Автоматизация - Индексирование сайтов с помощью Яндекс Вебмастер API на Python
Содержание:
- Как использовать код из статьи
- Регистрация приложения
- Отправка списка страниц на индексирование в Яндекс Вебмастер:
- Импорт библиотек
- Настройки
- Загрузка URL для индексирования
- Отправка на индексирование
- Удаление из списка и экспорт
- Главная функция
- Запуск
- Получение списка проиндексированных страниц:
- Импорт библиотек
- Настройки
- Получение списка страниц
- Сопоставление полученных url из Вебмастера с актуальными адресами на сайте:
- Парсинг Sitemap
- Сопоставление адресов из базы Яндекса с адресами из Sitemap
- Создание визуального отчета в таблице
- Создание списка на переобход
- Главная функция
- Запуск
Как использовать код из статьи
Я размещу код на Гитхабе в формате Jupyter Notebook – думаю, что так нагляднее.
Установите питон и сборку библиотек Anaconda.
Скачайте папку с Гитхаба. В ней будет:
-
файл yandex_webmaster_indexing.ipynb с кодом и комментариями,
-
таблица megaposm.xlsx, которая используется в качестве примера в первом скрипте,
-
папка result c вложенными отчетами, которые получаются в результате работы скриптов для получения страниц из поисковой базы Яндекса и дальнейшего сопоставления.
Регистрация приложения
Для работы необходимо зарегистрировать приложение и получить токен, который будет использоваться для всех сервисов Яндекса, с которыми вы будет взаимодействовать через программный интерфейс.
1. Перейти по ссылке https://oauth.yandex.ru/client/new.
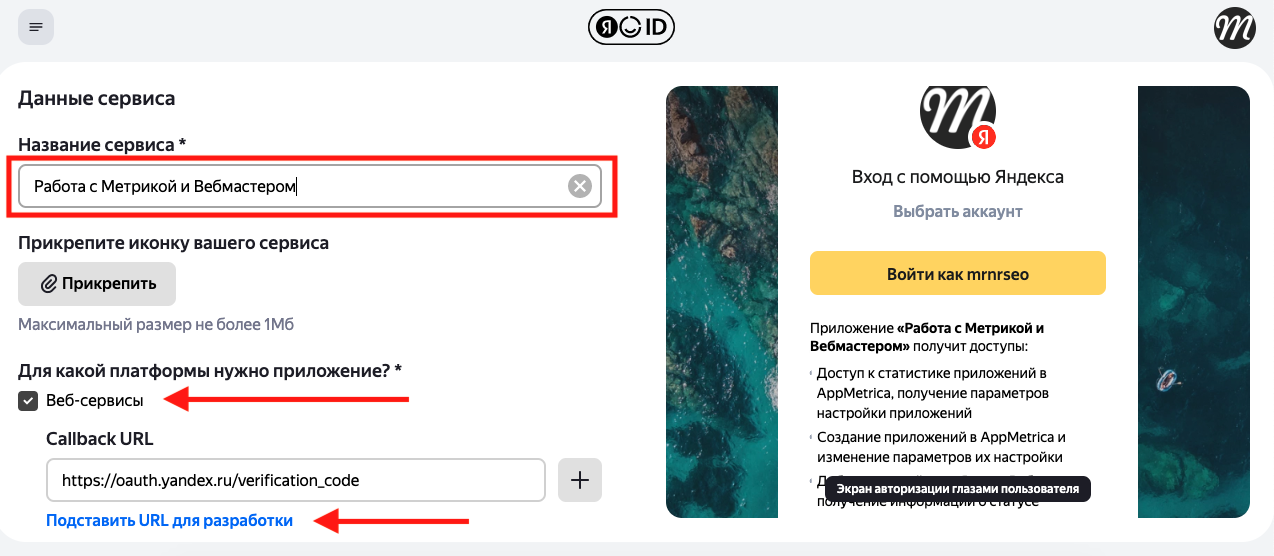
2. Создать название, выбрать «Веб-сервисы», нажать ссылку «Подставить URL для разработки»:
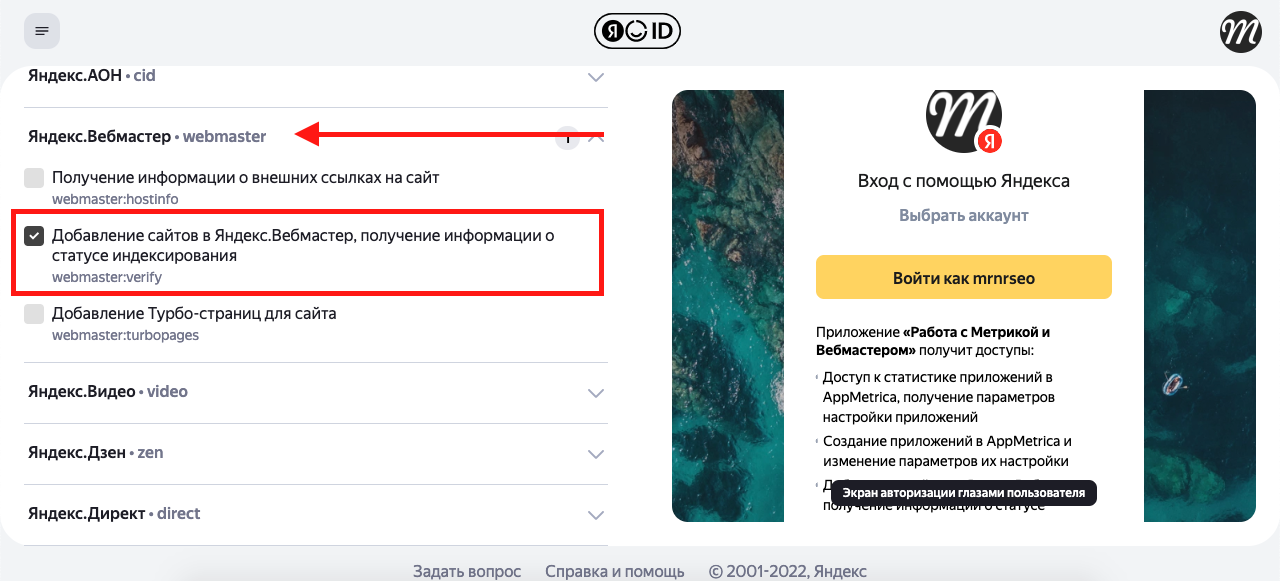
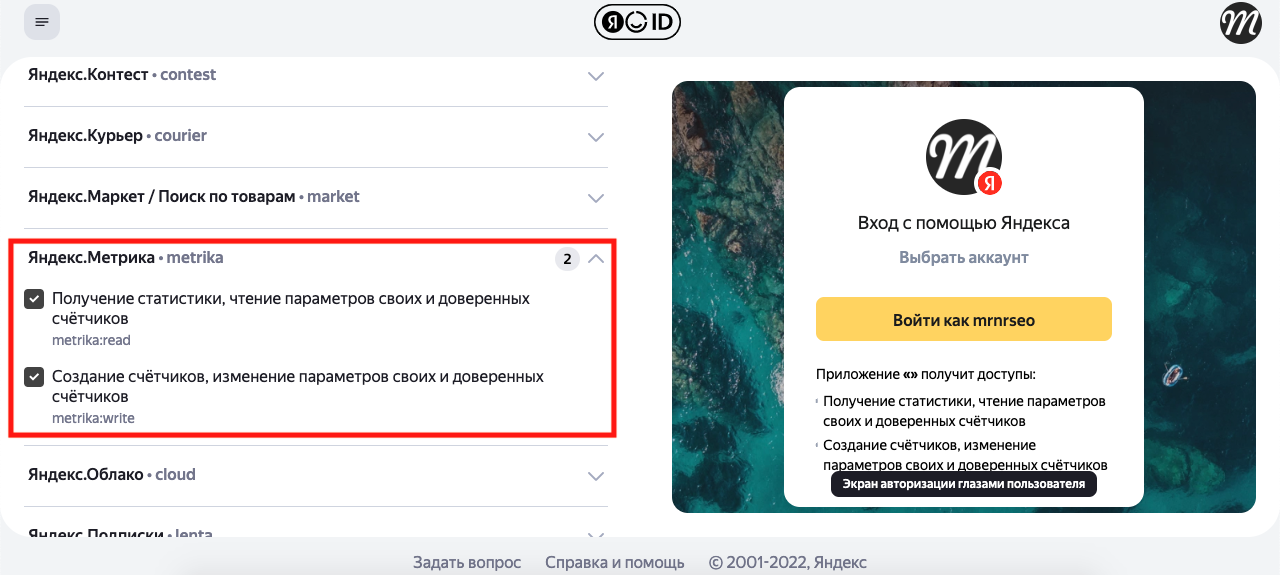
3. Отметить данные, которые нужны – ВебМастер и Яндекс Метрика:
4. Нажать «Создать приложение».
5. Скопировать Client ID:

6. Подставить Client ID в ссылку https://oauth.yandex.ru/authorize?response_type=token&client_id=Client ID Произойдет редирект на страницу с токеном.
В ссылке указано время жизни токена в секундах – 180 дней:

7. Скопировать токен и использовать в своем коде.
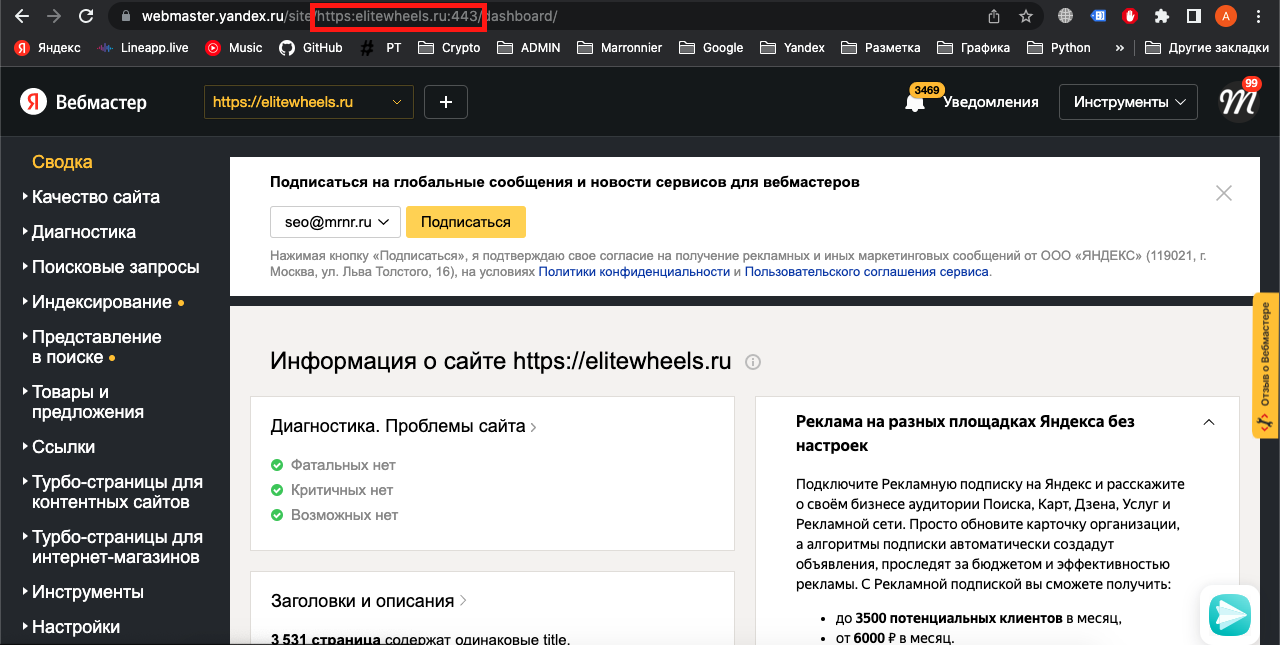
8. Скопировать host проекта и использовать в коде:
Отправка списка страниц на индексирование в Яндекс Вебмастер
Импорт библиотек
import json
import requests
import pandas as pd
Настройки
TOKEN = 'y0_AgABCAAZqca9AAaElQAAAADKLs4Yq_tVuPHCZOKIQLy3rAYljzWccks'
User id
USERID_URL = 'https://api.webmaster.yandex.net/v4/user'
Отправка на переобход
RECRAWL_URL_TEMPLATE = 'https://api.webmaster.yandex.net/v4/user/{}/hosts/{}/recrawl/queue'Параметры проекта
host = 'https:megaposm.com:443'
project_name = 'megaposm'
Загрузка URL для индексирования
Файл в формате xlsx с названием поля "urls":
table_with_urls_for_recrawl = pd.read_excel(f'{project_name}.xlsx')Отправка на индексирование
Авторизация
def get_auth_headers():
return {'Authorization': f'OAuth {TOKEN}'}
Получение user_id Яндекс Вебмастера
def get_user_id():
r = requests.get(USERID_URL, headers=get_auth_headers())
user_id = json.loads(r.text)['user_id']
return user_id
Отправка на индексирование
Функция принимает множество (set) url для отправки,
перебирает каждый url и отправляет его на переобход, пока будет получен ответ НЕ 202,
возвращает set отправленных url.
def send_urls_to_yandex_for_recrawl(data, user_id, host):
sent_urls_for_recrawl_set = set()
for url in data:
yandex_webmaster_recrawl_url = RECRAWL_URL_TEMPLATE.format(user_id, host)
url_for_recrawl = {'url': f'{url}'}
r = requests.post(yandex_webmaster_recrawl_url,
headers = get_auth_headers(),
json = url_for_recrawl
)
if r.status_code != 202:
break
sent_urls_for_recrawl_set.add(url)
sent_urls_set_len = len(sent_urls_for_recrawl_set)
print(json.loads(r.text))
print('На переобход отправлено:', sent_urls_set_len)
return sent_urls_for_recrawl_set
Удаление из списка и экспорт
Функция принимает set с со всеми адресами из загруженной таблицы и set отправленных url,
Из загруженной таблицы удаляются url, которые были отправлены. Это нужно для того, чтобы в следующий раз, когда обновится квота, эти же страницы не оправлялись на переобход.
Экспорт
def export_data_to_excel(data):
project_report = pd.ExcelWriter(f'{project_name}.xlsx', engine='xlsxwriter')
data.to_excel(project_report, index=False)
project_report.save()
Удаление и экспорт
def delete_sent_urls_and_export_new_table(main_urls_set, sent_urls_for_recrawl_set):
main_urls_set_without_sent_urls = main_urls_set - sent_urls_for_recrawl_set
rest_urls_list = list(main_urls_set_without_sent_urls)
data = pd.DataFrame({'urls': rest_urls_list})
export_data_to_excel(data)
Главная функция
Принимает датафрейм, который был загружен в начале,
преобразует датафрейм в set,
отправляет на переобход,
удаляет из общего списка отправленные url и экспортирует датафрейм.
def main_send_pages_to_yandex_for_recrawl(data):
user_id = get_user_id()
main_urls_set = set(data['urls'].to_list())
sent_urls_for_recrawl_set = send_urls_to_yandex_for_recrawl(main_urls_set, user_id, host)
delete_sent_urls_and_export_new_table(main_urls_set, sent_urls_for_recrawl_set)
Запуск
main_send_pages_to_yandex_for_recrawl(table_with_urls_for_recrawl)

Получение списка проиндексированных страниц
Импорт библиотек
import json
import requests
import os
from datetime import datetime
from bs4 import BeautifulSoup
import pandas as pd
Настройки
TOKEN = 'y0_AgABCAAZqca9AAaElQAAAADKLs4Yq_tVuPHCZOKIQLy3rAYljzWccks'
User id
USERID_URL = 'https://api.webmaster.yandex.net/v4/user'
Получение статистики по проекту
HOST_STAT_URL_TEMPLATE = 'https://api.webmaster.yandex.net/v4/user/{}/hosts/{}/summary'
Получение списка url в поисковой базе
INSEARCH_URL_TEMPLATE = 'https://api.webmaster.yandex.net/v4/user/{}/hosts/{}/search-urls/in-search/samples'Документация https://yandex.ru/dev/webmaster/doc/dg/reference/hosts-indexing-insearch-samples.html#hosts-indexing-insearch-samples.
Для получения списка страниц необходимо указать количество страниц, получаемое за одну итерацию, максимально можно указать 100.
YANDEX_PER_REQUEST_PAGE_LIMIT = 100
Параметры проекта
host = 'https:megaposm.com:443'
project_name = 'megaposm'
sitemap_path = 'https://megaposm.com/index.php?route=extension/feed/google_sitemap'
Директория для визуального отчета
YANDEX_VISUAL_REPORTS_DIR = 'results/visual_reports/yandex'
Директория для файлов со списком url на переобход
YANDEX_RECRAWL_BASES_DIR = 'results/recrawl_bases/yandex'
Получение списка страниц
Авторизация
def get_auth_headers():
return {'Authorization': f'OAuth {TOKEN}'}
Получение user_id Яндекс Вебмастера
def get_user_id():
r = requests.get(USERID_URL, headers=get_auth_headers())
user_id = json.loads(r.text)['user_id']
return user_id
Получение URL из поисковой базы
Функция принимает user id и хост,
получает число проиндексированных страниц - indexed_pages_quantity,
указаны параметры offset - смещение списка, т.е. с какой строки в списке будут получены url и limit - сколько страниц будет получено за один шаг - ранее был указан этот параметр в YANDEX_PER_REQUEST_PAGE_LIMIT,
запускается цикл while, который работает пока offser меньше числа проиндексированных страниц - indexed_pages_quantity,
запускается генератор множеств (set), в котороый добавляются полученные url,
полученный set с адресами объединяется с общим множеством indexed_pages,
к offset прибавляется число полученных url YANDEX_PER_REQUEST_PAGE_LIMIT,
функция возвращает множество indexed_pages.
def yandex_get_indexed_pages(user_id, host):
host_stat_url = HOST_STAT_URL_TEMPLATE.format(user_id, host)
insearch_url = INSEARCH_URL_TEMPLATE.format(user_id, host)
r = requests.get(host_stat_url, headers=get_auth_headers())
indexed_pages_quantity = json.loads(r.text)['searchable_pages_count']
print(f'В поисковой базе содержится {indexed_pages_quantity} страниц',)
indexed_pages = set()
params = {'offset': 0, 'limit': YANDEX_PER_REQUEST_PAGE_LIMIT}
while params['offset'] < indexed_pages_quantity:
r = requests.get(insearch_url, headers=get_auth_headers(), params=params)
current_urls = {element['url'] for element in json.loads(r.text)['samples']}
indexed_pages = indexed_pages.union(current_urls)
params['offset'] += YANDEX_PER_REQUEST_PAGE_LIMIT
return indexed_pages
Отмечу, что Яндекс Вебмастер предоставляет только 50 000 строк с url, которые хранятся в его базе. Если на сайте больше страниц, то дальнейшее сопоставление даст некорректные результаты.
Сопоставление полученных url из Вебмастера с актуальными адресами на сайте
Функция yandex_get_indexed_pages возвращает set для удобного сопоставления с url, которые у вас на сайте.
Актуальный список url вы можете получить при парсинге краулером, например Comparser. Затем загрузите таблицу, например с названием поля 'urls', где будут перечислены адреса:
parsed_urls = pd.read_excel(f'{project_name}.xlsx')Конвертация в set:
site_pages = set(parsed_urls['urls'])
Далее для сопоставления я буду использовать адреса из sitemap.
Парсинг Sitemap
Можно указать user agent, чтобы парсер не получил ответ 403 из-за настроек сервера или CDN, например CloudFlare:
user_agent = {'User-agent': 'Mozilla/5.0'}Одна карта
Функция принимает адрес карты сайта,
парсит,
возвращает set с адресами из карты сайта.
def parse_sitemap_one_map(sitemap_path):
r = requests.get(sitemap_path, headers=user_agent)
soup = BeautifulSoup(r.text, 'xml')
url_set = {url.text for url in soup.find_all('loc')}
print('Количество страниц в Sitemap:', len(url_set))
return url_set
Мультакарта
Функция принимает адрес карты сайта,
парсит, получает список вложенных карт,
парсит по очереди вложенные карты,
возвращает set со всеми адресами из мультикарты.
def parse_sitemap_many_maps(sitemap_path):
r = requests.get(sitemap_path, headers=user_agent)
soup = BeautifulSoup(r.text, 'xml')
maps = [sitemap.text for sitemap in soup.find_all('loc')]
url_set = set()
for sitemap in maps:
r = requests.get(sitemap, headers=user_agent)
soup = BeautifulSoup(r.text, 'xml')
current_urls = {url.text for url in soup.find_all('loc')}
url_set = url_set.union(current_urls)
print('Количество страниц в Sitemap:', len(url_set))
return url_set
Сопоставление адресов из базы Яндекса с адресами из Sitemap
Сопоставление
Функция принимает set с адресами из базы Яндекса и set с адресами из карты сайта,
в pages_in_index_but_not_in_sitemap записываются адреса, которые есть в поисковой базе, но отсутствуют в карте сайта,
в pages_is_sitemap_but_not_in_index записываются адреса, которые есть в карте сайта, но отсутствуют в поисковой базе,
оба отчета записываются в соседние колонки датафрейма для дальнейшего визуального сопоставления,
функция возвращает датафрейм.
def comapre_indexed_pages_with_pages_in_sitemap(indexed_pages, pages_in_sitemap):
pages_in_index_but_not_in_sitemap = indexed_pages - pages_in_sitemap
pages_is_sitemap_but_not_in_index = pages_in_sitemap - indexed_pages
pages_in_index_but_not_in_sitemap_df = pd.DataFrame(
pages_in_index_but_not_in_sitemap,
columns=['pages_in_index_but_not_in_sitemap']
)
pages_is_sitemap_but_not_in_index_df = pd.DataFrame(
pages_is_sitemap_but_not_in_index,
columns=['pages_is_sitemap_but_not_in_index']
)
df = pd.concat([pages_in_index_but_not_in_sitemap_df, pages_is_sitemap_but_not_in_index_df], axis=1)
return df
Создание визуального отчета в таблице
Функция с настройками для экспорта
def export_report_data_to_excel(data, path, filename):
os.makedirs(path, exist_ok=True)
project_report = pd.ExcelWriter(os.path.join(path, filename), engine='xlsxwriter')
data.to_excel(project_report, index=False)
project_report.save()
Экспорт визуального отчета
Функция принимает название проекта, путь, по которому будет лежать отчет, set с url в индексе, set url из карты сайта,
затем запускается функция сопоставления и запись датафрейма в data,
экспортируется файл, название которого состоит из названия проекта и даты отчета.
def make_visual_report_for_yandex(project_name, path, indexed_pages, pages_in_sitemap):
data = comapre_indexed_pages_with_pages_in_sitemap(indexed_pages, pages_in_sitemap)
current_date = datetime.now().strftime('%d_%m_%Y')
filename = f'{project_name}_{current_date}.xlsx'
export_report_data_to_excel(data, path, filename)
Экспорт визуального отчета для сайтов с мультикартой
def make_visual_report_for_yandex_for_many_maps(project_name, path, indexed_pages, pages_in_sitemap):
data = comapre_indexed_pages_with_pages_in_sitemap(indexed_pages, pages_in_sitemap)
current_date = datetime.now().strftime('%d_%m_%Y')
filename = f'{project_name}_{current_date}.csv'
data.to_csv(f'{path}/{filename}', index=False)
Модуль os создает директорию, которая была указана в настройках, если ее нет:
Отчет для визуального сопоставления содержит две колонки:
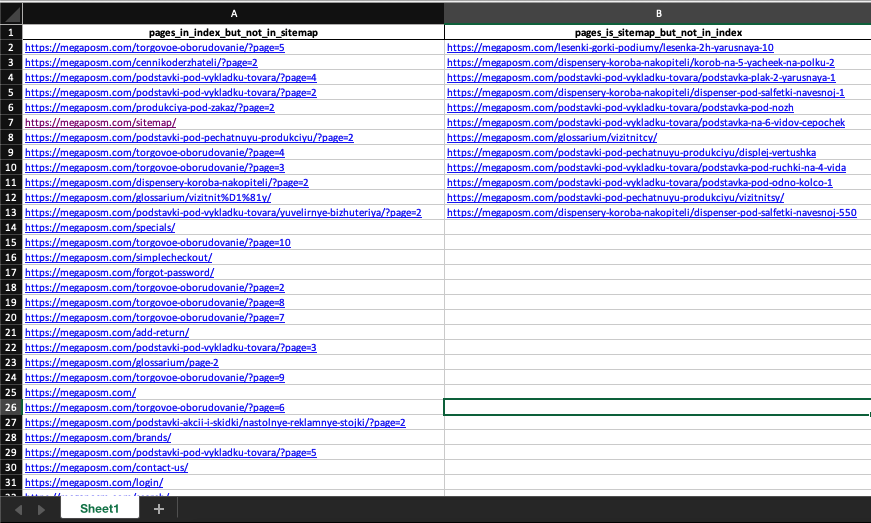
Страницы, которые есть в индексе, но отсутствуют в карте сайта – тут можно найти дубли, которые образованы параметрами, затем добавить параметры в robots.txt в Clean-param. Минусом парсинга карты сайта для сопоставления является возможное отсутствие в ней каких-нибудь побочных страниц (новости, контакты, информация о работе и т.д.) и пагинации, которую я рекомендую не закрывать от индексирования – подробнее. Так всегда будет несоответствие в отчете, но при быстром просмотре вы быстро распознаете «законное» несоответствие и реальные дубли.
Страницы, которые если в карте сайта, но отсутствуют в индексе – эти страницы почему-то были не проиндексированы, нужно отправить на переобход.
Создание списка на переобход
Похожая функция как для сопоставления, которая принимает set с адресами из базы Яндекса и set с адресами из карты сайта,
в pages_in_index_but_not_in_sitemap записываются адреса, которые есть в поисковой базе, но отсутствуют в карте сайта,
в pages_is_sitemap_but_not_in_index записываются адреса, которые есть в карте сайта, но отсутствуют в поисковой базе,
оба отчета записываются в одну колонку для отправки на переобход,
функция возвращает датафрейм.
def get_recrawl_base_for_yandex(indexed_pages, pages_in_sitemap):
pages_in_index_but_not_in_sitemap = indexed_pages - pages_in_sitemap
pages_is_sitemap_but_not_in_index = pages_in_sitemap - indexed_pages
all_pages_to_recrawl = list(pages_in_index_but_not_in_sitemap.union(pages_is_sitemap_but_not_in_index))
data = pd.DataFrame(all_pages_to_recrawl, columns=['urls'])
return data
Экспорт таблицы со списком на переобход
def make_recrawl_base_for_yandex(project_name, path, indexed_pages, pages_in_sitemap):
data = get_recrawl_base_for_yandex(indexed_pages, pages_in_sitemap)
filename = f'{project_name}.xlsx'
export_report_data_to_excel(data, path, filename)
Экспорт таблицы со списком на переобход для сайтов с мультикартой
def make_recrawl_base_for_yandex_many_maps(project_name, path, indexed_pages, pages_in_sitemap):
data = get_recrawl_base_for_yandex(indexed_pages, pages_in_sitemap)
filename = f'{project_name}.csv'
data.to_csv(f'{path}/{filename}', index=False)
Директория, которая указана в настройках, создается модулем os, если ее нет:
Список на переобход:
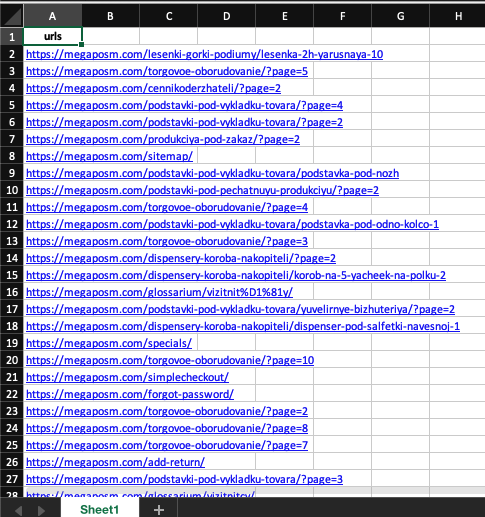
В списке просто объединены url,которые содержатся в двух колонках в визуальном отчете.
Главная функция
def main_yandex_index_sitemap_compare():
user_id = get_user_id()
print(project_name)
indexed_pages = yandex_get_indexed_pages(user_id, host)
pages_in_sitemap = parse_sitemap_one_map(sitemap_path)
print('Подготовка визуального отчета')
make_visual_report_for_yandex(project_name, YANDEX_VISUAL_REPORTS_DIR, indexed_pages, pages_in_sitemap)
print('Подготовка таблицы со списком url на переобход')
make_recrawl_base_for_yandex(project_name, YANDEX_RECRAWL_BASES_DIR, indexed_pages, pages_in_sitemap)
Запуск
main_yandex_index_sitemap_compare()




