублей.
Пример - страница без параметрова и та же страница с параметрами:


Отмечу, что get-параметры могут быть написаны без специальных символов «?, & и др.», например, фильтр в категории торшеры: «https://site.ru/torshery/filter/tsvet-plafona-abazhura,бежевый». Происходит все то же самое – образуется новый URL, и дублируются мета-теги.
В чем проблема дублей для поиска
Схематично добавление в поисковую базу дублей может выглядеть так:

После добавления URL и всех извлеченных параметров поиску необходимо «решить» какую страницу в каком случае показывать в выдаче. Когда проиндексированы разные URL с одинаковыми мета-тегами на решение у поисковой машины может потребоваться больше ресурсов, что точно не будет способствовать качественному продвижению, сайт просто начнет понижаться в ранге.
Уникальные тексты
Важно упомянуть про текстовый контент. Тут все просто – тексты строго должны быть уникальными для каждой страницы. Может быть вариант, что у вас интернет-магазин со множеством очень похожих товаров, например, которые одинаковые по своим свойствам, но разные по размеру или цвету, и описания этих товаров будут почти идентичными. Это нормально, главное, чтобы не 100% идентичные как в примере №2 (см. Причины появления дублей).
Вывод про дубли
Перед отправкой вашего сайта на сканирование поисковикам убедитесь:
-
что URL всех страниц доступны только в одном варианте,
-
постарайтесь избежать архитектурных недоработок, которые описаны во втором примере,
-
узнайте, какие get-параметры будут использоваться,
-
убедитесь, что на всех страницах используется уникальный текстовый контент или почти уникальный как в случае с похожими товарами в больших каталогах.
Основная задача – проиндексировать сайт так, чтобы в поисковой базе был 1 уникальный URL с уникальными мета-тегами Title, Description и уникальным текстовым описанием.
Какими средствами управлять сканированием и индексированием
Простая настройка Яндекс Вебмастера и Google Search Console
Яндекс Вебмастер и Google Search Console - официальные сервисы, без которых невозможно понять, как протекает индексирование вашего сайта. Также в эти консоли (а через них на вашу почту) приходят сообщения о всех изменениях, критичных и даже фатальных ошибках, о которых очень важно узнавать как можно оперативнее.
Яндекс Вебмастер
Установите консоль любым предложенным способом. Инструкция.
Укажите регион и страницу контактов в разделе «Информация о сайте», «Региональность»:

Свяжите Вебмастер с Метрикой. Без этого этапа сайт уже начнет индексироваться, но все равно лучше установить связь. Инструкция.
Google Search Console
Официальная инструкция по установке.
При добавлении сайта выбирайте «Ресурс с префиксом в URL»:
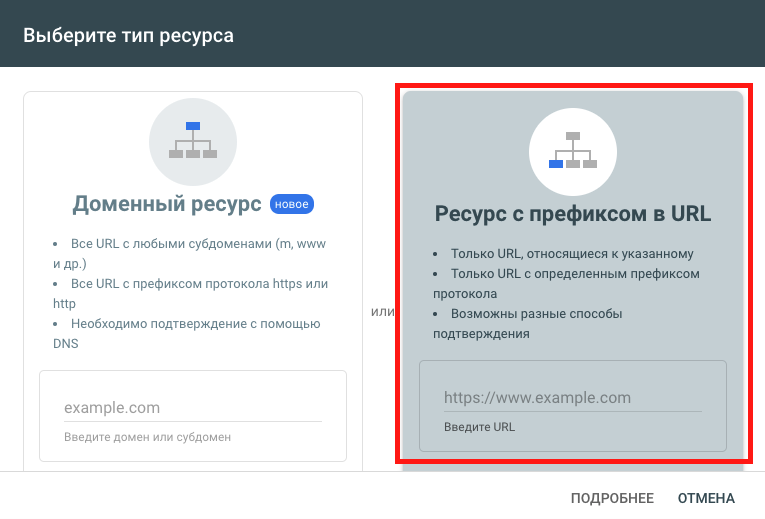
Далее нужно пройти верификацию, похожим образом как при регистрации Яндекс Вебмастера. Если у вас установлен Google Tag Manager, регистрация будет пройдена автоматически.
Установите связь Google Search Console с Google Analytics. Инструкция.
Вывод про сервисы поисковых систем
После прохождения перечисленных шагов на ваш сайт придут роботы и начнут сканирование. В сервисы начнет поступать статистика, которая в будущем будет являться основой для анализа качества индексирования. В этих консолях есть интересные отчеты, которые полезно использовать для продвижения, об этом не будет затронуто в этой статье.
Robots.txt
Это текстовый файлик, в котором перечислены директивы для поисковых роботов. Принято считать, что к нему обращается робот, прежде чем начать обход сайта. Написать запрещающую инструкцию – хороший способ сообщить поисковой системе, какие URL не обходить, и тем самым предупредить индексирование дублей.
Статьи на тему создания корректного роботса:
Документация Google по созданию.
Исчерпывающая статья с картинками от NetPeak.
Отличная статья от SEO-эксперта Devaka. Обратите внимание для чего Devaka рекомендует использовать robots и для чего не рекомендует.
Может казаться, что настройка роботса дело сложное, непонятное и немного пугающее – роботы как набегут, как начнут индексировать все подряд, и все – карачун тебе.

Переживать точно не стоит, если вдруг вы не запретите какой-либо параметр, и из-за этого в поисковую базу попадут дубли, то при обычной проверке эти дубли можно будет выявить и удалить.
Очень важно случайно не закрыть целиком работающий сайт с накопленными SEO-результатами. Вот так:
User-agent: *
Disallow: /Когда такое может произойти? Когда у вас есть действующий сайт, а на тестовом домене параллельно ведется разработка новой версии сайта – обновляется дизайн, код или добавляется новый функционал, что угодно в общем. Разработчики закрывают тестовый домен от индексирования, потому что все его страницы являются дублями и могут попасть в поиск. Вот так:
Когда разработчики закончат работу и приступят к замене старой версии сайта на новую, с тестового домена может быть скопирован robots.txt, и тогда уже основной домен будет запрещен к сканированию. Правильно ли с точки зрения разработчика такое копирование и замена важных файлов? Конечно нет! Но такое случается.
Когда что-либо обновляется и дорабатывается на вашем сайте, проверьте robots после завершения всех работ.
Случай из жизни. Однажды мы продвигали сайт, а разработчики делали новую верстку на тестовом домене. Сайт был обновлен вместе с robots.txt, возникла ситуация, описанная выше. Одновременно с этим клиент заказал SEO-аудит, и приглашенные на аудит специалисты сразу сообщили о роботсе, который запрещает сканировать весь сайт. Невозможно передать реакцию клиента, исход понятен – он от нас ушел. А мы себя чувствовали как-то так:

С тех пор мы внимательно проверяем все после любых обновлений сайтов клиентов, а каждую неделю проводим плановый аудит.
Запрет сканирования параметров
Для сайта, на котором не предусмотрено динамическое изменение контента с помощью get-параметров достаточно прописать набор, запрещающих директив для всех поисковых систем.
Например, набор правил из «стокового» роботса Joomla c некоторыми дополнениями:

Если запрещать нечего достаточно просто указать User-agent и карту сайта:
User-agent: *
Sitemap: https://site.ru/sitemap.xmlЕсли у вас на сайте предусмотрено изменение контента с помощью параметров – сортировка, фильтрация или какая-либо другая логика, простого запрета через Disallow скорее всего может быть недостаточно.
По моим наблюдениям (и не только моим, можно найти инфу на форумах и в комментах к статьям) поисковые роботы, особенно Google, рассматривают запрещающие директивы как рекомендацию, а не требование и все равно могут проиндексировать любой адрес.
Пример аудита:
Параметр запрещен в роботсе:
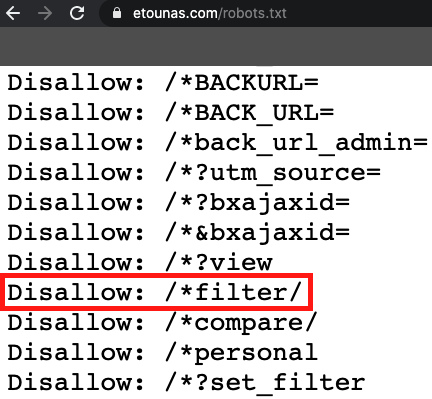
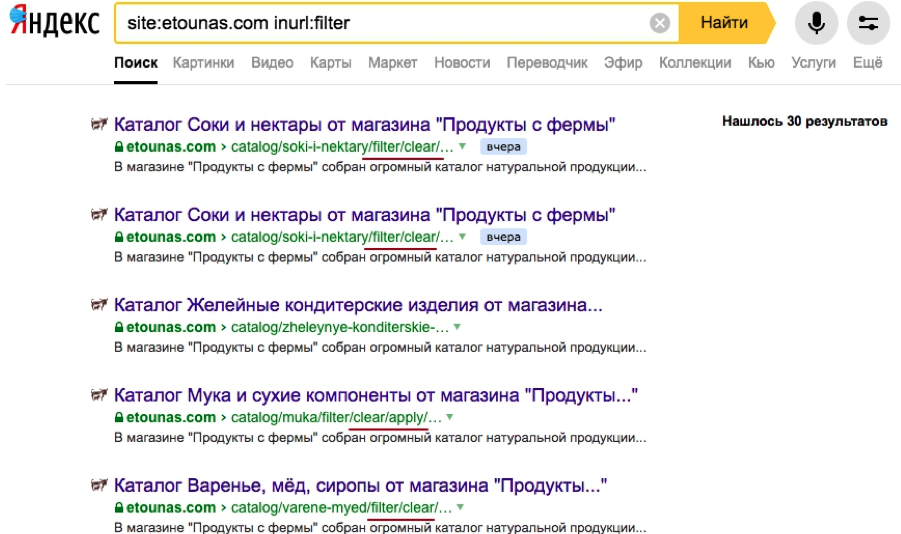
Почему индексируются адреса, запрещенные в robots.txt – большая загадка. Может быть, директивы игнорируются или адреса берутся из непонятных источников, например из ссылок на каких-нибудь сайтах. Даже поговаривают, что поиск может собирать URL прям из адресной строки браузера, ведь и Яндекс и Google производят собственные браузеры. Но это темный лес, и пруфов нет. Наша задача – бороться с дублями всеми возможными способами.
Для Гугла и Яндекса есть работающие решения.
Яндекс: обработка параметров с помощью Clean-param
Параметром является все, что реализовано через специальные символы «?» и «=». Если параметр работает без этих символов, а вы укажете его в Clean-param, он не будет обработан.
https://site.ru/page?param=
Clean-param - хороший инструмент, который поможет предотвратить сканирование дублей с параметрами, но работает только для Яндекса.
Пример:
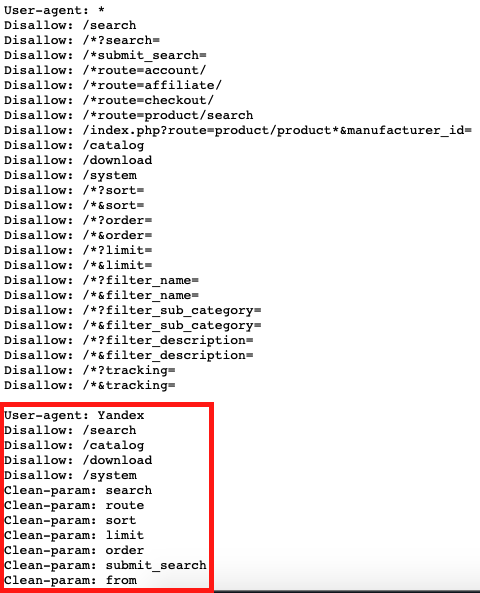
На скриншоте пример инструкции для всех поисковиков и отдельная для Яндекса. В Clean-param нужно указать название параметра без специальных символов. Для параметра не нужно дублировать запрет через Disallow.
Google: обработка параметров с помощью Search Console
Параметром также является все, что реализовано через специальные символы «?» и «=».
В сервисе Google Search Console предусмотрен инструмент, который помогает сообщить поисковику название параметра и его назначение. Такой своеобразный встроенный robots с человекопонятным интерфейсом – понятнее, чем Clean-param.
Перейдите в раздел «Прежние инструменты и отчеты», «Параметры URL»:
Чтобы добавить новый параметр, нажмите на кнопку «Добавление параметра»:

-
Впишите название параметра.
-
Укажите, что он влияет на содержимое страницы.
-
Как именно влияет.
-
Как его необходимо обработать.
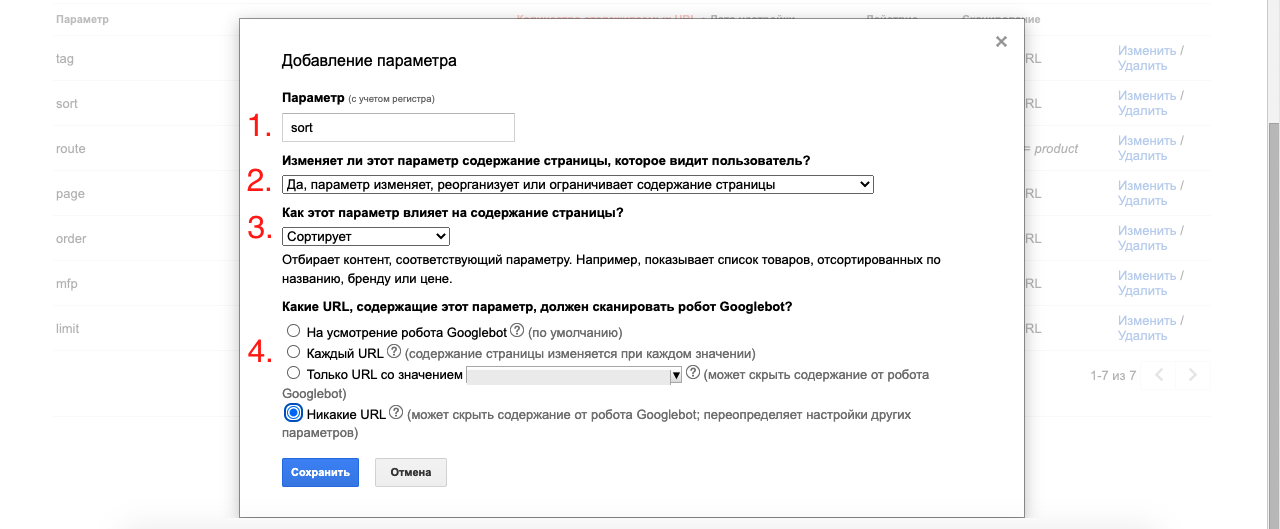
Можно указать параметр с определенным значением. В некоторых случаях это удобно.
Например, параметр route только со значением product - /index.php?route=product/product&product_id=2344:
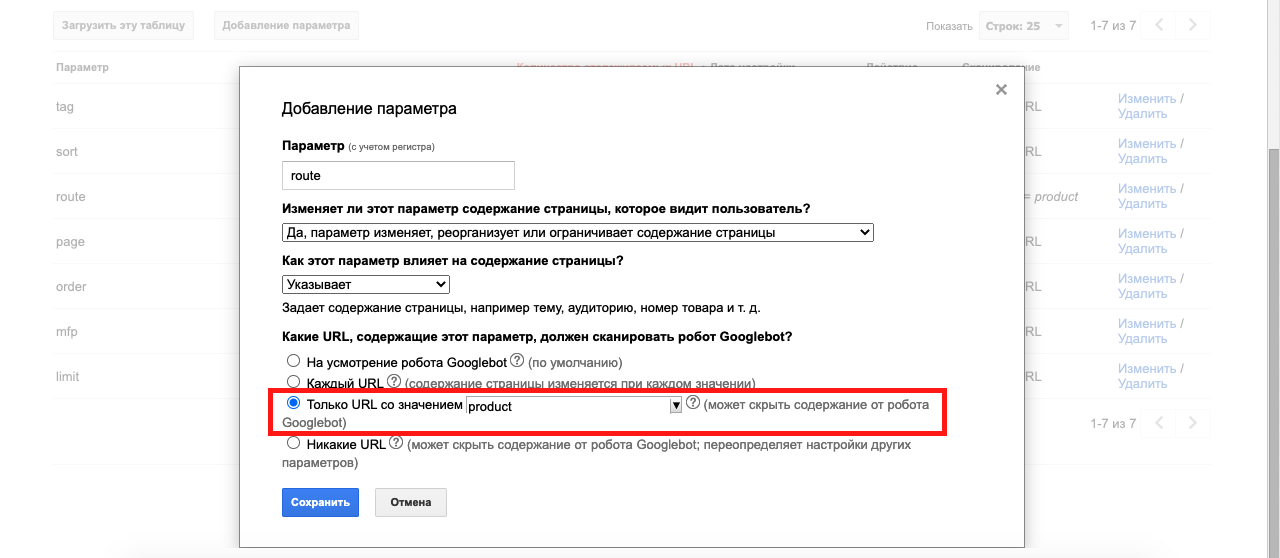
UPD: в 2022 году инструмент был удален :(
Что еще могу добавить о robots.txt
Разные директивы для разных систем
Нередко во время аудитов я вижу раздутый роботс, где для разных систем приводится один и тот же набор правил. Это никак не вредит, но не имеет смысла, если реализуется без каких-либо причин.
Пример, когда один и тот же набор правил прописан для разных роботов:
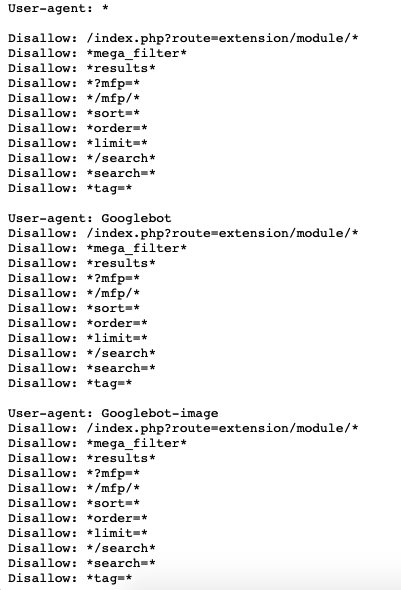
На этом сайте работает Google Merchant. Для его функционирования необходимо указать Googlebot и Googlebot-image. Документация.

Если просто скопипастить из документации этот кусок:
User-agent: Googlebot
Disallow:
User-agent: Googlebot-image
Disallow:и добавить ниже набора запрещающих директив, который прописан для всех систем, Googlebot и Googlebot-image будет видеть отсутствие запретов и будет сканировать все.
Пример проверки.
В общем списке директив для всех систем запрещена сортировка. Проверяю URL, содержащий этот параметр. Валидатор Гугла говорит, что адрес доступен для сканирования:
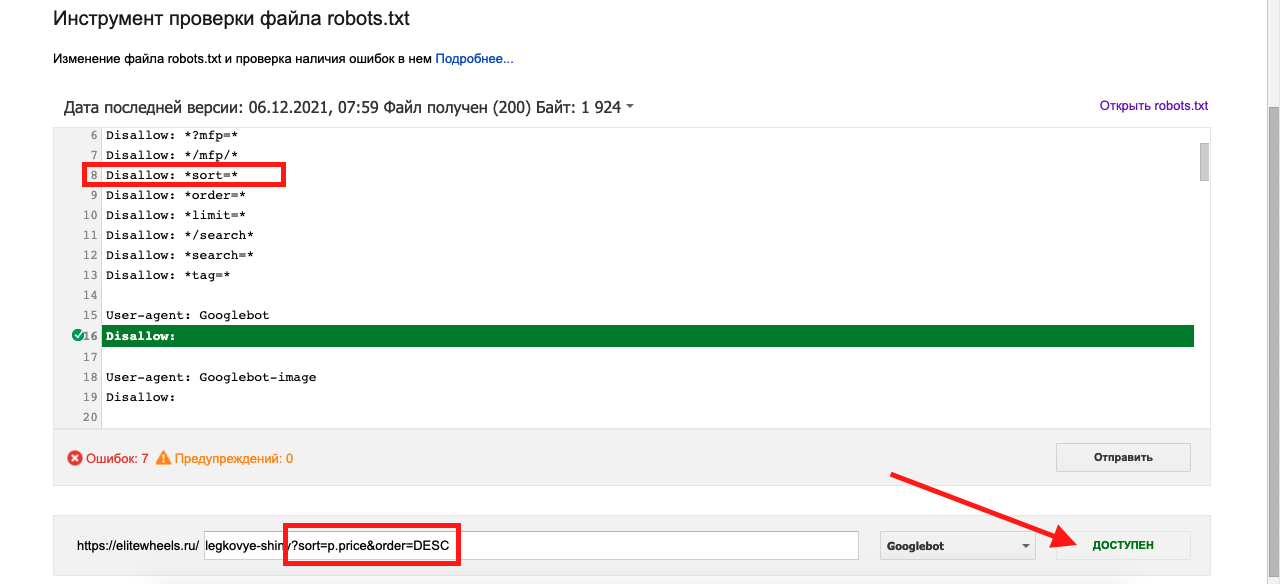
Поэтому нужно продублировать все директивы для Googlebot и Googlebot-image.
На скриншоте можно заметить 7 ошибок – так воспринимается Clean-param, который прописан ниже и не попал на скриншот. Это нормальная реакция Гугла на инородную команду :)
Еще примеры директив для разных роботов.
Пример 1: полностью запрещен обход сайта для большого перечня краулеров, которые создавали нагрузку для медленно работающего сайта.

Пример 2: На региональных поддоменах генерируется правило, которое запрещает Google сканирование. На основном домене этой директивы нет.

Директива Allow
Никогда ее не использовал и смысла в этом не вижу, потому что все разрешено, что не запрещено. Разрешать отдельно скрипты и медиа – тоже не оказывает влияния на что-либо.
Пример:
User-agent: *
Allow: /
User-agent: *
Allow: *.css
Allow: *.js
Allow: *.gifHost можно не указывать
Когда-то эта директива нужна была Яндексу, но потом ее упразднили.
После внесения изменений проверяйте валидатором
Когда вы меняете robots - удаляете директивы или вносите новые, убедитесь, что поисковые системы правильно интерпретируют инструкции.
Яндекс Вебмастер - «Инструменты», Анализ robots.txt:

Google Search Console - Инструкция и ссылка на инструмент:

Не трогайте ничего, если все работает хорошо
Если у вас есть функционирующий сайт, из органической выдачи вы получаете трафик, нет подозрений, что в поисковой базе есть дубли, но вы зашли в robots и увидели всю бессмыслицу, которую я перечислил – одинаковые правила для разных систем, Allow, Host или запрещенные get-параметры, которых у вас нет на сайте (они там оказались, потому что конфигурация robots стоит по умолчанию для вашей CMS), то ничего не трогайте. Одно из самых важных правил в SEO – не менять, что хорошо работает, тем более что robots не содержит магии, которая помогает продвигать сайт, это просто небольшая инструкция для роботов.
Canonical
Что это
Так называется атрибут тега < link >.
Полная конструкция записывается так:
<link rel=”canonical” href=”https://site.ru/” />.
Тег < link > устанавливает связь текущей страницы с другим документом, но при этом не создает ссылку, т.е. не перелинковывает эту страницу с другой как тег < a >.
Атрибут rel=”canonical” сообщает, что в теге указана каноничная ссылка.
Атрибут href=”https://site.ru/” указывает, какая именно ссылка.
Зачем нужен canonical
Canonical – гибкое средство, которое поможет бороться с дублями страниц.
Google называет это «Объединение повторяющихся URL».
Как действует робот
Робот осуществляет запрос к какому-либо URL, получает весь код страницы, парсит, «видит» тег < link >, атрибуты canonical и href с указанной ссылкой. Canonical сообщает роботу, что сканированный контент на странице не является уникальным, а уникальный или каноничный находится по адресу, который указан в атрибуте href.
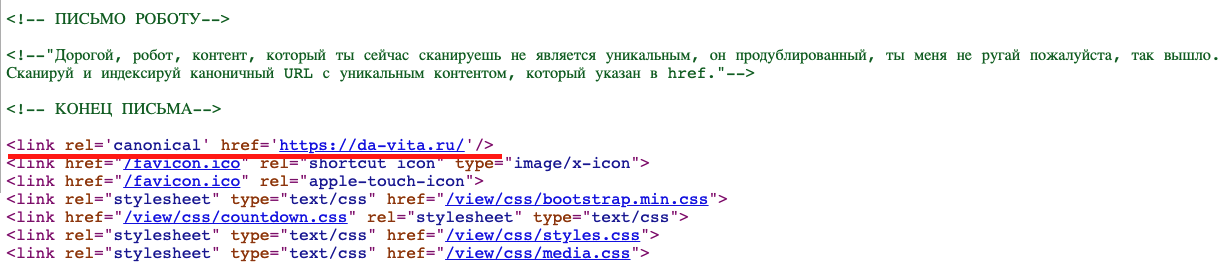
Происходит своего рода переадресация робота на нужный адрес без переадресации для пользователя, как это бывает, когда URL имеет ответ 301.
При этом индексируется каноничный URL и неканоничный, где был обнаружен атрибут. То есть в поисковую базу попадает сам дубль, но в этом случае он легализован, поиск знает, что это дубль и его не нужно ранжировать. Со временем дубль будет удален с пометкой «Неканоничный».
Фактически canonical – это такой костыль, который внедряется, когда стало понятно, что сайт спроектирован так, что не получится избежать попадания дублей в базу поисковых систем.
Как реализовать canonical
Тег < link > с атрибутом canonical должен быть расположен строго в секции < head >.
Каноничная ссылка должна быть абсолютной, т.е. содержать протокол и домен.
Каноничная ссылка должна давать ответ 200. Не должно быть перенаправления 3хх, или битой ссылки 4хх.
Адрес не должен быть запрещен в robots.txt.
Каноничная ссылка может быть только одна, такая ситуация недопустима:

В каких ситуациях использовать Canonical
Дубли товаров в интернет-магазине
В разделе про возможные варианты возникновения дублей во втором примере приведена ситуация, когда из-за непродуманной архитектуры сайта один и тот же товар в интернет-магазине может иметь множество URL, но одинаковое содержание.
„Например, есть крем для лица от морщин Ahava, админы вкладывают этот товар в категории, для которых он подходит, т.е. кремы для лица, кремы от морщин, страница бренда Ahava, кремы Ahava. В результате один и тот же товар доступен по адресам:
- site.ru/catalog/kremy-dlya-lica/kartochka-tovara-ahava
- site.ru/catalog/kremy-ot-morshin/kartochka-tovara-ahava
- site.ru/brands/ahava/kartochka-tovara-ahava
- site.ru/brands/ahava/kremy/kartochka-tovara-ahava“
Разработчику необходимо написать решение, при котором будут определяться все дубли одного и того же товара и для каждого URL с помощью конструкции < link rel=”canonical” href=”абсолютный адрес” / > будет присвоен каноничный URL, выбранный по какому-нибудь критерию.
Примеры разных URL, но абсолютно одинаковых товаров:
https://da-vita.ru/catalog/kremi-ot-morshchin/jemchujnii_nochnoi_krem_protiv_morshchin.html
https://da-vita.ru/catalog/lico/jemchujnii_nochnoi_krem_protiv_morshchin.html
При парсинге любого из адресов робот обнаружит каноничный адрес:

Есть вариант, при котором, помимо вложения товаров в релевантные категории, например https://site.ru/catalog/kategoriya-1 и другие, товар нужно вложить в общую страницу каталога, например https://site.ru/catalog/ и указать ее в качестве каноничной.
Или в качестве каноничной указать релевантную категорию, в которую вложены товары, в режиме «Показать все товары», например https://site.ru/catalog/kategoriya-1/view-all/.
Эти варианты логичны и прекрасны, но только в том случае, если товаров мало. Если речь идет о тысячах и десятках тысяч страниц, такая страница будет грузиться очень долго, и никакой робот не будет тратить ресурсы на ожидание.
Защита от попадания в индекс get-параметров
Clean-param и инструмент «Параметры URL» в Google Search Console способны решить большинство проблем с индексированием дубликатов страниц, которые сгенерированы параметрами. Однако разработчики могут решить реализовать динамическое изменение контента с помощью параметров, которые не содержат специальные символы «?» и «=».
Например, что-нибудь вроде https://site.ru/page/filter/nabor-parametrov. На такой случай может пригодится canonical.
Для классического варианта реализации параметров, наряду со вместе со всеми нужными директивами в robot.txt, можно также сделать canonical – чтобы прям наверняка ничего не залетело в поисковую базу.

Самый простой вариант решения для разработчика – сделать так, чтобы каждая страница ссылалась сама на себя без параметров. Это абсолютно нормальный вариант решения, который понятен поиску. Такой вариант не является нелогичным.
Пример:
Робот может просканировать URL с результатами фильтрации следующего вида:
https://da-vita.ru/catalog/lico.html?price_min=2660&price_max=5560&manufacture=27&uhod-za-kojei-lica=23
При парсинге он обнаружит каноничный адрес:

Сразу необходимо учесть вариант, когда на сайте используются сразу два приведенных варианта – в неканоничном адресе товара существуют некие параметры. То есть на сайте присутствуют дубликаты товаров с указанием каноничного адреса, и canonical для get-параметров. Такой вариант мало вероятен, но мало ли! Вдруг там окажутся некие параметры вроде utm-меток или параметры какой-либо системы аналитики, например roistat.
Пример URL, который приведен в первом варианте использования canonical, но уже с добавленными параметрами:
https://da-vita.ru/catalog/lico/jemchujnii_nochnoi_krem_protiv_morshchin.html?utm_medium=email
Canonical указывает на каноничный адрес товара, выбранный разработчиком:

Полное дублирование текстового контента
Canonical нужно использовать, когда на разных URL по каким-то причинам дублируется контент.
Пример 1
На сайте нашего клиента есть общая страница с адресами всех розничных магазинов https://da-vita.ru/shops/.
На эту страницу приходит трафик по запросам вроде «Адреса магазинов DaVita». Каждая карточка магазина представляет из себя отдельную страницу (как карточка товара) с подробным описанием. На каждую карточку розничной точки приходит трафик по более подробным поисковым запросам, например «Магазин DaVita на Таганской». Карточки магазинов вложены в общую страницу с магазинами, например https://da-vita.ru/shops/firmennii_magazin_kosmetiki_mertvogo_morya_na_taganskoi.html.
В интерфейсе присутствуют кнопки фильтрации по городам – Москва и Санкт-Петербург.
Каждый фильтр имеет свой адрес:
https://da-vita.ru/shops/msk-shops/
https://da-vita.ru/shops/spb-shops/
На странице каждого города выводятся соответствующие карточки магазинов. В итоге возникает проблема идентичная дублированию карточек товаров из-за разной вложенности (см. раздел про дубли, пример №2) – дублируются карточки магазинов.
Пример:
https://da-vita.ru/shops/msk-shops/firmennii_magazin_kosmetiki_mertvogo_morya_na_taganskoi.html.
В качестве каноничной страницы указан адрес карточки магазина со вложенностью в общую страницу адресов магазинов:

Пример 2
На сайте https://da-vita.ru/ реализована система создания региональных поддоменов для привлечения трафика из регионов РФ. Пример регионального сайта https://krasnoyarsk.da-vita.ru/.
Каждый региональный интернет-магазин формируется виртуально, т.е. фактически не имеет отдельного места на сервере и отдельной базы данных. Все настройки и названия городов в мета-тегах и текстах заменяются автоматически, таким образом каждый региональный сайт имеет свои уникальные URL и уникальный текстовый и мета-контент в каталоге. Но da-vita.ru получает трафик из органического поиска по информационных запросам на страницы блога, faq и отзывов – этот контент не меняется. На каждом региональном домене образуются информационные страницы с полным дублированием текстового контента:
https://da-vita.ru/beauty-blog/antioksidanti-v-kosmetike.html
https://krasnoyarsk.da-vita.ru/beauty-blog/antioksidanti-v-kosmetike.html
В этом случае с помощью canonical, тоже можно сообщить, что робот сейчас просматривает дубликат, и что основной контент указан в качестве канонической ссылки:

Вывод про canonical
Canonical – довольно гибкое средство для предотвращения попадания дубликатов страниц в базу поисковых систем. Технически они туда попадут, но впоследствии будут удалены с пометкой «Неканоническая страница».
Практика показывает, что canonical подходит:
-
для сайтов, где из-за разной вложенности в категории дублируются карточки товаров,
-
для предотвращения попадания дублей, которые сгенерированы get-параметрами,
-
при дублировании текстового контента.
Sitemap
Карта сайта – еще один способ повлиять на индексирование сайта. С ее помощью мы передаем поиску список страниц, который необходимо индексировать.
Описание стандарта. С помощью этой инструкции легко составить любую карту.
Справка Google, раскрывающая назначение карты сайта.
Исчерпывающие статьи с картинками:
В основном сайты, с которыми мне (да и не только мне, почти всем сеошникам) приходится работать сделаны на CMS. Создание sitemap решается установкой соответствующего модуля, который генерирует ее. Разработчикам самописных решений тоже не составит труда сделать sitemap, достаточно руководствоваться официальной справкой и приведенными статьями от экспертов seo-отрасли.
В карте сайта все ссылки должны давать ответ 200. Следите, чтобы в карту не попали битые ссылки (404) или редиректы (301 и другие).
Все ссылки должны быть каноническими. Этому необходимо уделить пристальное внимание, если у вас существует проблема дублирования, вызванная вложенностью карточек в различные категории с формированием нового URL (см. Раздел про дублирование, Пример №2).
Sitemap может иметь любой адрес.
Например:
-
https://da-vita.ru/sitemap.xml
-
https://frutoss.ru/fx-sitemap
-
https://the-koleso.ru/index.php?route=feed/google_sitemap&page=0&limit=2000
Лимит адресов для одной карты составляет 50 000 url. Несмотря на допустимый лимит, рекомендую не создавать sitemap такого объема. Большая карта может превышать допустимый размер 50 Мб или просто медленно загружаться – это не приветствуется роботами. Если у вас 50 тысяч страниц или больше, разделите весь объем на множество частей (т.е. на множество sitemap) и создайте карту, которая будет ссылаться на карты – типа такой каталог всех sitemap.
Справка от Google по мультикартам.
Пример такой карты:
https://the-koleso.ru/index.php?route=feed/google_sitemap&multi=&limit=2000
Когда вы создали карту сайта, сообщите о ней в robots.txt:
User-agent: *
Sitemap: https://site.ru/sitemap.xml
Отправьте карту на сканирование через консоль Яндекс Вебмастера и Google Search Console:

По моим наблюдениям поисковые системы чувствительны к скорости загрузки карты сайта.
Существуют решения, когда при загрузке URL карты, данные формируются «на лету», т.е. sitemap создается, выгружаясь из базы данных, в момент обращения. На некоторых CMS реализуется с помощью соответствующих плагинов.
С одной стороны, удобное решение, которое позволяет не размещать кучу xml-файлов на сервере, а данные выгружаются всегда самые актуальные, т.к. они формируются прямиком из базы данных, а не генерируются по расписанию, например раз в сутки. Это может быть актуально, когда остатки в каталоге обновляются очень часто.
С другой – если не оптимизированы запросы к базе данных, файл может формироваться очень долго, а робот не собирается ждать больше какого-то определенного времени. Я говорю именно о скорости ответа на запрос робота, а не скорости рендеринга карты в браузере, когда вы хотите посмотреть на нее глазами.
Пример валидации карты с медленной загрузкой:

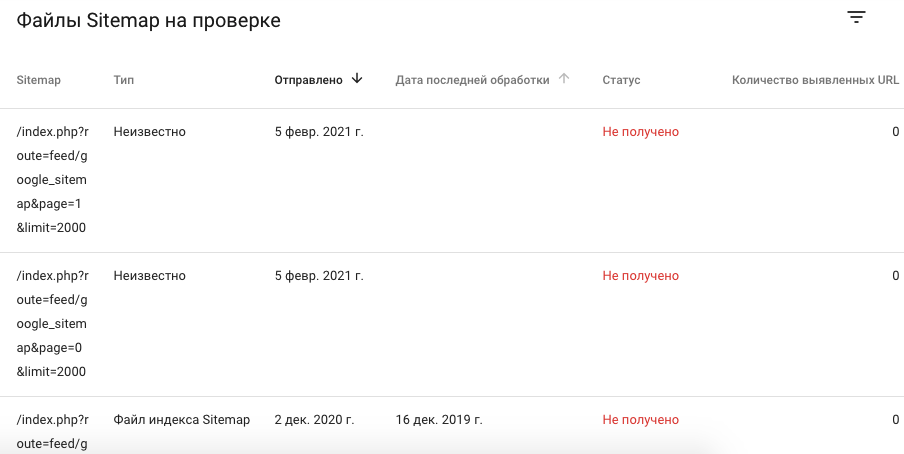
Картину с такими статусами можно будет наблюдать долго - может быть все карты буду просканированы со временем, а может быть никогда.
Будет ли сайт индексироваться в таком случае? Конечно будет – робот будет ходить непосредственно по ссылкам на сайте. Также можно отправлять страницы на переобход - в Яндексе есть соответствующая форма «Переобход страниц», для Google отправить страницы можно используя Indexing API. Однако, если sitemap загружается долго и не индексируется роботом, можно утверждать, что карта сайта не выполняет свои функции. Эту проблему можно решить через оптимизацию скорости выгрузки. Также можно вернуться к варианту хранения статических файлов на сервере, которые формируются по заданному расписанию.
Большие карты робот точно может сканировать, инфа 100%:
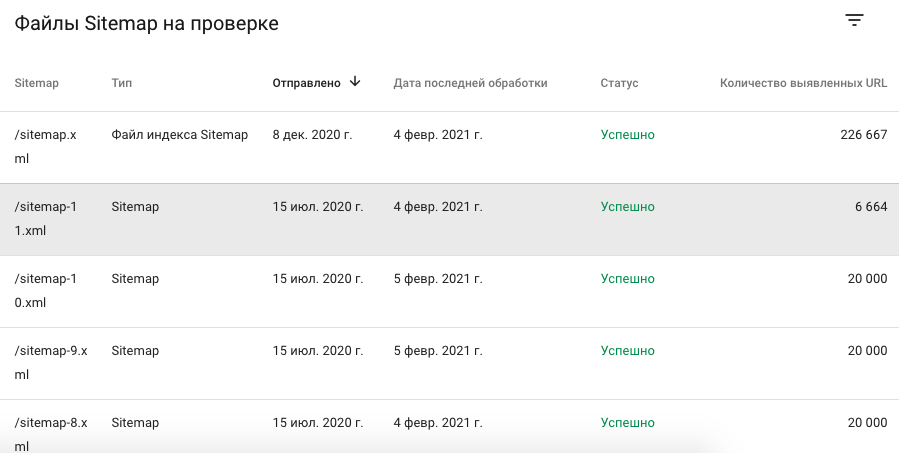
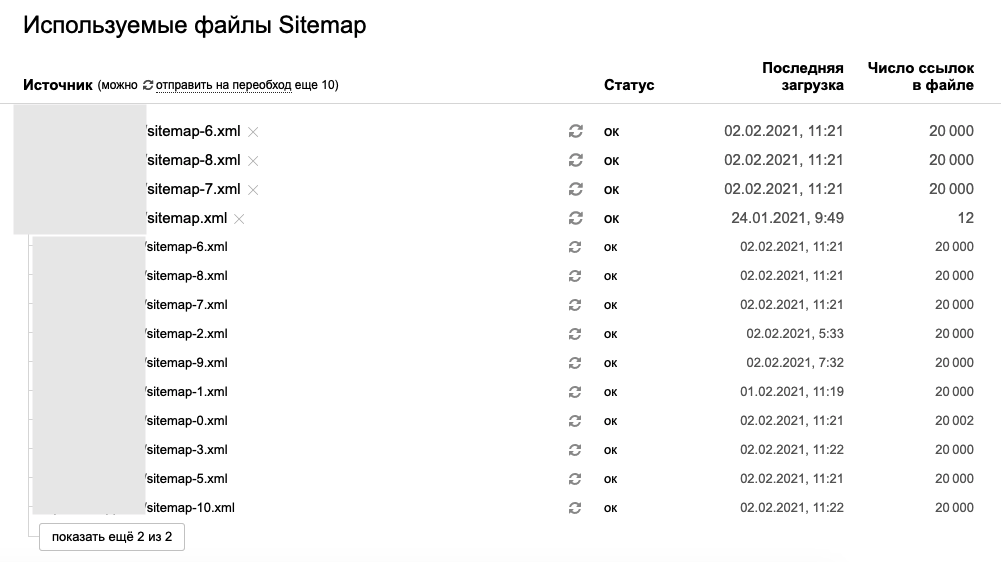
Уточню, что описанная проблема не касается небольших сайтов – поиск без проблем просканирует небольшую карту и все ссылки на сайте.
Что делать с пагинацией
Отдельно в разделе про средства, влияющие на сканирование и индексирование, хочу упомянуть про постраничную навигацию.
Пагинация является get-параметром, который выводит на страницу ограниченное количество карточек для удобства навигации по каталогу товаров или содержанию в блогах. По страницам кроме пользователей будут «ходить» поисковые роботы, сканировать весь контент, который на них содержится и переходить по ссылкам в товары или посты.
Пагинация имеет значение для интернет-магазинов и блогов, особенно если контента много, и существует цель привлечь трафик из поиска на максимально возможное количество страниц. Если не создавать преград для роботов, свободный обход может ускорить индексирование.
Вывод карточек на страницы происходит автоматически в установленном в настройках сайта количестве. При переключении страниц возникает новый уникальный URL, обновляется контент, но не меняется важная для поиска метаинформация – образуются дубли.
Например, мы хотим продвигать категорию «Соль Мертвого моря» в интернет-магазине косметики. Категория разбита на несколько страниц. В результате мы имеем несколько различных URL с одинаковой метаинформацией:


Как поисковику решить, какую страницу показать в выдаче по запросу пользователя? Чтобы избежать дублирования и понижения ранга, мы должны оставить один вариант, на который хотим сосредоточить трафик, и логично, что этим вариантом будет первая страница каталога без параметров.
Для ограничения индексирования в арсенале у нас есть целых два инструмента – robots.txt и canonical. Однако, если мы запретим параметр в роботсе, страницы не будут сканироваться.
Canonical тоже препятствует индексированию страниц пагинации.
„Mistake 1: rel=canonical to the first page of a paginated series
Using rel=canonical in this instance would result in the content on pages 2 and beyond not being indexed at all.”
Выше я писал, что неканонические страницы сначала добавляются в поисковую базу, а потом со временем удаляются. По моим наблюдениям, в случае с размещением canonical на пагинации, эти страницы даже не добавляются в базу (пруфов нет).
Однако Яндекс как раз-таки советует в качестве каноничной указывать первую страницу каталога:
„советую настраивать атрибут rel="canonical" тега < link > на подобных страницах и делать страницы второй, третьей и дальнейшей нумерации неканоническими, а в качестве канонического (главного) адреса указывать первую страницу каталога, только она будет участвовать в результатах поиска.”
Я следую рекомендации Google и не использую canonical на пагинации. Мне кажется это логичным, потому что canonical существует для обозначения дублированного контента. В случае с пагинацией на каждой странице выгружается уникальный контент, и canonical здесь неуместен. К тому же, для улучшения сканирования нам необходимо не препятствовать роботу обходить все страницы.
Но как быть с дублирующимися мета-тегами?
Существует интересный способ, при котором запрещается индексирование, но не запрещается обход страниц.
Реализуется с помощью мета-тега «robots»:
<meta name=”robots” content=”noindex, follow” />
Для реализации такого метода необходимо разместить мета-тег на всех страницах пагинации (кроме первой):

Несколько лет я практиковал этот метод, но наблюдения за состоянием поисковой базы на многих проектах показали, что он работает не так как хотелось бы, т.е. иногда пагинация не индексируется, а все карточки попадают в базу без проблем, а иногда пагинация с одинаковыми мета-тегами попадает в поиск в полном объеме.
Что же все-таки делать с пагинацией
Рекомендую сделать так, чтобы на каждой странице пагинации (кроме первой без параметров) в мета-теги Title и Description подставлялся номер страницы:

В результате вы получите беспрепятственный обход роботов по всему каталогу товаров или статей. Каждая страница пагинации будет проиндексирована, но уже с разными мета-тегами, а при продвижении всей категории трафик будет сосредоточен на первой странице – поисковик достаточно умен, чтобы распознать первую страницу и ранжировать только ее.
Рекомендую подробный доклад на эту тему от эксперта Devaka от 2015 года – сама идея такого подхода не устаревает по сей день. Однако в докладе есть неактуальный пункт:
атрибуты rel="next" rel="prev, которые раньше существовали для обозначения пагинации, больше не поддерживаются Google (Яндекс никогда не требовал их наличие).
Но эти атрибуты можно не убирать, т.к. они соответствуют стандарту W3C и могут использоваться роботами других систем или браузерами.
В вебинаре есть упоминание об инструменте в Google Search Console, с помощью которого можно указать любую часть URL, сообщить для чего эта часть нужна и что с ней делать – такой своеобразный robots в интерфейсе консоли (об этом инструменте упоминается в разделе про robots.txt).
Перейдите в раздел «Прежние инструменты и отчеты», «Параметры URL»:
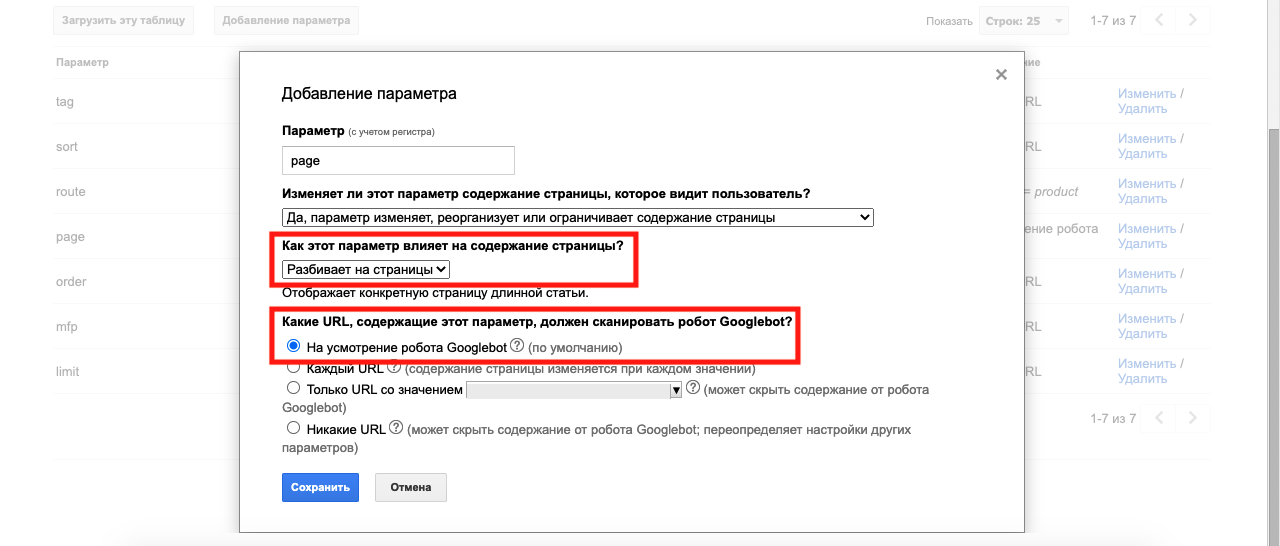
Чтобы добавить для обработки пагинацию, нажмите на кнопку «Добавление параметра»:
В качестве способа обработки пагинации я обычно выбираю «На усмотрение робота Googlebot»:
UPD: в 2022 году инструмент был удален :(
Дополнение по работе с пагинацией
Для продвижения категорий магазинов часто (особенно раньше) используют тексты. Сделайте так, чтобы текст был только на первой странице, а на всех страницах пагинации отсутствовал.
Иногда существует полный дубликат первой страницы. Например, он может выглядеть так:
-
https://site.ru/kategoriya
-
https://site.ru/kategoriya?page=1
Это решается полным склеиванием, то есть постоянной переадресацией 301.
Или можно реализовать canonical только на этой странице, на остальных страницах пагинации его быть не должно:

Средства, не влияющие напрямую на индексирование и сканирование, но имеющие значение
Микроразметка
Микроразметкой называют особый формат данных, который размещают в коде страницы для ускоренной передачи информации о ее содержимом.
Shema.org
Определение от Яндекса:
„Schema.org – это стандарт семантической разметки данных в сети, объявленный поисковыми системами Google, Bing и Yahoo! летом 2011 года. Цель семантической разметки – сделать интернет более понятным, структурированным и облегчить поисковым системам и специальным программам извлечение и обработку информации для удобного её представления в результатах поиска.“
Варианты реализации
Вариант 1 - Microdata
Реализуется с помощью html-тегов – этот способ называется Microdata.
Например, на сайте есть товарная категория, она сверстана каким-то определенным образом. Для разметки необходимых областей (фото, цена, бренд) необходимо подставить дополнительные html-теги.
Пример из документации:
Исходный вариант:
<div>
<!-- http://multivarki.ru?filters%5Bprice%5D%5BLTE%5D=39600 -->
<span>315</span>
<div>
<img alt="Photo of product" src="http://img01.multivarki.ru.ru/c9/f1/a5fe6642-18d0-47ad-b038-6fca20f1c923.jpeg" />
<a href="http://multivarki.ru/brand_502/">
<span>BRAND 502</span>
</a>
<div>
<span>4399 р.</span>
</div>...
<div>
...
</div>
</div>
</div>Вариант с Microdata:
<div itemscope itemtype="http://schema.org/ItemList">
<link itemprop="url" href="http://multivarki.ru?filters%5Bprice%5D%5BLTE%5D=39600" />
<span itemprop="numberOfItems">315</span>
<div itemprop="itemListElement" itemscope itemtype="http://schema.org/Product">
<img alt="Photo of product" itemprop="image"
src="http://img01.multivarki.ru.ru/c9/f1/a5fe6642-18d0-47ad-b038-6fca20f1c923.jpeg" />
<a itemprop="url" href="http://multivarki.ru/brand_502/">
<span itemprop="name">BRAND 502</span>
</a>
<div itemprop="offers" itemscope itemtype="http://schema.org/Offer">
<span itemprop="price">4399 р.</span>
</div>...
<div itemprop="itemListElement" itemtype="http://schema.org/Product">
...
</div>
</div>
</div>Что произошло:
Были добавлены новые атрибуты с параметрами, например itemprop="offers", itemprop="price". Также добавились новые контейнеры-обертки, например < div itemscope itemtype="http://schema.org/ItemList" >
Примерно похожим образом нужно разметить и другие составляющие сайта: общую информацию, карточки товаров, статьи, хлебные крошки и т.д.
Реализовывать микроразметку таким образом неудобно и долго. К тому же Microdata не дает никаких преимуществ.
Вариант 2 - JSON
Разметка передается в виде отдельного скрипта в формате ключ-значение. При таком варианте реализации нет необходимости оборачивать теги и добавлять новые атрибуты с параметрами, нужно разместить всего один кусочек информации в формате JSON – быстро и удобно.
Если ваш сайт сделан на CMS, можно подобрать плагин для вашей системы. Некоторые решения перечислены в документации на русском.
Например, для Open Cart мне очень нравится пользоваться Microdata Pro.
Для проверки используйте валидатор Google.
Если вы хотите реализовать разметку самостоятельно
Разметка JSON может быть размещена в любой секции html-кода – можно в head, можно в body.
Предлагаю вам универсальный набор JSON-скриптов. Почти все сайты, с которыми мне доводилось работать – интернет-магазины или сайты услуг, поэтому набор разметок почти всегда одинаковый.
Разметка общей информации о сайте
Я использую эти скрипты на всех страницах сайта (в секции head).
Тип WebSite
<script type="application/ld+json">
{
"@context":"http://schema.org",
"@type":"WebSite",
"name":"Напишите любое название русскими или английскими буквами, например MuzOkon",
"alternateName":"Напишите любое альтернативное название, можно написать целую фразу, например: Остекление лоджий и балконов МузыкаОкон",
"url":" Напишите полный адрес вашего домена, например https://www.muzokon.ru/"}
</script>Тип Person – социальные сети
<script type="application/ld+json">
{
"@context":"http://schema.org",
"@type":"Person",
"name":" Напишите любое название русскими или английскими буквами, например MuzOkon ",
"url":" Напишите полный адрес вашего домена, например https://www.muzokon.ru/",
"sameAs":["https://vk.com/okna_music",
"https://twitter.com/muzokon2011",
"https://www.facebook.com/oknamusic",
"https://plus.google.com/u/0/105130374506760946867",
"https://www.youtube.com/channel/UC4catfWleu5HQzzKmaWomGg"]
}
</script>Тип Organization – общая информация об организации
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Organization",
"url": "Напишите полный адрес вашего домена, например http://www.cvetyopt.ru",
"logo": " Напишите полный путь к любой картинке или логотипу, например http://www.cvetyopt.ru/image/data/header.jpg",
"address":
{
"@type": "PostalAddress",
"addressLocality": "Санкт-Петербург",
"postalCode": "191014",
"streetAddress": "ул.Белинского, 9, ПН-ВС 10.00-19.00",
"telephone": "+7 (921) 888-99-99"
}
}
</script>Разметка страницы контактов
Используйте на странице контактов (в body).
Тип LocalBusiness – общая информация об организации
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "LocalBusiness",
"address": {
"@type": "PostalAddress",
"addressLocality": "Санкт-Петербург",
"postalCode": "190005",
"streetAddress": "Московскйи проспект, 51",
"telephone": "+7 (981) 825-85-75"
},
"description": "Краткое Описание организации",
"url": "Полный URL домена",
"image": " Полный URL логотипа или другой картинки",
"logo": " Полный URL логотипа",
"priceRange": "Плюшевые медведи от 2390 рублей",
"telephone": "+7 (981) 777-88-99",
"openingHours": "Ежедневно 09:00-22:00"
}
</script>Также существует возможность конкретизировать вид бизнеса. Вместо LocalBusiness можно указать Florist, ToyStore и многое другое. Посмотрите документацию в разделе «More specific Types».
Пример конкретизации - ToyStore
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "ToyStore",
"description": "Красивые Большие Плюшевые Медведи с доставкой по СПб и Ленинградской области.",
"name": "Большие плюшевые медведи СПб",
"url": "http://большие-плюшевые-медведи.рф/",
"image": "http://большие-плюшевые-медведи.рф/image/cache/catalog/10-504x700.jpg",
"logo": "http://большие-плюшевые-медведи.рф/image/catalog/logo.png",
"priceRange": "от 2390 RUB",
"address":
{
"@type": "PostalAddress",
"addressLocality": "Санкт-Петербург",
"streetAddress": "Московский проспект, 51",
"telephone": "+7 (981) 825-85-75"
},
"openingHoursSpecification" : {
"@type" : "OpeningHoursSpecification",
"dayOfWeek" : [ "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday" ],
"opens" : "09:00:00",
"closes" : "22:00:00"
},
"department" :"http://москва.большие-плюшевые-медведи.рф/"
}
</script>В этом варианте, помимо указания конкретного вида бизнеса, присутствует дополнительная информация о времени работы и других отделениях компании.
Когда-то я решил использовать тип Organization на всех страницах, а LocalBusiness на странице с контактами. Однако вам ничего не мешает использовать LocalBusiness (или более подробный формат – Florist, ToyStore и т.д.) на всех страницах сайта. При этом Organization можно оставить или убрать – на ваш вкус.
Разметка карточек товаров
Для разметки необходима помощь веб-мастера. Разметка размещается в шаблоне карточки товара. В нее подставляются подходящие переменные.
Универсальный короткий вариант
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "Product",
"name": "Сюда можно вывести информацию, которая выводится в h1 или содержится в переменной названия товара",
"image": "URL картинки товара",
"description": "Информация, которая вводится в мета-дескрипшн",
"offers": {
"@type": "Offer",
"priceCurrency": "RUB",
"price": "1540",
"availability": "http://schema.org/InStock",
"seller": {
"@type": "Organization",
"name": "Название сайта и организации в любом виде"
}
}
}
</script>В разметку можно добавить дополнительную информацию о товаре: название бренда, звездочки и количество отзывов – эта информация красиво показывается в выдаче Google.
Расширенный вариант
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "Product",
"name": "Сюда можно вывести информацию, которая выводится в h1 или содержится в переменной названия товара",
"image": "URL картинки товара",
"description": "Информация, которая вводится в мета-дескрипшн",
"brand": {
"@type": "Thing",
"name": "Название бренда товара"
},
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "5",
"reviewCount": "14"
},
"offers": {
"@type": "Offer",
"priceCurrency": "RUB",
"price": "1540",
"availability": "http://schema.org/InStock",
"seller": {
"@type": "Organization",
"name": "Название сайта и организации в любом виде"
}
}
}
</script>Получается примерно такой сниппет:
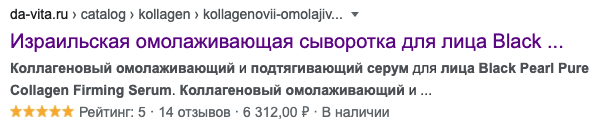
Отмечу, что с помощью JSON разметки можно осуществлять небольшие манипуляции – в этом примере рейтинг 5 и 14 отзывов передаются в разметке статически, то есть прям хардкодно указаны эти значения. На самом деле на странице товаров этого магазина может быть меньше, больше отзывов или вообще их не быть. Рейтинг тоже не меняется – он всегда 5. Меняется цена. Да, это манипуляция результатами выдачи, за это даже предусмотрены соответствующие санкции. Если санкции будут наложены, сайт не будет понижен в ранге, но пропадет вся красота из сниппетов. В случае с da-vita, санкций не было никогда, на сайте выводятся не до конца правдивые данные примерно 4 года - видимо для Google это несерьезный проступок. Такая недоделка обусловлена некоторыми проблемами сайта. Я рекомендую вам всегда выводить правдивую информацию.
При валидации вы можете увидеть предупреждения:

Это всего лишь рекомендации по дополнению вашей разметки. Ничего страшного, если каких-то параметров у вас нет. Предупреждения можно игнорировать, а ошибки надо обязательно устранять, иначе разметка не будет работать.
Разметка категорий с товарами
При разметке категорий тоже используется тип Product.
Простой вариант:
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "Product",
"name": "Передайте название категории, можно использовать переменную H1",
"image": "Полный URL картинки категории, если есть, можно любую, например логотип",
"description": " Передайте описание категории, можно использовать мета-тег Description",
"offers": {
"@type": "AggregateOffer",
"lowPrice": "Передайте минимальную цену товара в категории",
"highPrice": " Передайте максимальную цену ",
"priceCurrency": "RUB"
}}
</script>Примерный результат:

Можно использовать сложный вариант – веб-мастеру нужно написать цикл, в котором будет использоваться разметка, указанная для карточек товара. Получится большой список (массив), состоящий из отдельных разметок для товаров.
Результат вывода в коде будет выглядеть примерно так:

Обратите внимание, что в этом случае можно передать рейтинг и количество отзывов. Помимо диапазона цен в сниппете будут звездочки и отзывы:
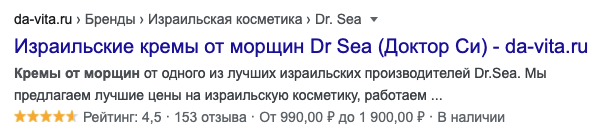
На мой взгляд сложный вариант ничем не лучше простого. Какой использовать – решать вам.
Разметка страниц услуг
В случае с сайтами услуг (на различных CMS), может быть проблематично вставить скрипт JSON и разметить его переменными самостоятельно. В этом случае можно использовать Google Tag Manager. Будет немного хлопотно размечать каждую страницу отдельно, но в качестве компенсации у вас будет гибкость – в разметку можно будет передать информацию любым образом.
Для разметки страниц такого типа отлично подходит тип Product
Вариант разметки страницы с одной услугой:
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "Product",
"name": "Подключение электричества 15 КВт",
"image": "https://muchenergy.ru/templates/yootheme/cache/logo2-abf2db4d.webp",
"description": "Компания MuchEnergy оказывает услуги подключения электричества к частным домам и земельным участкам в СПб и Ленинградской области. Заявку можно оформить на сайте или по телефону: +7 (812) 944-42-48.",
"brand": {
"@type": "Brand",
"name": "MuchEnergy"
},
"offers": {
"@type": "AggregateOffer",
"name": "Сдача инспектору сетевой организации смонтированной электроустановки (щита)",
"priceCurrency": "RUB",
"lowPrice": " 5000",
"seller": {
"@type": "Organization",
"name": "MuchEnergy"
}
}
}
}
</script>Вариант разметки страницы, где несколько услуг:
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "Product",
"name": "Подключение электричества 15 КВт",
"image": "https://muchenergy.ru/templates/yootheme/cache/logo2-abf2db4d.webp",
"description": "Компания MuchEnergy оказывает услуги подключения электричества к частным домам и земельным участкам в СПб и Ленинградской области. Заявку можно оформить на сайте или по телефону: +7 (812) 944-42-48.",
"brand": {
"@type": "Brand",
"name": "MuchEnergy"
},
"offers": [{
"@type": "AggregateOffer",
"name": "Cбор документов, подача заявки в сетевую организацию",
"priceCurrency": "RUB",
"lowPrice": "5000",
"seller": {
"@type": "Organization",
"name": "MuchEnergy"
}
},
{
"@type": "AggregateOffer",
"name": "Монтаж (на существующую опору) щита в комплекте",
"priceCurrency": "RUB",
"lowPrice": " 20000",
"seller": {
"@type": "Organization",
"name": "MuchEnergy"
}
},
{
"@type": "AggregateOffer",
"name": "Сдача инспектору сетевой организации смонтированной электроустановки (щита)",
"priceCurrency": "RUB",
"lowPrice": " 5000",
"seller": {
"@type": "Organization",
"name": "MuchEnergy"
}
}
]
}
}
</script>Разметка информационных страниц
BlogPosting - подойдет для разметки статей
Можно разметить шаблон, используя переменные, можно передать скрипт с помощью Google Tag Manager.
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "BlogPosting",
"mainEntityOfPage":{
"@type":"WebPage",
"@id":"Подставьте полный URL статьи"
},
"headline": "используйте переменную H1 или Title",
"description": "Meta-description или какое-либо другое краткое описание",
"image": {
"@type": "ImageObject",
"url": "Полный URL какой-либо картинки из статьи",
"height": Передайте значение высоты картинки без кавычек (можно указать статические значения),
"width": Передайте значение ширины картинки без кавычек
},
"datePublished": "Передайте Дату публикации",
"dateModified": "Дата модификации - можно поставить счетчик, чтобы например каждую неделю дата обновлялась",
"author": {
"@type": "Person",
"name": "Передайте имя автора статьи. Можно указать статическое значение название сайта или организации"
},
"publisher": {
"@type": "Organization",
"name": " Передайте название организации или сайта ",
"logo": {
"@type": "ImageObject",
"url": "Полный URL лого компании",
"width": Передайте значение ширины без кавычек
}
}
},
}
</script>Для статей можно использовать тип Article. Ознакомьтесь с документацией и примерами.
Question – подойдет для разметки FAQ
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Question",
"name": "Можно передать название переменную H1",
"text": "Передайте текст вопроса",
"upvoteCount": "1",
"dateCreated": "Передайте дату вопроса",
"answerCount": "1",
"acceptedAnswer": {
"@type": "Answer",
"upvoteCount": "1",
"text": " Передайте текст ответа",
"dateCreated": " Передайте дату ответа",
"author": {
"@type": "Person",
"name": "Название организации"
}
}
}
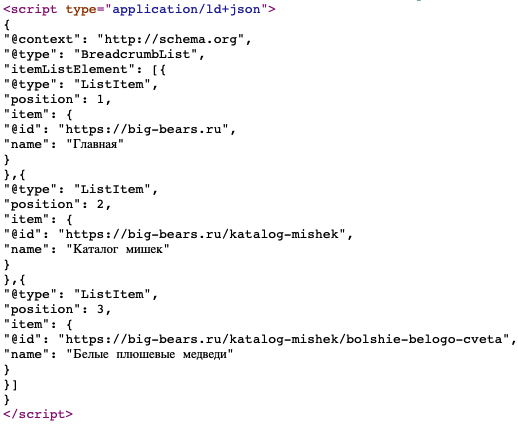
</script>BreadcrumbList – хлебные крошки
Веб-мастеру необходимо написать цикл, с помощью которого будет размечена информация в хлебных крошках.
Пример отработки кода:
Можно пойти дальше и подставить в разметку эмодзи:

Используя перечисленные типы, вы сможете разметить почти всю информацию на сайте: информацию об организации, товары, услуги и информационные страницы.
OpenGraph
Еще один стандарт разметки, разработанный Facebook. На нем я останавливаться не буду. Этот формат нужен для отрисовывания красивых сниппетов, когда вы постите ссылку в социальных сетях или пересылаете ее через мессенджеры. Парсер возьмет всю текстовую информацию и картинку из разметки. Без нее это может произойти произвольно, и получится некрасиво.
HTML
Кратко я бы хотел остановиться на теме HTML. Это мало относится к SEO, вернее тема настолько глобальная, что она затрагивает не только SEO, а вообще имеет ключевое значение при создании сайта.
Почти всегда приходится иметь дело с сайтами, которые сделаны на CMS с использованием шаблонов, изготовленных под эти CMS. Почти никто из обычных заказчиков (представителей малого бизнеса) не располагают ресурсами, чтобы заказать действительно качественный дизайн и верстку. Обычно сайт надо сделать «еще вчера» и как можно дешевле, ведь впереди еще ждет закупка трафика! Эту проблему я кратко затрагивал в первой статье.
Основываясь на опыте нашей компании, я могу сказать, что заказчики при создании сайта и выборе шаблона руководствуются только визуальным восприятием дизайна, вернее покупаемого шаблона. То, как сверстан шаблон, насколько он оптимизирован для всех устройств никого обычно не волнует. Решаться всплывающие проблемы будут потом, если, конечно, вообще будут решаться.
Это я все к чему вообще?
HTML – это разметка, это инструкции, которые написаны для браузера. Браузер «отрисовывает» всю информацию так, как указано в этих инструкциях.
Вот тег < p > - это текст, вот < ul > и < li > - это списочек, вот < td >< tr > - это табличка, а вот < div > - это контейнер и т.д.
Есть CSS – таблица стилей, в которой браузер узнает, как именно показать текст, список и все другие элементы. К этому всему надо прибавить Java Script и получается вообще красота. С помощью CSS и JS можно накрутить что угодно. Например, можно использовать заголовок первого порядка < h1 > с разными селекторами CSS, и получатся разные заголовки, но заголовок < h1 > должен быть один, а так их будет сколько угодно. Или контейнеру < div > можно задать любой стиль и поведение, и получится список, таблица, кнопка и все, что угодно. У этого даже есть название – дивянка. Почему так происходит? Ну дизайнеру верстальщику просто все равно, насколько валидная получается разметка, главное нарисовать, что хотел заказчик, ну или просто слепить шаблончик и продать.
Проблема не только в том, что оптимизатору или контент-менеджеру придется разбираться в такой верстке, но и поисковому роботу (см. Пункт о парсинге). При использовании html тегов по назначению робот легко извлечет текст, цену товара, картинку и всю остальную информацию. Легко поймет, что это меню, а что другое – кнопка. И только можно догадываться, как робот будет извлекать информацию, если производитель дизайна болел дивянкой.
Когда-то я смотрел курсы HTML Academy. В теме о валидности разметки был кейс: на сайте tutu расписание было сверстано с использованием контейнеров < div >, а не таблиц, когда расписание было переделано с помощью тегов таблиц, Google сразу стал показывать расписание в расширенных результатах выдачи, что определенно точно способствовало увеличению трафика из органического поиска. По этому кейсу у меня пруфа нет, с тех времен в поисковой выдаче много раз все поменялось, наверное, можно посмотреть в курсе HTML Academy.
В качестве примера можно взять расширенные результаты с расписанием кинотеатра:
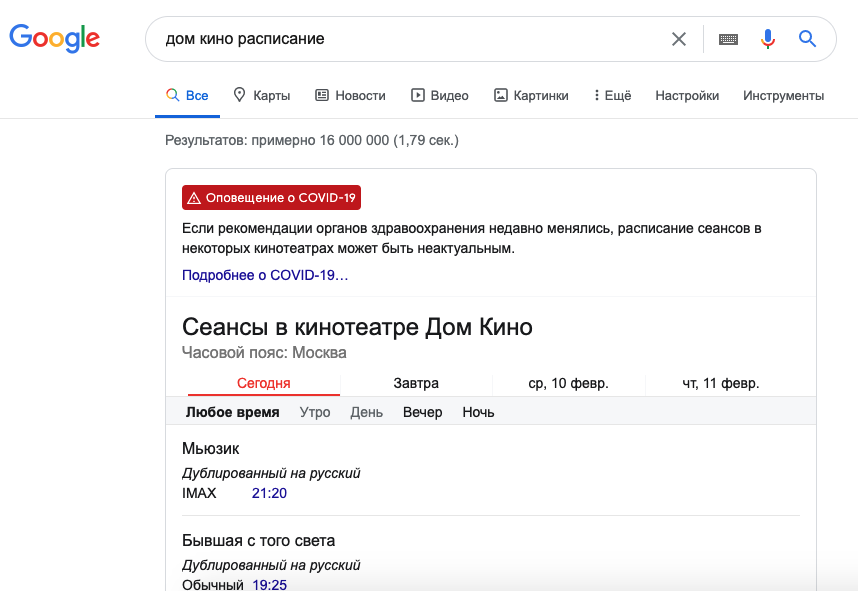
Качественная верстка – это важно, очень важно.
Как осуществлять проверку
Без возможности осуществить проверку все вышеперечисленное воспринимается как нечто абстрактное.
Большой ценностью обладает статистика, предоставляемая Яндекс Вебмастером и Google Search Console – эти данные содержат всю необходимую информацию об индексировании вашего сайта.
Приступаем к проверке
Шаг 1: Получаем все каноничные адреса сайта
Вам необходимо собрать как можно больше актуальных адресов вашего сайта. Среди них должны быть продвигаемые страницы – главная, категории товаров и карточки, страницы с услугами, статьи и любые другие, которые обладают значением для продвижения.
Для сбора страниц непосредственно с сайта купите программу-краулер (парсер). Например, это может быть Comparser, Netpeak Spider, Screaming Frog. Я использую Comparser. Благодарю разработчика Александра Алаева за прекрасную программу, которая продается за 2000 рублей (разовая оплата) – считаю, что это практически даром за такой инструмент.
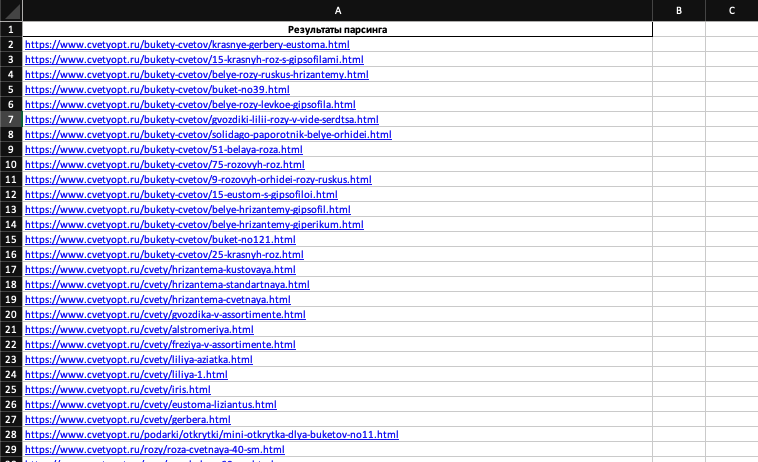
Если парсера нет и покупать пока не хотите, получить адреса можно из карты сайта. Например, с помощью такого сервиса.
Приступаем. Буду использовать адреса из Sitemap. Все полученные URL сохраняем в таблице:
Шаг 2: Получаем статистику индексирования из Яндекс Вебмастера и Google Search Console
Яндекс Вебмастер
Открываем раздел «Индексирование», отчет «Страницы в поиске»:
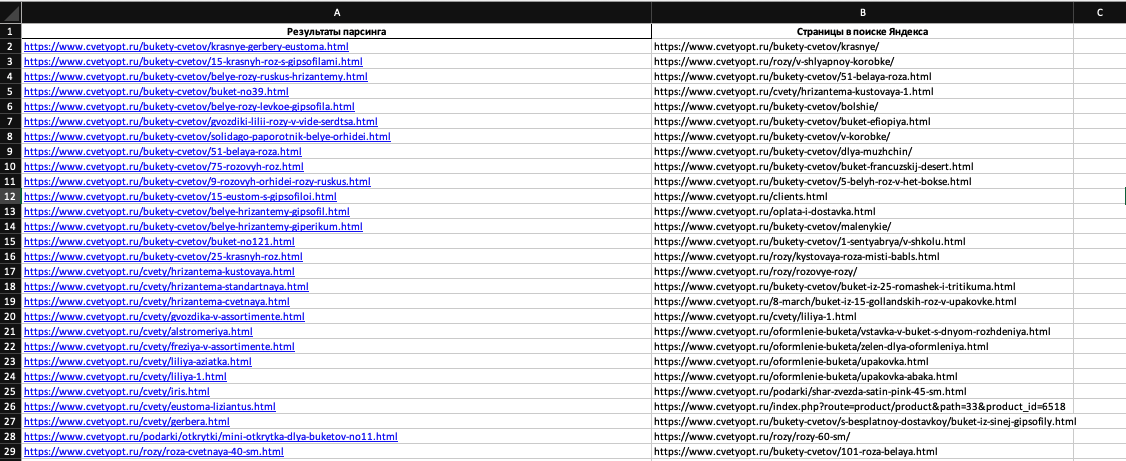
Переходим в отчет. Нажимаем на вкладку «Все страницы» и скачиваем отчет по кнопке в самом низу страницы:

Скачиваем таблицу, в которой содержится несколько полей:
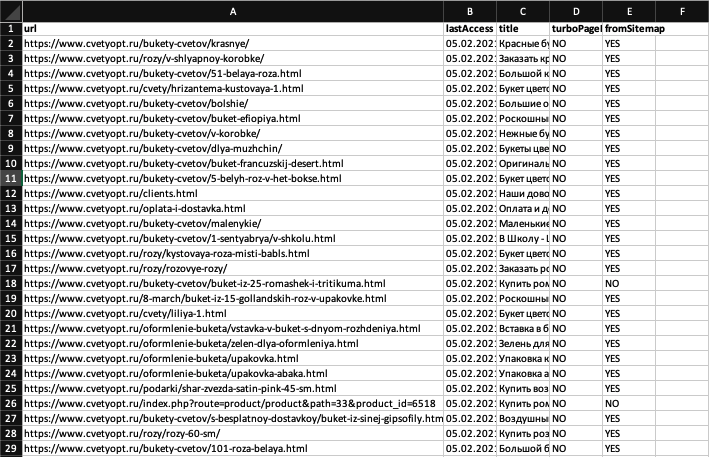
Нас интересует поле «URL». Копируем весь столбец и переносим данные в таблицу с результатами парсинга, или наоборот, как хотите, нужно, чтобы результаты парсинга и поисковая база оказались в одном файле. Примерно вот так:
Google Search Console
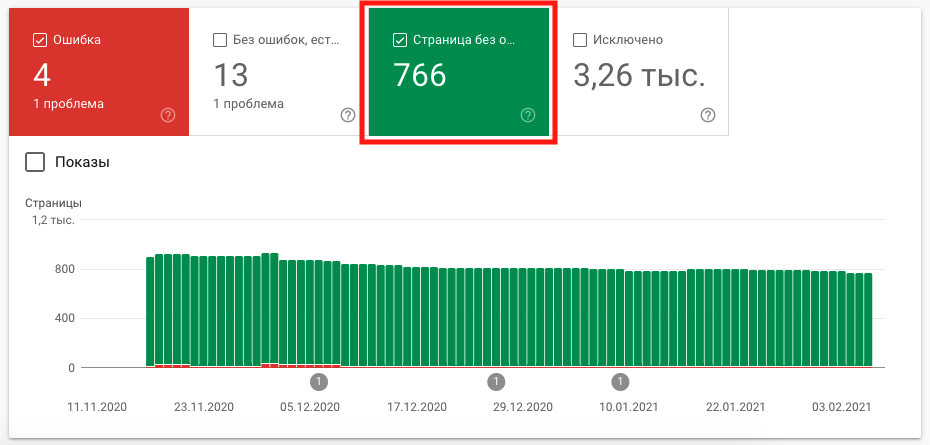
Открываем раздел «Индекс», отчет «Покрытие»:

Нажимаем на вкладку «Страницы без ошибок»:
Переходим ко вкладкам ниже и видим различные отчеты Google об индексировании.
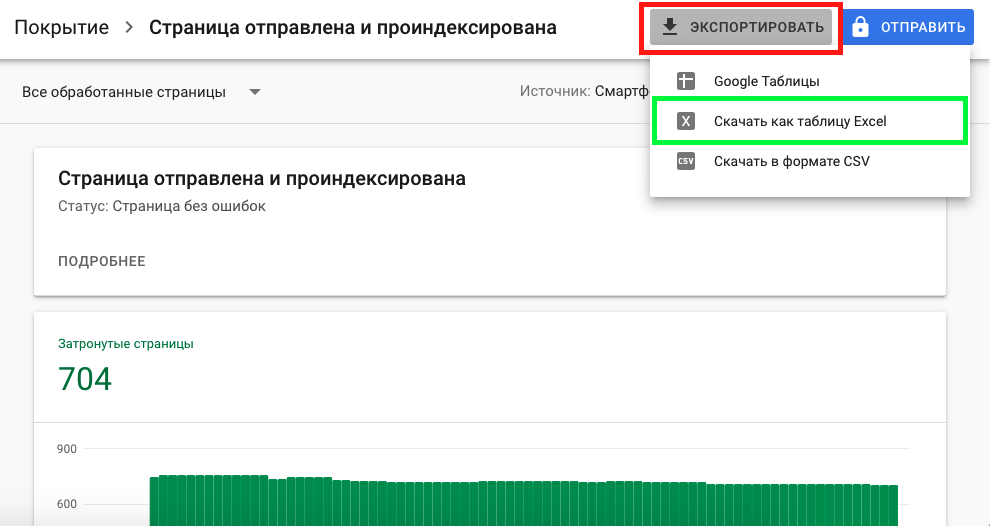
Напомню нашу задачу – сопоставить страницы в поисковой базе с результатами парсинга. Google уже сделал сопоставление за нас – пропарсил карту сайта и сопоставил со станицами в базе. Можно сразу переходить в отчет «Страница проиндексирована, но ее нет в файле Sitemap».

Если есть желание сделать полностью свою проверку, нужно скачать таблицы из этих отчетов по очереди и соединить в одну таблицу:
При экспорте получаем таблицы такого вида:
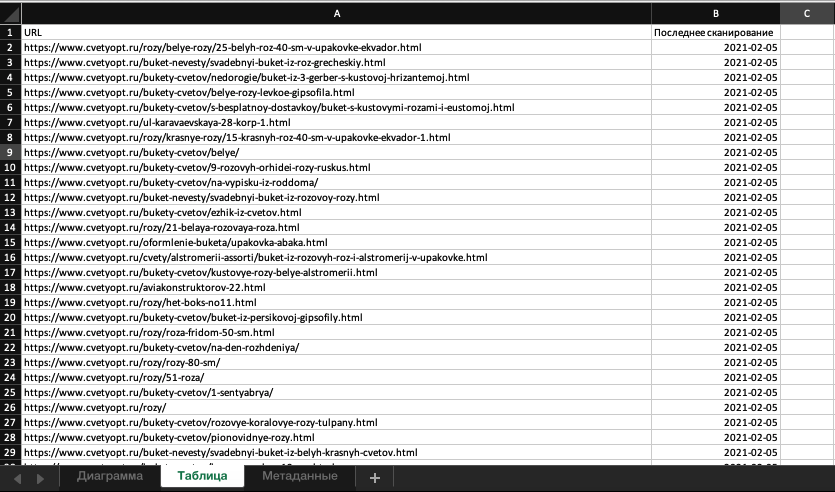
Совмещаем с результатами парсинга:
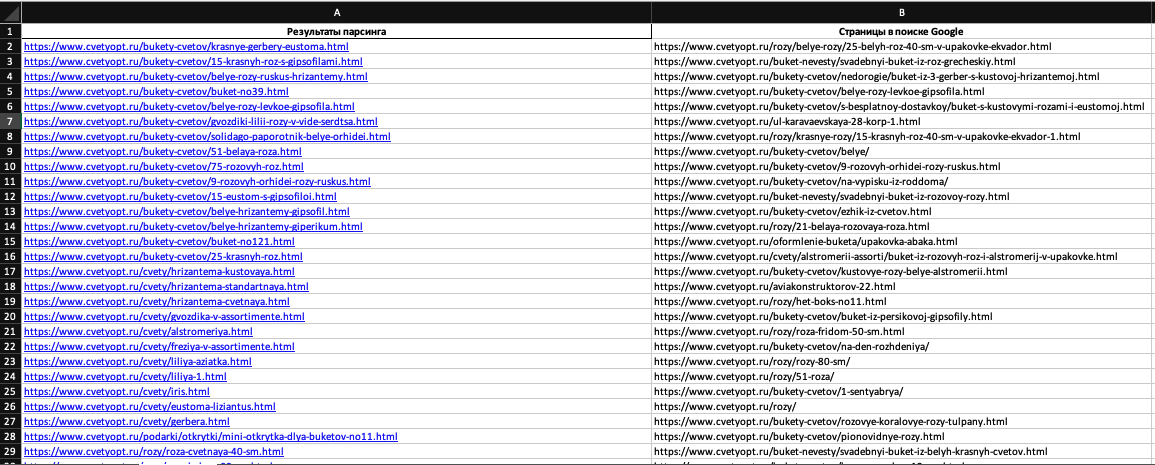
Шаг 3: Сопоставляем данные
Показывать пример сопоставления дальше буду на данных Яндекса (для данных Google подход не отличается).
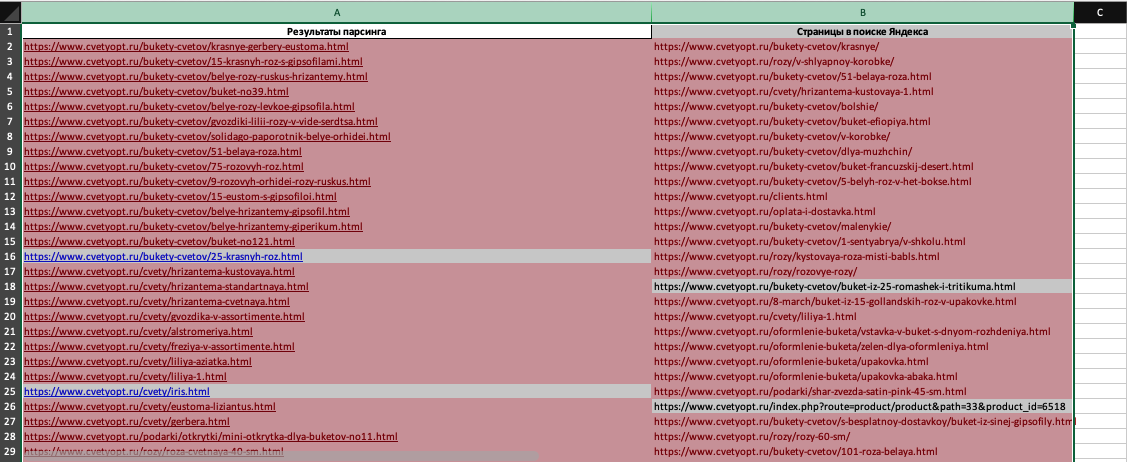
Выделяем сопоставляемы поля. Нажимаем «Условное форматирование», «Правила выделения ячеек», «Повторяющиеся значения»:

Совпадающие значения выделились цветом, это значит, что эти страницы сайта, полученные в результате парсинга есть в поисковой базе.
Но нас интересуют несовпадения. Выполним сортировку. Выделяем поля, нажимаем «Сортировка и фильтр», «Пользовательская сортировка»:
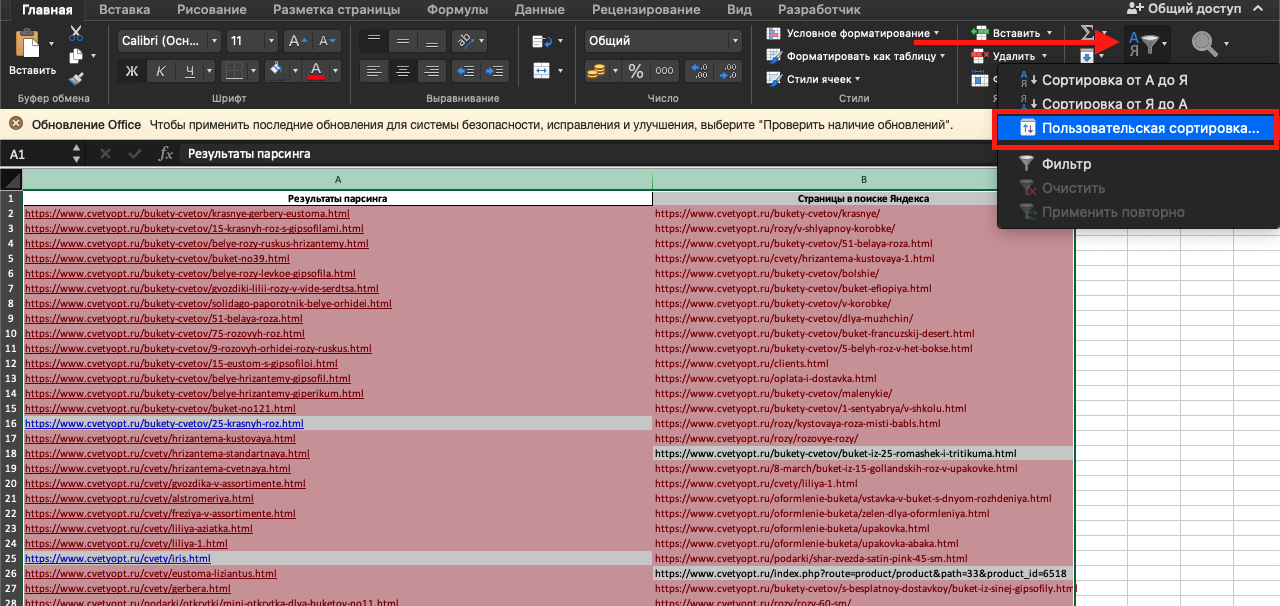
Для сортировки выбираем любой из двух столбцов, ставим сортировку по цвету ячейки, порядок – снизу, выбираем цвет, которым подсвечены несовпадения:
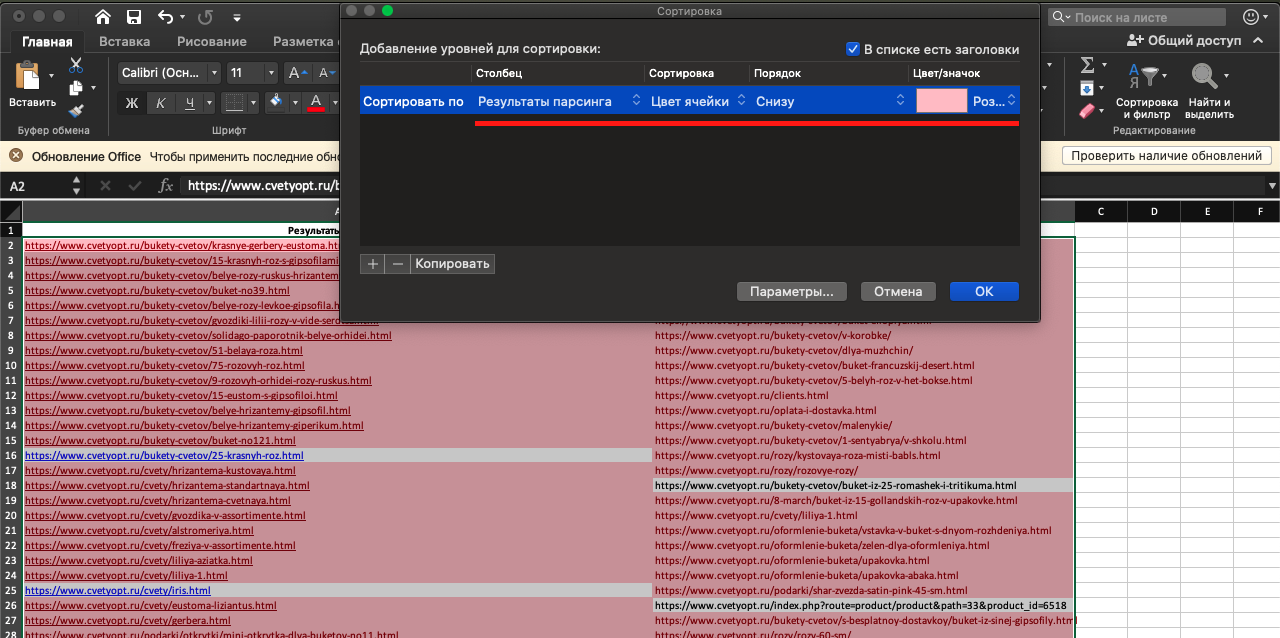
Получаем список страниц, которые есть на сайте, но отсутствуют в поисковой базе и список страниц, которые есть в базе Яндекса, но отсутствуют в результатах парсинга (в нашем случае это адреса из sitemap).
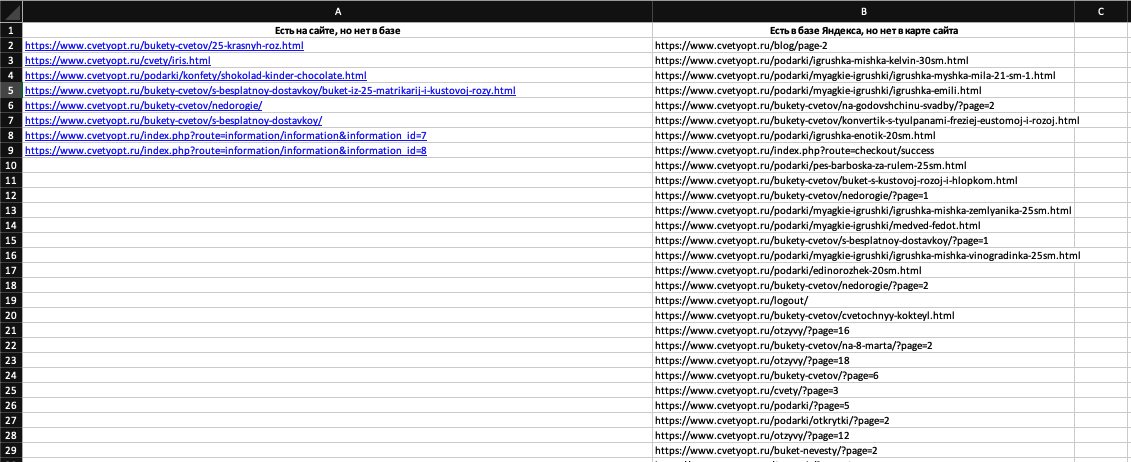
Шаг 4: Анализируем причины несоответствий
Страницы, которые есть в Sitemap, но отсутствуют в поисковой базе
Проверяем небольшой списочек, в котором есть несколько карточек, пара категорий и 2 неЧПУ адреса, сгенерированные CMS, в нашем случае это Open Cart.
Вряд ли эти адреса запрещены в robots.txt, но можно убедиться:
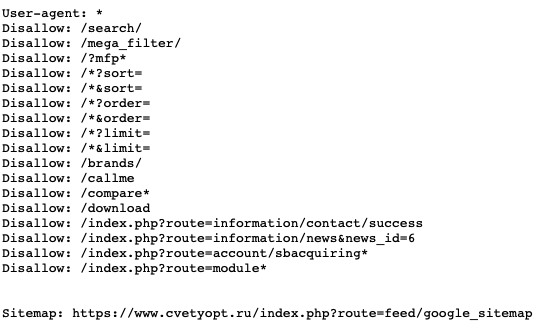
URL категорий и карточек не запрещены, неЧПУ адреса тоже не попадают в запрещающие правила.
Проверю, могут ли адреса не индексироваться из-за canonical.
Например:

В canonical страница ссылается сама на себя, проблем нет.
Во время проверки всех адресов были выявлены ссылки, которые дают 404:
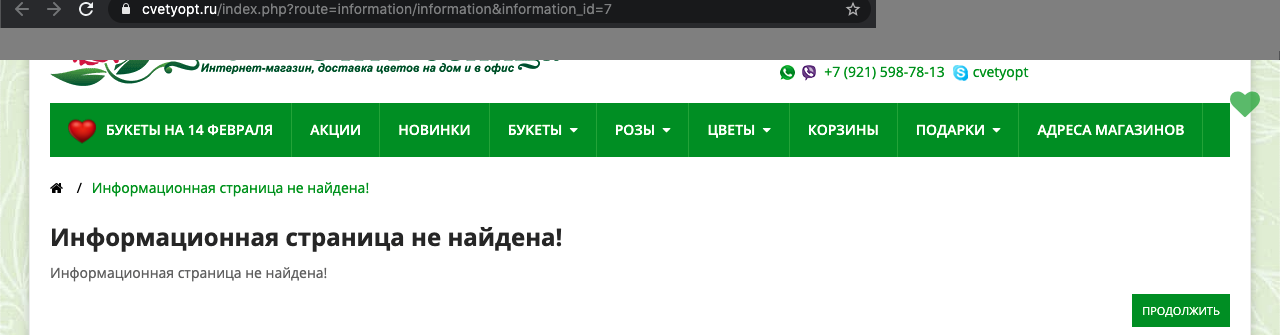
Конечно, они не будут в поисковой базе, поиск удаляет битые страницы. Другой вопрос, почему страницы с ответом 404 оказались в карте сайта? Попрошу веб-мастера разобраться, может дело в модуле, который генерирует sitemap.
Страницы, которые дают ответ 200 отправлю на переобход через форму в разделе «Индексирование», «Переобход страниц»:

Страницы, которых есть в поисковой базе, но отсутствуют в Sitemap
Теперь разберемся со второй колонкой. В списке URL сразу бросается в глаза категории с пагинацией. В нашем случае никаких проблем нет – пагинацию я всегда даю индексировать, а в карте сайта ее не принято указывать. Поэтому появилось несоответствие:
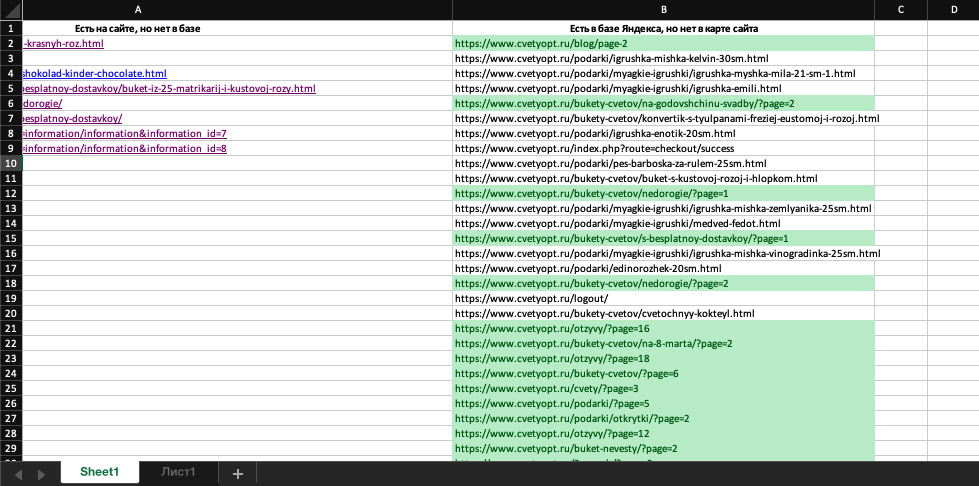
Затем при просмотре обнаруживаю страницу логина в личный кабинет /login/ - /logout/, форму «Забыли пароль?» /forgot-password/, форму быстрой регистрации /simpleregister/. Они не вызывают вопросов, т.к. не попали в карту сайта, потому что не представляют ценности для продвижения.
Также, в списке есть корзина /simplecheckout/, которую я не запретил в роботсе, она тоже не содержится в карте сайта.
Перечисленные страницы не вызывают вопросов. Проблем нет.
В этом списке есть страница контактов /contact-us/ и акций /specials/. Они тоже не попали в карту сайта, но робот их нашел на сайте. Причины несоответствия не вызывают вопросов, но я бы добавил эти две страницы в sitemap, напишу об этом веб-мастеру:
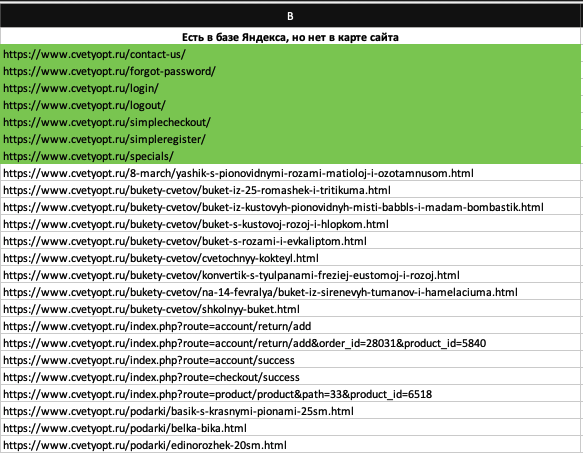
Идем дальше. В списке присутствуют адреса товаров:

Проверяю каждый адрес, большинство адресов дает ответ 404. Наверное, товары были отключены, а поиск не успел удалить из базы битые страницы.
Есть несколько вариантов, что можно сделать
Ничего не делать, страницы 404 удалятся из базы сами собой.
Об этих страницах можно сообщить поиску через форму в разделе «Индексирование», «Переобход страниц», после переобхода они скорее всего будут удалены.
Создать в Яндекс Вебмастере заявку на удаление через форму в разделе «Инструменты», «Удаление страниц из поиска»:
Далее выбираем вкладку «По URL» и вставляем список страниц:
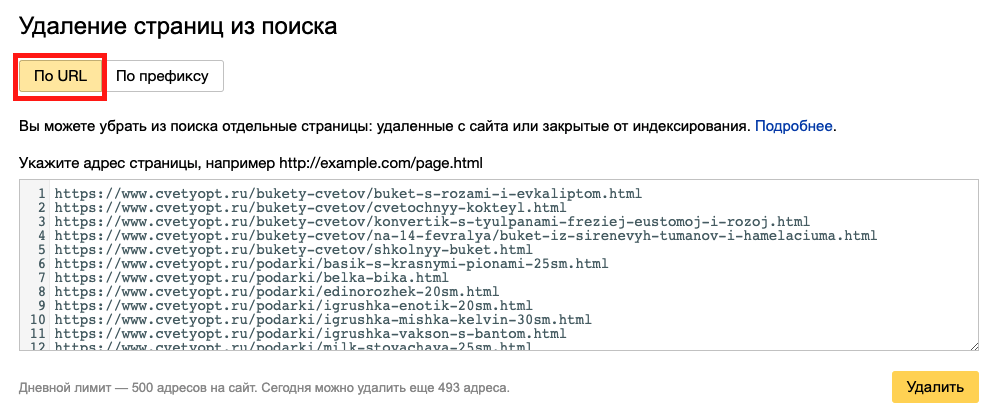
Через некоторое время заявка будет обработана, и страницы удалятся.
Также в списке есть страницы, которые дают ответ 200, но их почему-то нет в карте сайта, напишу об этом веб-мастеру.
И в конце всех разборов у меня осталось несколько адресов:

Разбираю ссылки
Форма возврата товара - https://www.cvetyopt.ru/index.php?route=account/return/add
Форма возврата товара, как будто с параметрами сформированной заявки - https://www.cvetyopt.ru/index.php?route=account/return/add&order_id=28031&product_id=5840
Как заявка на возврат могла попасть в поисковую базу при условии, что такая ссылка нигде не размещена? Мистика.
Страница с текстом о создании учетной записи - https://www.cvetyopt.ru/index.php?route=account/success
Страница с текстом о создании заказа - https://www.cvetyopt.ru/index.php?route=checkout/success
НеЧПУ адрес товара - https://www.cvetyopt.ru/index.php?route=product/product&path=33&product_id=6518
Для товара сгенерирую ЧПУ средствами CMS. В результате будет новый URL, а старый (неЧПУ) будет давать ответ 301 – постоянное перенаправление. Старый адрес отправлю на переобход, так поиск узнает, что страница переехала, старый адрес надо удалить, а новый добавить.
Чтобы удалить другие непонятные урлы и предотвратить попадание подобных адресов в будущем, добавлю запрещающие правила в robots.txt:
Disallow: /index.php?route=account/return/add* ## звездочка означает: «и любые другие значения»
Disallow: /index.php?route=account/success
Disallow: / index.php?route=checkout/successВажное замечание: после запрещения параметров или частей URL в robots.txt такие адреса сами по себе не удалятся, напротив, робот не получит доступ и не сможет с ними ничего сделать. После запрещения нужно подать заявку на удаление в Яндекс Вебмастере через форму в разделе «Инструменты», «Удаление страниц из поиска». Конкретно в этом случае такое количество адресов можно удалить, просто передав список.
Вывод по проверке
-
Получили адреса сайта.
-
Получили статистику адресов в поисковой базе Яндекса.
-
С помощью Excel сопоставили адреса и выявили несовпадения.
-
Анализ показал, что дублей в поисковой базе нет, но есть служебные URL, которые оказались в базе непонятным образом. Добавлены правила в robots.txt, запрещающие сканировать такие адреса и направлена заявка на удаление. Также, выявлены проблемы с картой сайта – она не содержит актуальный список страниц, для решения проблемы примеры адресов были переданы веб-мастеру.
Еще один пример проверки состояния поисковой базы
Чтобы не повторяться, пропускаю этапы, связанные с получением актуальных адресов сайта и получением поисковой статистики. Показываю результат сопоставления и сразу перехожу к анализу:

Левая колонка - страницы, которые есть в sitemap, но отсутствуют в поисковой базе
Эти адреса вопросов не вызывают – свежие информационные страницы и товары, на момент проверки поисковик не успел их проиндексировать. Для ускорения процесса отправлю их на переобход.
Правая колонка - страницы, которые есть в поисковой базе, но отсутствуют в Sitemap
2455 адресов в списке.
Первым делом обращаю внимание на дубликаты страниц, которые образованы параметром /?spush=:
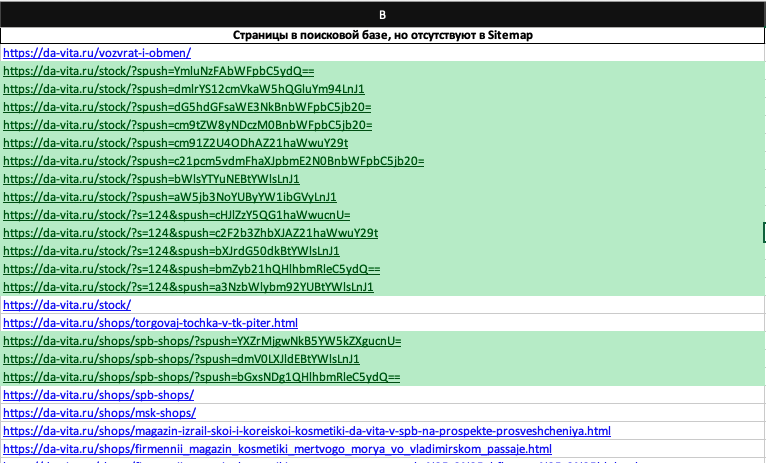
Этот параметр запрещен в robots.txt:
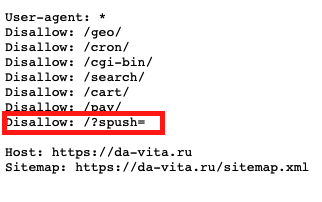
Несмотря на запрет, дубли попали в индекс. Для защиты на этом сайте есть canonical, который ссылается на страницу без параметров:

Эти дубли со временем должны быть удалены, но не будем этого дожидаться и отправлю заявку на удаление:

Далее я нахожу некоторые несоответствия с Sitemap и анализирую их. Но больше всего меня интересует основная масса страниц каталога, которые есть в поиске:
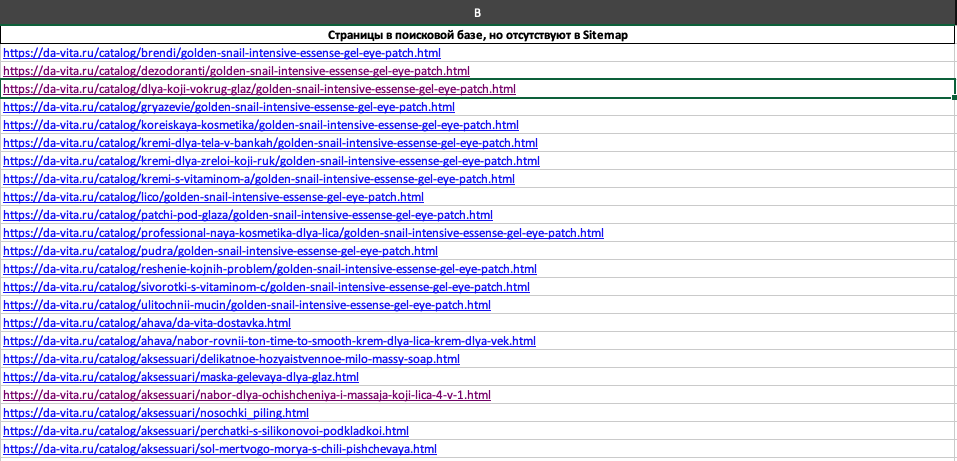
Таких страниц 2409. Это все дубликаты карточек товаров, которые образовались в результате непродуманной архитектуры (см. Примеры причин появления дублей, пример №2).
Проверю какой-нибудь адрес:

В качестве каноничного указан совсем другой адрес.
Техподдержка Яндекса рекомендовала кидать неканоничные страницы на переобход, чтобы робот обошел их заново. Так они быстрее удаляются. Это работает.

Суточная квота на переобход для этого проекта – 190 адресов. На переобход всего списка, выявленного при сопоставлении, уйдет примерно 13 дней.
Дополнительная проверка
Вскользь хочу упомянуть про «краулинговый бюджет». Вы легко сможете нагуглить статьи на эту тему. Смысл заключается в том, что на сканирование сайта поисковым роботом выделяется ограниченное количество времени. Нам важно, чтобы за это время было просканировано как можно большее число страниц. Проблема этой концепции заключается в том, что этот «бюджет» нельзя адекватно измерить и оценить, как повлияли какие-либо изменения на сайте на эту величину, но сама идея - хорошая.
Нужно следить, чтобы внутренние ссылки на сайте давали ответ 200, не были битыми (404) или перенаправляемыми (301).
Для такой проверки нужно просканировать сайт, используя программы-краулеры, о которых я упоминал выше. Результат сканирования будет содержать множество полей. Нас интересует URL, его ответ и источник, где был обнаружен этот URL.
Фильтрую столбец с ответами сервера, вижу, что адреса товаров имееют ответ 301 - перенаправляются на другой адрес. В настройках CMS укзано, что адреса карточек всегда без слеша в конце адреса, поэтому существует редирект. Неправильные ссылки были обнаружены на главной странице:

Нужно открыть исходный код главной страницы и поискать URL товаров со слешем на конце. Такие адреса обнаружились виджете, который показывает количество отзывов в товаре, там генерируется неправильная ссылка. Конкретно в этом случае такая проблема имеется у всех товаров сайта во всех категориях. Необходимо сообщить об этом веб-мастеру:
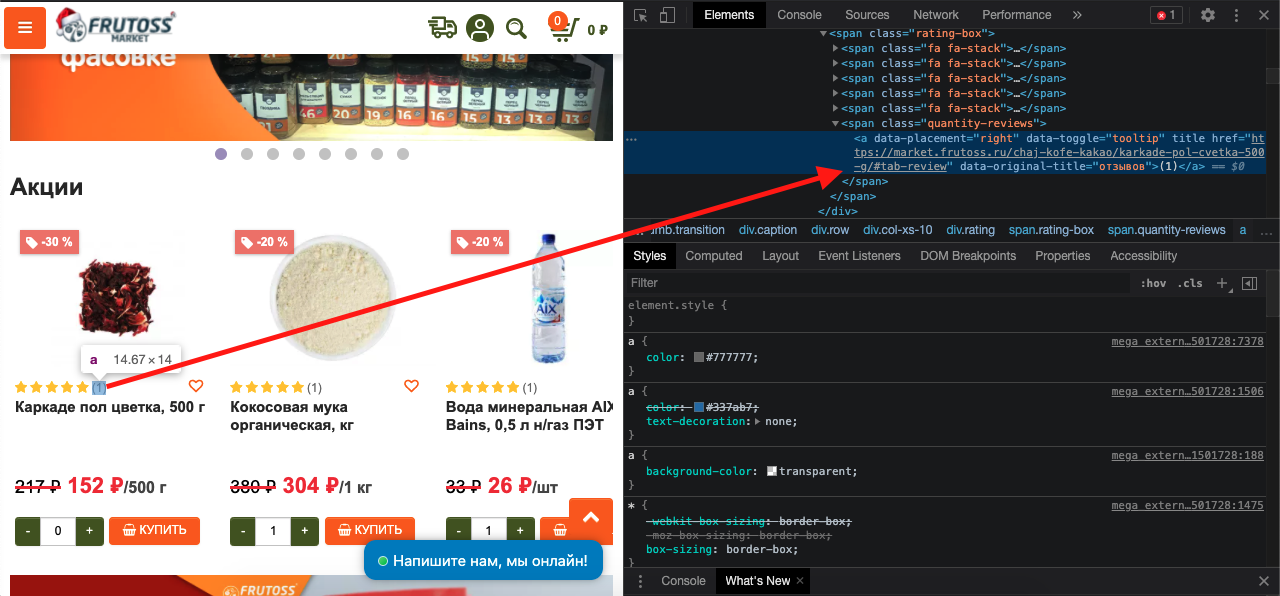
В этом случае неправильные адреса карточек вряд ли попадут в поисковую базу, потому что они всегда ведут на правильный, но с точки зрения «краулингового бюджета» поисковой робот потратит время впустую перебирая дубликаты карточек со слешами на конце. За один заход на сайт он проиндексирует меньше нужного контента, который должен быть в поиске
Помимо внутренних редиректов в контенте могут быть страницы с ответом 404. Например, у вас по каким-то причинам отключились информационные страницы, а ссылки на них находятся где-то в текстах на других страницах. Такие ссылки лучше заменить на актуальные или польностью убрать из кода.
Делайте такие проверки после каждого обновления функционала вашего сайта.
Выводы статьи
В этой статье я попытался раскрыть все самые важные аспекты технической оптимизации сайта для поискового продвижения, реализовав которые, ваш сайт будет добавлен в поисковую базу и появится в поисковой выдаче.
В статье поверхностно изложен процесс сканирования и индексирования сайта поисковым роботом.
SEO-специалист должен сделать так, чтобы в поисковую базу были добавлены страницы, на которые придет трафик из органического поиска. Один URL – уникальные мета-теги – уникальный текст и другое содержимое. Дубликаты не должны попадать в поиск.
Краткая инструкция:
Установите сервисы Яндекс Вебмастер и Google Search Console – накопители важной статистики об индексировании. Укажите в них адрес карты сайта.
Убедитесь, что все страницы сайта доступны только в одном варианте написания.
Узнайте, какие параметры используются на сайте. Они могут быть потенциальным источником дубликатов. Запретите обход страниц с параметрами в robots.txt. Дополнительно можно использовать canonical, который будет ссылаться на страницу без параметров.
Не переживайте на счет составления «идеального роботса». Если вы не учли какой-либо параметр, и из-за этого в поиск попали дули, вы сможете их обнаружить и устранить при проверке. Самое важное – не допустить ситуации, когда работающий сайт закрыт для индексирования полностью.
Используйте canonical, если у вас дублируются товары из-за разной вложенности (см. Причины дублирования, пример №2).
Если у вас есть пагинация, не запрещайте доступ в robots.txt, не используйте canonical и конструкцию < meta name=”robots” content=”noindex, follow” / >. Уникализируйте мета-теги Title и Description, например подставив в эти теги номер страницы.
Используйте микроразметку Shema.org. Для красоты отображение ссылки на сайт в социальных сетях и мессенджерах используйте OpenGraph.
Проводите регулярные проверки состояния индексирования вашего сайта. Сопоставляйте список актуальных страниц со статистикой из Яндекс Вебмастера и Google Search Console. Выявляйте несоответствия и анализируйте их. Если в индексе обнаружатся дубликаты, первым дело поймите причину их появления. Чтобы избавиться от них (в зависимости от ситуации) используйте запрещающие директивы в robots.txt вместе с заявкой на удаление через ЯВ и GSC. Также можно использовать canonical.
Это самые важные аспекты технической оптимизации. В других источниках вы можете встретить другие нюансы и рекомендации. Перед их реализацией подумайте, как на них отреагирует поисковой робот, как он сможет извлечь и обработать информацию. После реализации проведите проверку состояния поисковой базы, чтобы убедиться, что в ней присутствуют продвигаемые страницы без дублей.
Следующая статья: Как сделать SEO самому - Часть 3: Создание семантического ядра.
Похожие статьи:
Автоматизация - Индексирование сайтов с помощью Яндекс Вебмастер API на Python
Автоматизaция - Индексирование сайтов с помощью Index Now на Python
Автоматизация - Индексирование сайтов с помощью Google Indexing API на Python



