Автоматизация - Получение данных о трафике из поисковых систем с использованием API Яндекс Метрики
Содержание:
- Как использовать код из статьи
- Подготовка
- Получение данных из API Яндекс Метрики
- Импорт библиотек
- Общие функции
- Часть 1: Получение количества визитов
- Первый запрос для демонстрации получаемых данных
- Получение количества визитов за период из всех поисковых систем
- Получение количества визитов за период из какой-либо поисковой системы
- Визуализация
- Часть 2: Получение визитов по страницам входа, анализ распределения
- Распределение за период
- Пример 1: распределение трафика da-vita.ru
- Пример 2: распределение трафика kolesa-v-pitere.ru
- Распределение по месяцам
- Пример 1: распределение трафика da-vita.ru
- Пример 2: распределение трафика kolesa-v-pitere.ru
- Часть 3: Получение визитов по страницам входа, анализ динамики трафика по каждому URL
- Пример 1: динамика трафика по URL da-vita.ru
- Пример 2: динамика трафика по URL kolesa-v-pitere.ru
Как использовать код из статьи
Установите питон и нужные библиотеки или сборку библиотек Anaconda.
Скачайте папку с Гитхаба. В ней будет:
-
Файл с кодом yandex_metrika_api_get_search_engines_data.ipynb.
-
Таблицы kvp_products_aliases.csv, kvp_categories_aliases.csv, kvp_filters_aliases.csv, которые используются для определения типов страниц в одном из примеров.
-
Таблица report_table.csv с данными о трафике, которые получаются в результате работы кода.
Подготовка
Чтобы приступить к работе, вам необходимо зарегистрировать приложение и получить токен. Этот процесс описан в статье Автоматизация - Индексирование сайтов с помощью Яндекс Вебмастер API на Python.
Получение данных из API Яндекс Метрики
Импорт библиотек
import requests
import json
import numpy as np
import pandas as pd
from pandas.tseries.offsets import MonthEnd
from matplotlib import pyplot as plt
import matplotlib.dates as mdates
Токен
YANDEX_TOKEN = 'y0_AgAAAAASqca9YYaElQFFFFDf0c6gbPilbUJpQl-OVox2FC5UvOMecnNO'
Адрес ресурса
METRIKA_URL_TEMPLATE = 'https://api-metrika.yandex.net/stat/v1/data'
Документация https://yandex.ru/dev/metrika/doc/api2/api_v1/intro.html.
Общие функции
Эти функции будут использоваться в скриптах ниже.
Авторизация
def get_auth_headers():
return {'Authorization': f'OAuth {YANDEX_TOKEN}'}
Открывание таблицы с отчетом
Функция открывает csv с названием, которое указано в REPORT_TABLE_NAME. Если такой таблицы нет, создается таблица с нужными полями и открывается:
def open_csv():
try:
table = pd.read_csv(REPORT_TABLE_NAME)
return table.to_dict('records')
except:
report_table = {}
report_table['data_type'] = np.nan
report_table['value'] = np.nan
report_table['date'] = np.nan
report_table['week_number_year'] = np.nan
report_table['month_year'] = np.nan
table_template = pd.DataFrame(report_table, index=[0])
table_template.to_csv(REPORT_TABLE_NAME, index=False)
table = pd.read_csv(REPORT_TABLE_NAME)
return table.to_dict('records')
Создание отчета
Принимает открытую функцией open_csv таблицу, тип значение - например все поисковые системы, переходы из яндекса и т.д., количество переходом, дату, день, номер недели, название месяца, год. Все записывается в датафрейм pandas, потом экспортируется:
def create_report(report_table, data_type, value, date, week_number_year, month_year):
d={}
d['data_type'] = data_type
d['value'] = value
d['date'] = date
d['week_number_year'] = week_number_year
d['month_year'] = month_year
report_table.append(d)
result_table = pd.DataFrame.from_dict(report_table)
result_table.dropna(inplace=True)
result_table['value'] = result_table['value'].astype(int)
result_table.to_csv(REPORT_TABLE_NAME, index=False)
Дополнительно все поля, содержащие числовые значения приводятся к формату целых чисел.
Часть 1: Получение количества визитов
Id счетчика метрики:
PROJECT_COUNTER_ID = 44771542
Название таблицы для записи полученных данных:
REPORT_TABLE_NAME = 'report_table.csv'
Первый запрос для демонстрации получаемых данных
Дата:
date = '2020-12-31'
Группировка (dimensions) - поисковые системы, метрика (metrics) - визиты, атрибуция - последний значимый переход кросс девайс:
DIMENSIONS = 'ym:s:searchEngine'
METRICS = 'ym:s:visits'
ATTRIBUTION = 'cross_device_last_significant'
Функция для отправки параметров
Принимает дату и счетчик метрики:
def metrika_get_params(current_date, project_yandex_metrika_counter_id):
return {
'id': project_yandex_metrika_counter_id,
'date1': current_date,
'date2': current_date,
'dimensions': DIMENSIONS,
'attribution': ATTRIBUTION,
'sampled': False,
'metrics': METRICS,
}
Запрос
request = requests.get(METRIKA_URL_TEMPLATE,
headers=get_auth_headers(),
params=metrika_get_params(date, PROJECT_COUNTER_ID))
Ответ:

Результат за 1 день - 31 декабря 2020 года. Ключ data содержит информацию о том, из каких поисковых систем сколько раз совершались переходы. Обратите внимание, что переходы из поиска Яндекса, переходы из мобильного поиска Яндекса, переходы из мобильного приложения поиска Яндекса, переходы из картинок Яндекса, переходы с карт Яндекса определяются как отдельные источники. Общее количество переходов отражено в ключе total - 1339.
В интерфейсе этот отчет выглядит так:
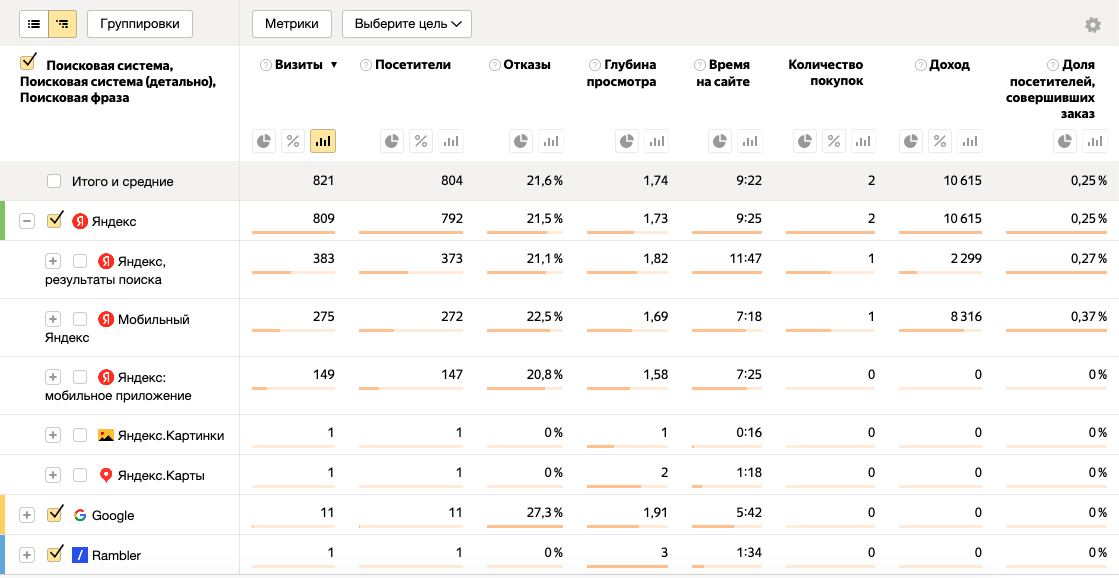
Получение количества визитов за период из всех поисковых систем
Даты:
date_from = '2019-01-01'
date_to = '2020-12-31'
Такие же параметры, как в примере выше. Группировка (dimensions) - поисковые системы, метрика (metrics) - визиты, атрибуция - последний значимый переход кросс девайс:
DIMENSIONS = 'ym:s:searchEngine'
METRICS = 'ym:s:visits'
ATTRIBUTION = 'cross_device_last_significant'
Функция для отправки параметров
Принимает дату и счетчик Метрики:
def metrika_get_params(current_date, project_yandex_metrika_counter_id):
return {
'id': project_yandex_metrika_counter_id,
'date1': current_date,
'date2': current_date,
'dimensions': DIMENSIONS,
'attribution': ATTRIBUTION,
'sampled': False,
'metrics': METRICS,
}
Функция для получения данных из метрики и формирования отчета
Принимает дату, номер счетчика. Для отчета полная дата конвертируется в строку, из даты определяется день, номер недели в году, название месяца и год, и все записывается в разные поля:
def get_all_search_engine_data_and_report(current_date, project_yandex_metrika_counter_id):
request = requests.get(METRIKA_URL_TEMPLATE,
headers=get_auth_headers(),
params=metrika_get_params(current_date, project_yandex_metrika_counter_id))
request_data = json.loads(request.text)
se_visits_quantity = request_data['totals'][0]
date = current_date.strftime('%d-%m-%Y')
week_number_year = current_date.strftime('%W %Y')
month_year = current_date.strftime('%B %Y')
report_table = open_csv()
create_report(report_table, 'se_all', se_visits_quantity, date, week_number_year, month_year)
Запуск
for day in pd.period_range(start=date_from,end=date_to, freq='D'):
get_all_search_engine_data_and_report(day, PROJECT_COUNTER_ID)
Просмотр созданного отчета в csv
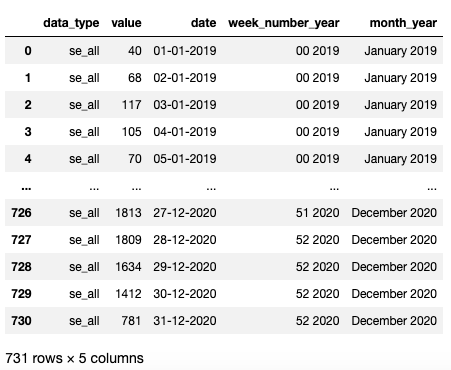
Получение количества визитов за период из какой-либо поисковой системы
Даты:
date_from = '2019-01-01'
date_to = '2020-12-31'
Такие же параметры, как в примере выше. Группировка (dimensions) - поисковые системы, метрика (metrics) - визиты, атрибуция - последний значимый переход кросс девайс, фильтрация (filters) по названию поисковой системы:
DIMENSIONS = 'ym:s:searchEngine'
ATTRIBUTION = 'cross_device_last_significant'
METRICS = 'ym:s:visits'
FILTERS = "ym:s:SearchEngineName=*'{}*'"
Функция для отправки параметров
Принимает дату, название поисковика и счетчик метрики:
def metrika_get_params(current_date, search_engine_name, project_yandex_metrika_counter_id):
return {
'id': project_yandex_metrika_counter_id,
'date1': current_date,
'date2': current_date,
'dimensions': DIMENSIONS,
'attribution': ATTRIBUTION,
'sampled': False,
'metrics': METRICS,
'filters': FILTERS.format(search_engine_name)
}
Функция для получения данных из метрики по названию ПС и формирования отчета
Принимает дату, название поисковика, номер счетчика. Для отчета полная дата конвертируется в строку, из даты определяется день, номер недели в году, название месяца и год, и все записывается в разные поля:
def get_current_search_engine_data_and_report(current_date, search_engine_name,
project_yandex_metrika_counter_id):
request = requests.get(METRIKA_URL_TEMPLATE,
headers=get_auth_headers(),
params=metrika_get_params(current_date, search_engine_name,
project_yandex_metrika_counter_id))
request_data = json.loads(request.text)
se_visits_quantity = request_data['totals'][0]
date = current_date.strftime('%Y-%m-%d')
week_number_year = current_date.strftime('%W %Y')
month_year = current_date.strftime('%B %Y')
report_table = open_csv()
create_report(report_table, search_engine_name, se_visits_quantity, date, week_number_year, month_year)
Запуск
Получение количества визитов из Яндекса
for day in pd.period_range(start=date_from,end=date_to, freq='D'):
get_current_search_engine_data_and_report(day, 'yandex', PROJECT_COUNTER_ID)
Просмотр созданного отчета в csv
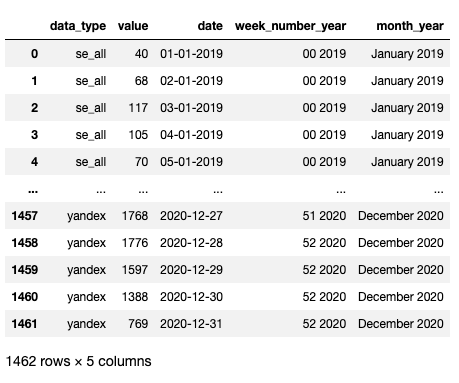
Получение количества визитов из Google
for day in pd.period_range(start=date_from,end=date_to, freq='D'):
get_current_search_engine_data_and_report(day, 'google', PROJECT_COUNTER_ID)
Просмотр созданного отчета в csv
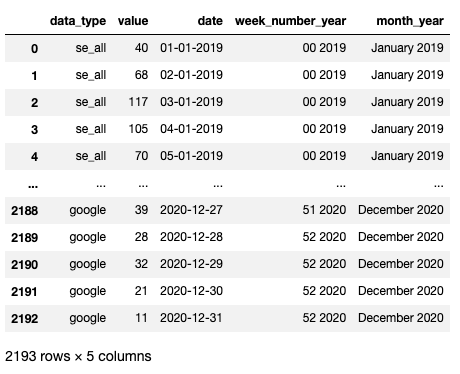
Визуализация
Загрузка таблицы
df = pd.read_csv(REPORT_TABLE_NAME)
Срез по всем поисковым системам
se_all_slice = df[df['data_type'] == 'se_all']
Линейный график
В срезе по всем поисковым системам находятся данные по трафику за каждый день за период 2019-2020 гг. Если построить график с детализацией по дням, получится нечитаемая картина:
with plt.style.context('fivethirtyeight'):
plt.figure(figsize=(15,7))
dates_x = se_all_slice['date']
values_y = se_all_slice['value']
plt.plot(dates_x, values_y, color='mediumslateblue')
plt.xticks(rotation=90, fontsize=16)
plt.title('Все поисковые системы')
plt.ylabel('Количество визитов')
plt.xlabel('Дата')
plt.tight_layout()
plt.savefig(f'traffic-from-all-search-engines.png')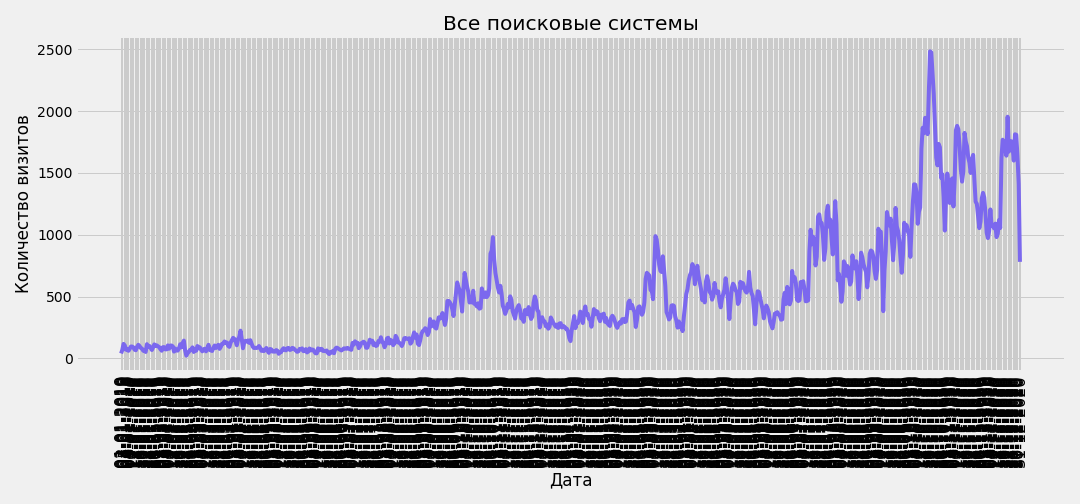
Группировка по месяцам
Для этого на этапе получения данных из Метрики было подготовлено поле month_year. Теперь можно сгруппировать данные по трафику по месяцам:
by_month = se_all_slice.pivot_table(index='month_year', values='value',
aggfunc='sum', sort=False).reset_index()
with plt.style.context('fivethirtyeight'):
plt.figure(figsize=(15,7))
dates_x = by_month['month_year']
values_y = by_month['value']
plt.plot(dates_x, values_y, color='mediumslateblue')
plt.xticks(rotation=90, fontsize=16)
plt.title('Все поисковые системы')
plt.ylabel('Количество визитов')
plt.xlabel('Месяц и год')
plt.tight_layout()
plt.savefig(f'traffic-from-all-search-engines-by-months.png')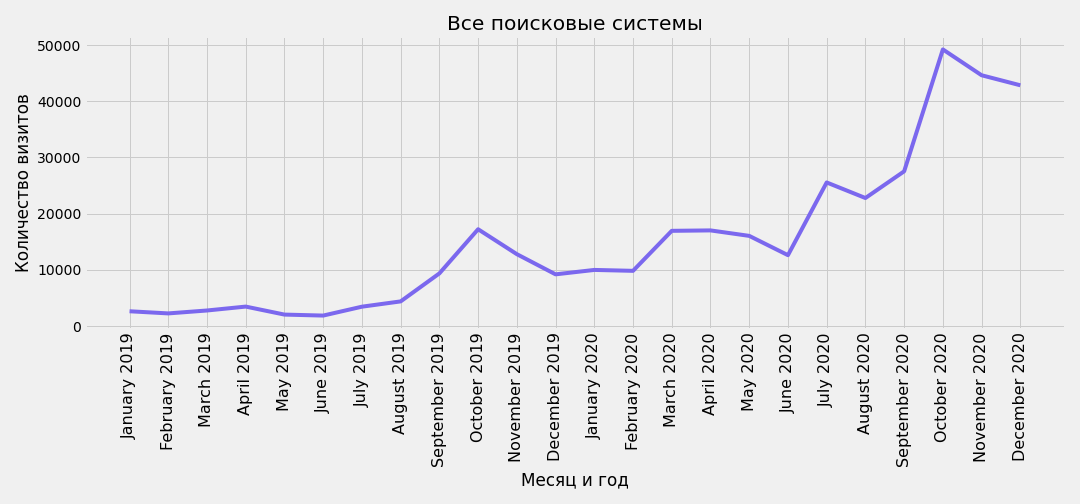
Группировка по неделям
Также на этапе получения данных было подготовлено поле с номером недели в году week_number_year:
by_week = se_all_slice.pivot_table(index='week_number_year', values='value',
aggfunc='sum', sort=False).reset_index()
Если запустить график без дополнительных настроек, на оси X номера недель слипнутся. На 9 и 10 строке написаны настройки, с помощью которых количество подписей на оси X будет сокращено автоматически. Попробуйте менять параметры в AutoDateLocator - minticks и maxticks:
with plt.style.context('fivethirtyeight'):
plt.figure(figsize=(15,7))
dates_x = by_week['week_number_year']
values_y = by_week['value']
plt.plot(dates_x, values_y, color='mediumslateblue')
plt.rcParams['date.converter'] = 'concise'
plt.gca().xaxis.set_major_locator(mdates.AutoDateLocator(minticks=10, maxticks=58))
plt.xticks(rotation=90, fontsize=16)
plt.title('Все поисковые системы')
plt.ylabel('Количество визитов')
plt.xlabel('Номер недели и год')
plt.tight_layout()
plt.savefig(f'traffic-from-all-search-engines-by-weeks.png')
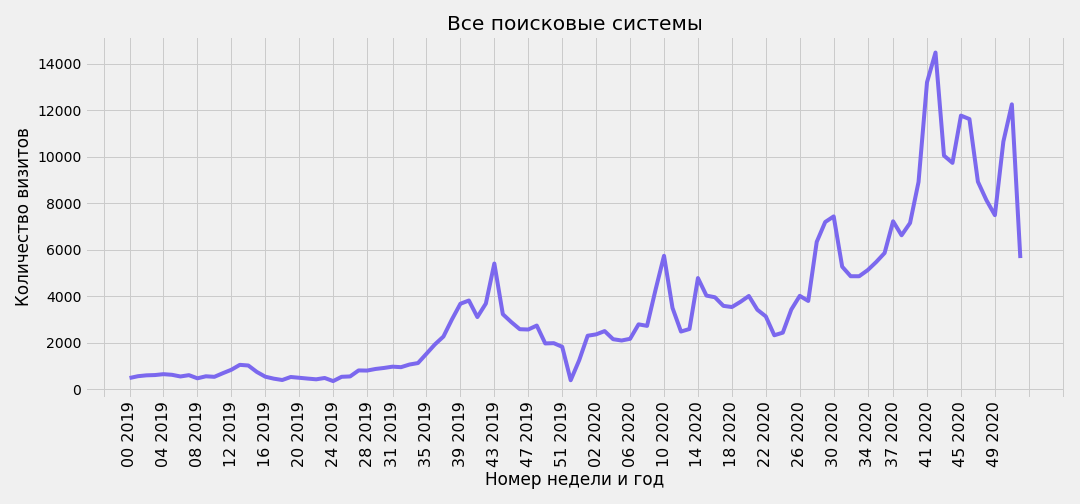
Вывод данных по дням
В первом примере на графике был выбран двухлетний период, и данные по дням выглядели нечитаемо. Чтобы лучше визуализироть данные по дням, нужно взять более короткий период.
Можно сделать срез за какой-либо определенный месяц, например за декабрь 2020:
selected_month = se_all_slice[se_all_slice['month_year'] == 'December 2020']
with plt.style.context('fivethirtyeight'):
plt.figure(figsize=(15,7))
dates_x = selected_month['date']
values_y = selected_month['value']
plt.plot(dates_x, values_y, color='mediumslateblue')
plt.xticks(rotation=90, fontsize=16)
plt.title('Все поисковые системы')
plt.ylabel('Количество визитов')
plt.xlabel('Декабрь 2020')
plt.tight_layout()
plt.savefig(f'traffic-from-all-search-engines-december-2020.png')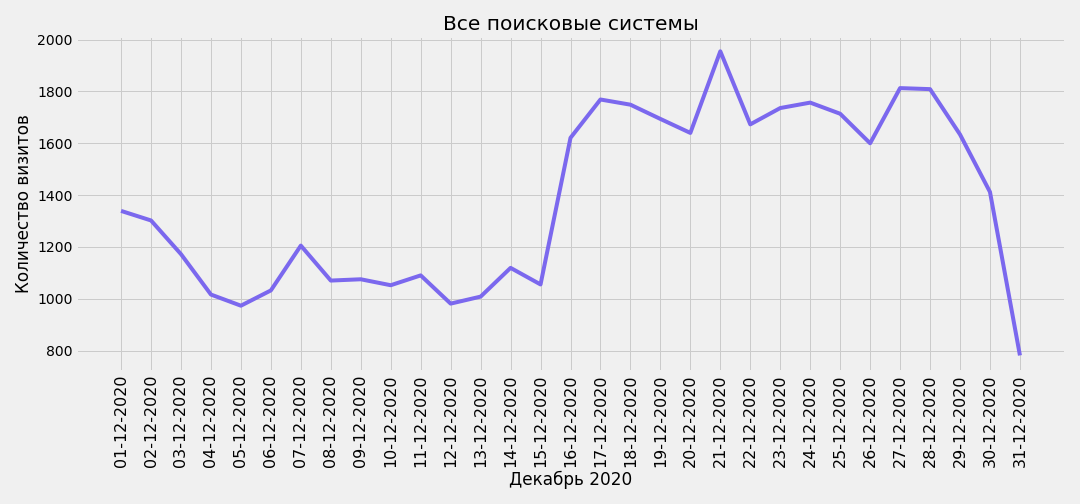
Можно сделать срез из произвольного периода, для этого нужно знать индекс первой и последней строки в срезе, например срез с первого января до середины февраля 2019 года:
selected_period = se_all_slice.iloc[0:45]
with plt.style.context('fivethirtyeight'):
plt.figure(figsize=(15,7))
dates_x = selected_period['date']
values_y = selected_period['value']
plt.plot(dates_x, values_y, color='mediumslateblue')
plt.xticks(rotation=90, fontsize=16)
plt.title('Все поисковые системы')
plt.ylabel('Количество визитов')
plt.xlabel('Январь - Февраль 2019')
plt.tight_layout()
plt.savefig(f'traffic-from-all-search-engines-period.png')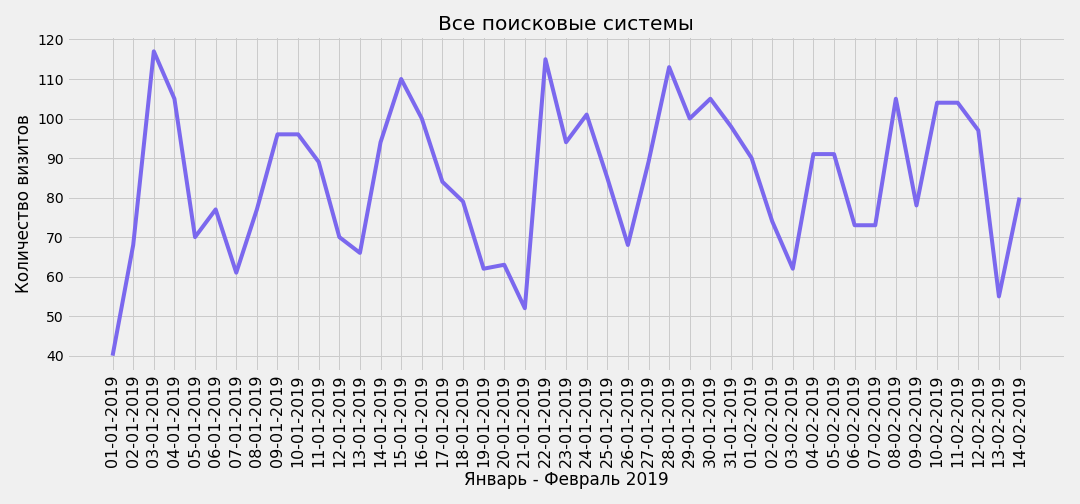
Вместо данных о трафике из всех поисковых систем, можно детализироваться по конкретной. Например, визуализация трафика из Яндекса, сгруппированного по месяцам:
yandex_slice = df[df['data_type'] == 'yandex']
yandex_by_month = yandex_slice.pivot_table(index='month_year', values='value',
aggfunc='sum', sort=False).reset_index()
with plt.style.context('fivethirtyeight'):
plt.figure(figsize=(15,7))
dates_x = yandex_by_month['month_year']
values_y = yandex_by_month['value']
plt.plot(dates_x, values_y, color='firebrick')
plt.xticks(rotation=90, fontsize=16)
plt.title('Яндекс')
plt.ylabel('Количество визитов')
plt.xlabel('Месяц и год')
plt.tight_layout()
plt.savefig(f'traffic-from-yandex.png')

Столчатый график
Вместо линейного графика можно использовать столбчатый. Например, трафик из всех поисковых систем, сгруппированный по месяцам:
with plt.style.context('fivethirtyeight'):
plt.figure(figsize=(15,7))
dates_x = by_month['month_year']
values_y = by_month['value']
plt.bar(dates_x, values_y, color='mediumslateblue')
plt.xticks(rotation=90, fontsize=16)
plt.title('Все поисковые системы')
plt.ylabel('Количество визитов')
plt.xlabel('Месяц и год')
plt.tight_layout()
plt.savefig(f'traffic-from-all-search-engines-by-moths-bar-chart.png')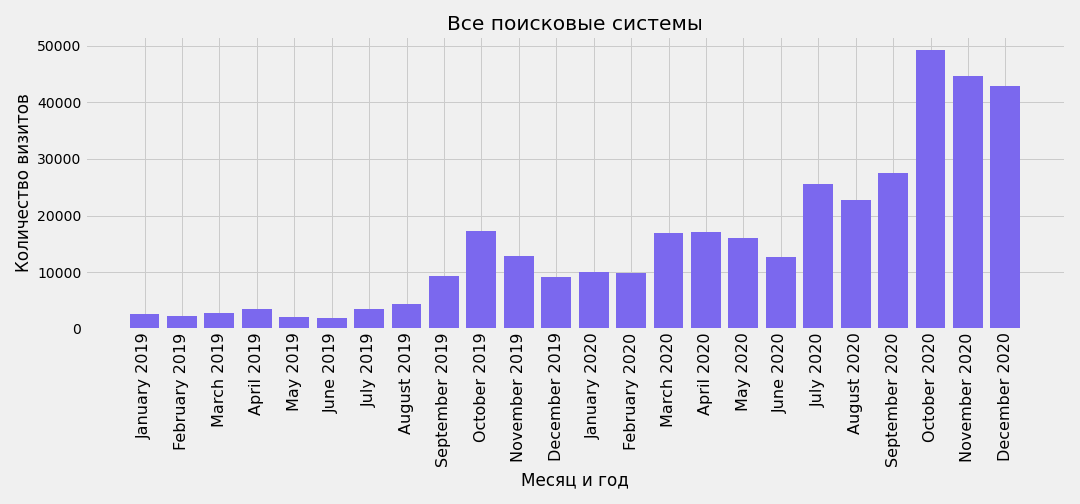
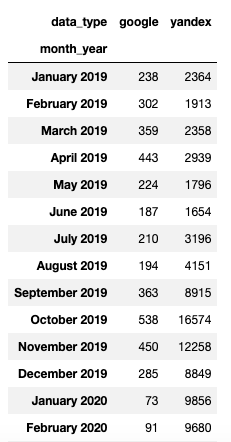
Сравнение трафика из Яндекса и Google
Срез по названиям поисковых систем:
yandx_and_google_slice = df[(df['data_type']=='yandex') | (df['data_type']=='google')]
Сводная таблица по полю Месяц и год (month_year) и сумме визитов из каждой поисковой системы (data_type):
yandx_and_google_slice_pivot = yandx_and_google_slice.pivot_table(index='month_year', columns='data_type',
values='value',aggfunc='sum',sort=False)
with plt.style.context('fivethirtyeight'):
yandx_and_google_slice_pivot.plot(kind='bar', figsize=(25,7))
plt.xticks(rotation=90, fontsize=16)
plt.legend(prop={'size': 20})
plt.title('Сравнение трафика из Яндекса и Google', fontsize=26)
plt.ylabel('Количество визитов')
plt.xlabel('Месяц и год')
plt.tight_layout()
plt.savefig(f'traffic-from-yandex-google-comparison.png')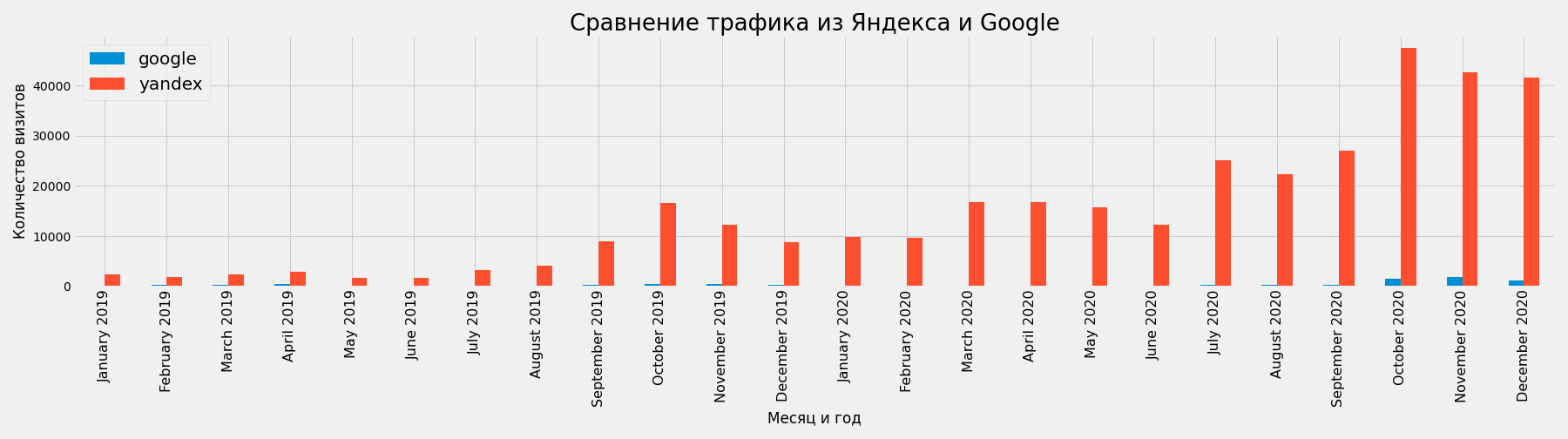
Сравнение трафика по месяцам за разные годы
Для демонстрации будет использован подготовленный ранее срез по трафику из всех поисковых систем se_all_slice.
Для получения нужных параметров, необходимо привести даты в формат datetime:
se_all_slice['date'] = pd.to_datetime(se_all_slice['date'], format='%d-%m-%Y')
В отдельные поля нужно выделить год и название месяца:
se_all_slice['year'] = se_all_slice['date'].dt.year
se_all_slice['month_name'] = se_all_slice['date'].dt.strftime('%B')se_all_slice_pivot = se_all_slice.pivot_table(index='month_name', columns='year',
values='value',aggfunc='sum',sort=False)
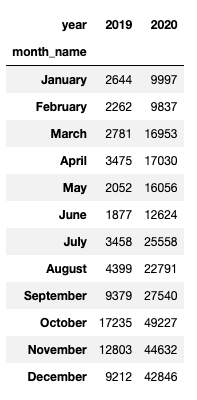
with plt.style.context('fivethirtyeight'):
se_all_slice_pivot.plot(kind='bar', figsize=(25,10))
plt.xticks(rotation=90, fontsize=16)
plt.legend(prop={'size': 20})
plt.title('Сравнение трафика по месяцам из всех ПС', fontsize=26)
plt.ylabel('Количество визитов')
plt.xlabel('Месяц и год')
plt.tight_layout()
plt.savefig(f'traffic-2019-2020-comparison.png')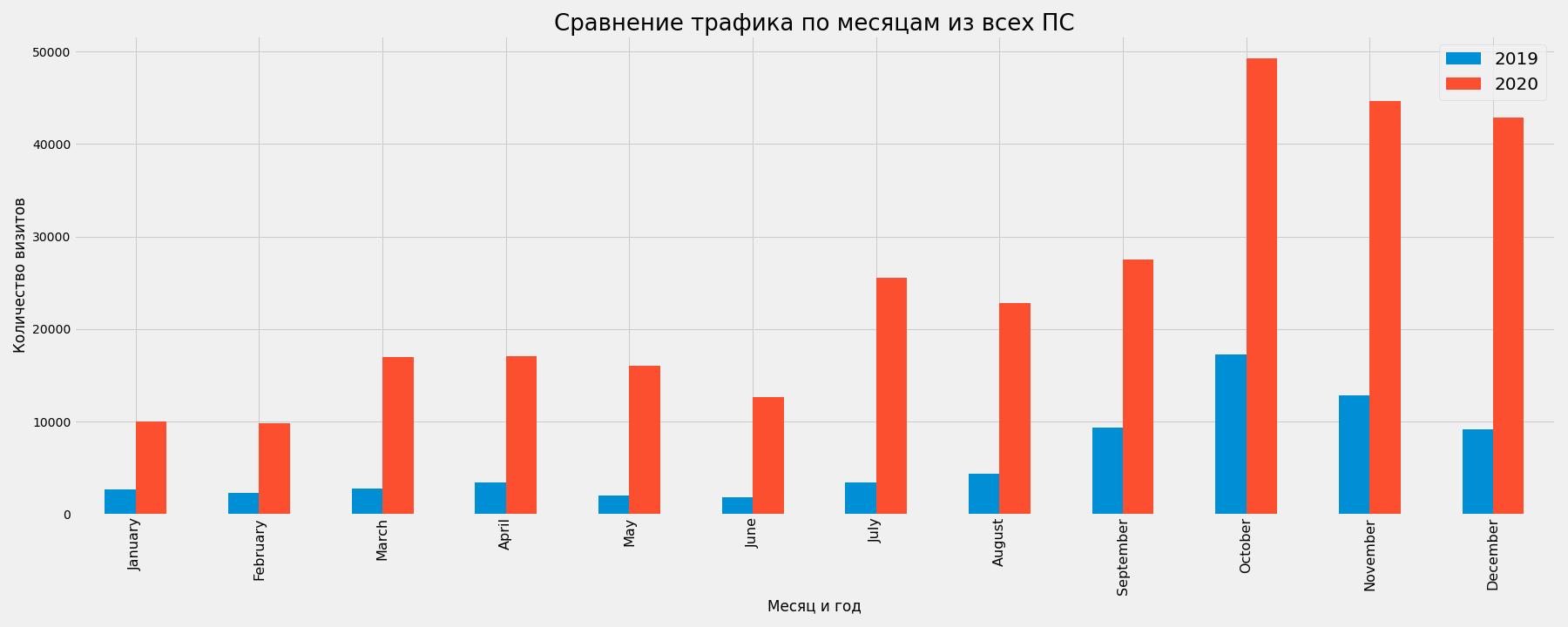
Часть 2: Получение визитов по страницам входа, анализ распределения
Параметры:
LIMIT = 100000
DIMENSIONS = 'ym:s:startURL'
METRICS = 'ym:s:visits'
ATTRIBUTION = 'cross_device_last_significant'
FILTERS = "ym:s:LastSignTrafficSource=='organic'"
Функция для отправки параметров
Принимает счетчик метрики, начальную и конечную дату:
def metrika_get_params_for_start_urls(project_yandex_metrika_counter_id, date_from, date_to):
return {
'id': project_yandex_metrika_counter_id,
'date1': date_from,
'date2': date_to,
'attribution': ATTRIBUTION,
'sampled': False,
'limit': LIMIT,
'dimensions': DIMENSIONS,
'metrics': METRICS,
'filters': FILTERS
}
Функция для получения данных из Метрики
Принимает счетчик метрики, начальную и конечную дату. Возвращает страницы входа и количество визитов за период по каждой странице:
def get_search_engine_start_urls_data_from_metrika_api(project_yandex_metrika_counter_id, date_from, date_to):
request = requests.get(METRIKA_URL_TEMPLATE,
headers=get_auth_headers(),
params=metrika_get_params_for_start_urls(project_yandex_metrika_counter_id,
date_from, date_to))
request_data = json.loads(request.text)
return request_data['data']
Функция для создания таблицы
Принимает полученные из Метрики данные, преобразует их в таблицу (датафрейм):
def extract_urls_and_visits_quantity(data):
pages_list = []
visits = []
for element in range(len(data)):
pages_list.append(data[element]['dimensions'][0]['name'])
visits.append(data[element]['metrics'][0])
df = pd.DataFrame({'urls': pages_list,
'visits_quantity': visits
})
df['visits_quantity'] = df['visits_quantity'].astype(int)
return df
Распределение за период
В этом разделе будут получены данные за указанный период, определены типы страниц и визуализированы на круговой диаграмме.
Функция для создания круговой диаграммы
Принимает датафрейм, название периода для подписи по оси X, и название проекта, которое будет использовано в заголовке и в имени сохраняемого png файла:
def pie_plot_settings(df, period_name, project_name):
labels = df['traffic_category'].tolist()
with plt.style.context('fivethirtyeight'):
df['visits_quantity'].plot(kind='pie',
labels=labels,
figsize=(25, 15),
fontsize = 20,
autopct='%1.1f%%',
cmap=plt.get_cmap('coolwarm'))
plt.ylabel('')
plt.xlabel(period_name, fontsize = 25)
plt.title(f'Распределение трафика из поисковых систем {project_name}', fontsize = 35)
plt.tight_layout()
plt.savefig(f'{project_name}-traffic-spread.png')
plt.show()
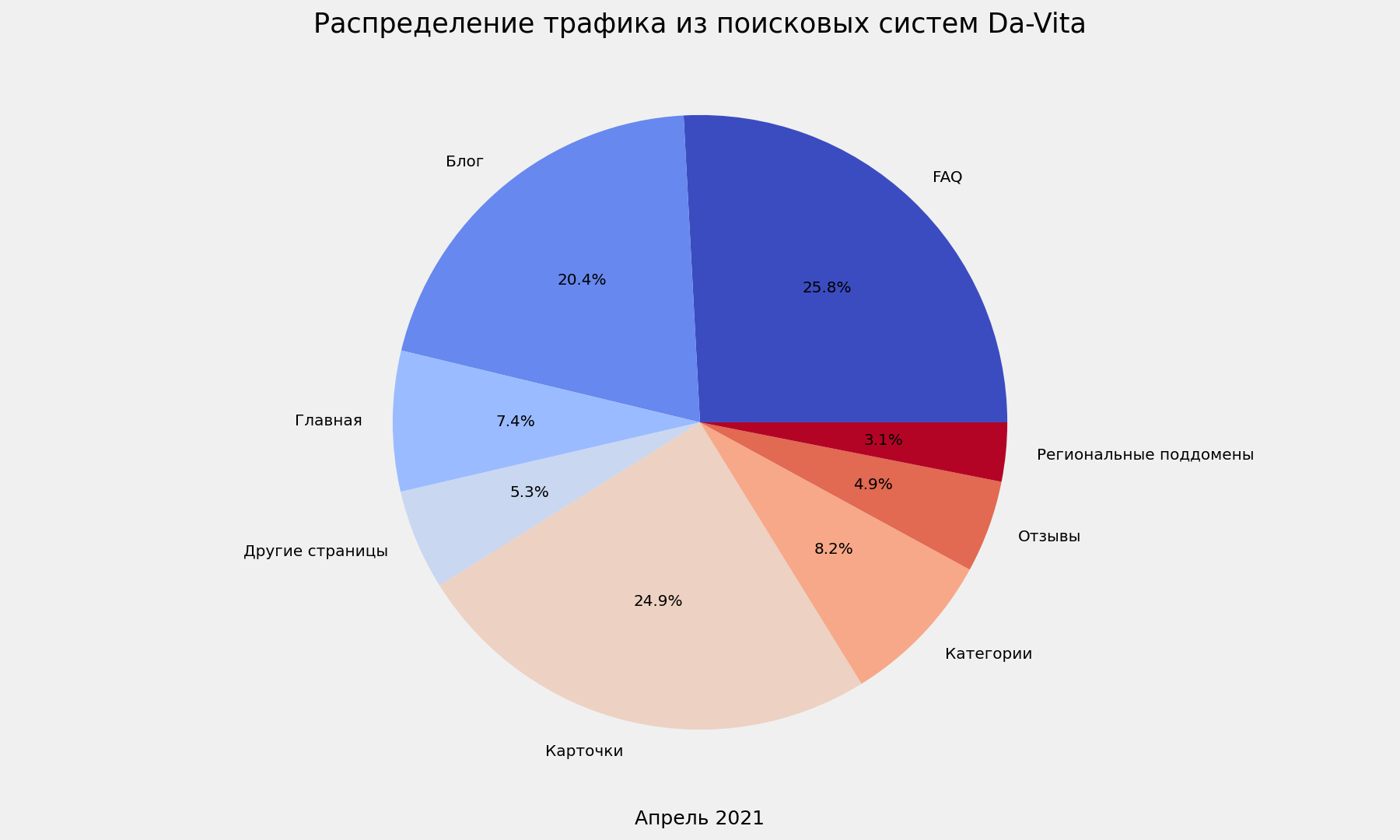
Пример 1: распределение трафика da-vita.ru
DAVITA_COUNTER_ID = 19249012
Начальная и конечная дата:
date_from = '2021-04-01'
date_to = '2021-04-30'
Получение данных
data = get_search_engine_start_urls_data_from_metrika_api(DAVITA_COUNTER_ID, date_from, date_to)

Преобразование полученных данных в датафрейм
df = extract_urls_and_visits_quantity(data)
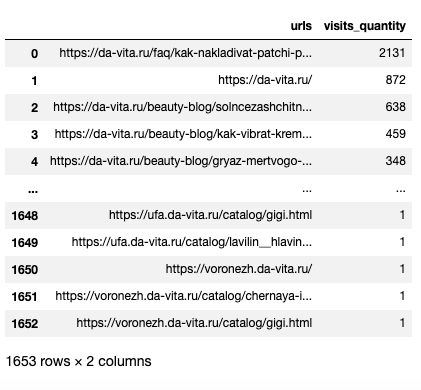
Функция шаблон для определения типов страниц для da-vita.ru
Самый удобный и точный способ определения типов страниц - по URL. В этом случае каждый тип имеет свою вложенность или уникальные слова-маркеры в URL.
Пример определения типов страниц для da-vita.ru:
Главная страница - main,
Карточки - card - вложенность в catalog, далее 2 уровня вложенности, заканчивается на html,
Статьи - blog - вложенность в beauty-blog, заканчивается на html,
FAQ - faq - вложенность в faq, заканчивается на html,
Отзывы - review - вложенность в otzyvy-o-kosmetike, заканчивается на html,
Поддомены - subdomain - любое количество английских букв перед da-vita.ru, любое количество символов после,
Категории - cat_pages, также как и карточки вложены в catalog и имеют 1 уровень вложенности после него, заканчиваются на html, если просто задать шаблон https://da-vita.ru/catalog/.*.html он будет пересекаться с карточками, поэтому в этом случае категории определяются через исключение всех карточек df[(cat) & ~(card)] - срез по "cat и НЕ card".
Функция принимает датафрейм с полученными из Метрики страницами входа и данными о количестве визитов на них за период.
В переменные записываются шаблоны страниц.
К датафрему применяется каждый шаблон по очереди, в новое поле traffic_category записывается название типа страниц:
def davita(df):
main = 'https://da-vita.ru/'
card = df['urls'].str.contains(pat='https://da-vita.ru/catalog/.*/.*.html',regex=True)
blog = df['urls'].str.contains(pat='https://da-vita.ru/beauty-blog/.*.html',regex=True)
faq = df['urls'].str.contains(pat='https://da-vita.ru/faq/.*.html',regex=True)
review = df['urls'].str.contains(pat='https://da-vita.ru/otzyvy-o-kosmetike/.*.html',regex=True)
subdomain = df['urls'].str.contains(pat='https://.*[a-z].da-vita.ru/.*',regex=True)
cat = df['urls'].str.contains(pat='https://da-vita.ru/catalog/.*.html',regex=True)
cat_pages = df[(cat) & ~(card)]
df['traffic_category'] = ''
df.loc[df['urls'] == main, 'traffic_category'] = 'Главная'
df.loc[df['urls'].isin(cat_pages['urls']), 'traffic_category'] = 'Категории'
df.loc[df['urls'].isin(df[card]['urls']), 'traffic_category'] = 'Карточки'
df.loc[df['urls'].isin(df[subdomain]['urls']), 'traffic_category'] = 'Региональные поддомены'
df.loc[df['urls'].isin(df[blog]['urls']), 'traffic_category'] = 'Блог'
df.loc[df['urls'].isin(df[faq]['urls']), 'traffic_category'] = 'FAQ'
df.loc[df['urls'].isin(df[review]['urls']), 'traffic_category'] = 'Отзывы'
df['traffic_category'] = df['traffic_category'].replace('', 'Другие страницы')
return df
Пример определения типов страниц
davita_traffic_spread = davita(df)
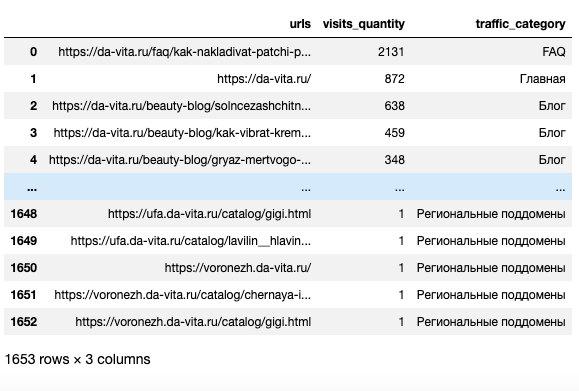
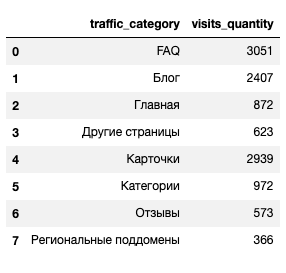
Создание сводной таблицы
davita_traffic_spread_pivot = davita_traffic_spread.pivot_table(index='traffic_category',
values='visits_quantity',
aggfunc='sum').reset_index()
Визуализация на диаграмме
pie_plot_settings(davita_traffic_spread_pivot,'Апрель 2021', 'Da-Vita')
Пример 2: распределение трафика kolesa-v-pitere.ru
Пример со вторым проектом нужен для демонстрации другого способа определения типов страниц.
KOLESA_COUNTER_ID = 47281992
Начальная и конечная дата:
date_from = '2023-04-01'
date_to = '2023-04-30'
Получение данных
kolesa_data = get_search_engine_start_urls_data_from_metrika_api(KOLESA_COUNTER_ID, date_from, date_to)
Преобразование данных в датафрейм
kolesa_df = extract_urls_and_visits_quantity(kolesa_data)
Функция шаблон для определения типов страниц для kolesa-v-pitere.ru
Для da-vita.ru шаблоны страниц определялись по URL. В случае с сайтом kolesa-v-pitere.ru с помощью регулярных выражений не получится определить является ли страница категорией или карточкой. Это можно было бы совершить, например если бы категория заканчивалась слэшем, а карточка была бы без слеша или заканчивалась на .html.
Но на kolesa-v-pitere.ru все страницы не имеют никаких символов в конце. Можно было бы попытаться определить тип страницы по уровню вложенности, например категория всегда второй уровень https://www.kolesa-v-pitere.ru/legkovye-shiny, а карточка третий https://www.kolesa-v-pitere.ru/legkovye-shiny/zimnie_shiny_Bridgestone_Blizzak_VRX_185_60_R15_84S__11. Но на сайте на третьем и более уровне может быть другая категория https://www.kolesa-v-pitere.ru/legkovye-shiny/legkovye-shiny-po-proizvoditelyu/ и https://www.kolesa-v-pitere.ru/legkovye-shiny/legkovye-shiny-po-proizvoditelyu/bridgestone-1.
Также на этом сайте создается множество страниц под уточненные запросы, поэтому такие страницы нужно определить в отдельный тип, чтобы понять сколько трафика они генерируют, но такие страниц тоже ничем не отличаются от обычных категорий.
В этом случае я использую списки алиасов карточек, категорий и созданных страниц, которые получаю из базы данных:
kvp_products_aliases.csv - алиасы карточек,
kvp_categories_aliases.csv - алиасы категорий,
kvp_filters_aliases.csv - алиасы созданных уточненных категорий.
Эти файлы находятся в папке с кодом.
Пример определения типов страниц для kolesa-v-pitere.ru:
Функция принимает датафрейм с данными по страницам входа из Метрики. Загружаются подготовленные файлы с алиасами.
Шаблон главной страницы - main,
шаблон поддоменов - subdomain,
В принятом датафрейме с данными Метрики URL разделяются по слешам, получается список из элементов разделенного URL, записывается в поле splitted_url. Из списка берется последний элемент, который должен являться алиасом, записывается в поле only_alias.
Далее каждый алиас сравнивается с подготовленным шаблоном main и subdomain, а также с алиасами из подготовленных файлов.
def kvp(df):
kvp_categories_aliases = pd.read_csv('kvp_categories_aliases.csv')
kvp_products_aliases = pd.read_csv('kvp_products_aliases.csv')
kvp_filters_aliases = pd.read_csv('kvp_filters_aliases.csv')
main = 'https://kolesa-v-pitere.ru/'
subdomain = df['urls'].str.contains(pat='https://.*[a-z].kolesa-v-pitere.ru/.*',regex=True)
df['traffic_category'] = ''
df['splitted_url'] = df['urls'].apply(lambda x: x.split('/'))
df['only_alias'] = df['splitted_url'].apply(lambda x: x[len(x)-1])
df.loc[df['urls'] == main, 'traffic_category'] = 'Главная'
df.loc[df['only_alias'].isin(kvp_categories_aliases['alias']), 'traffic_category'] = 'Категории'
df.loc[df['only_alias'].isin(kvp_products_aliases['alias']), 'traffic_category'] = 'Карточки'
df.loc[df['only_alias'].isin(kvp_filters_aliases['alias']), 'traffic_category'] = 'Фильтры'
df.loc[df['urls'].isin(df[subdomain]['urls']), 'traffic_category'] = 'Региональные поддомены'
df['traffic_category'] = df['traffic_category'].replace('', 'Другое')
return df
Пример определения типов страниц
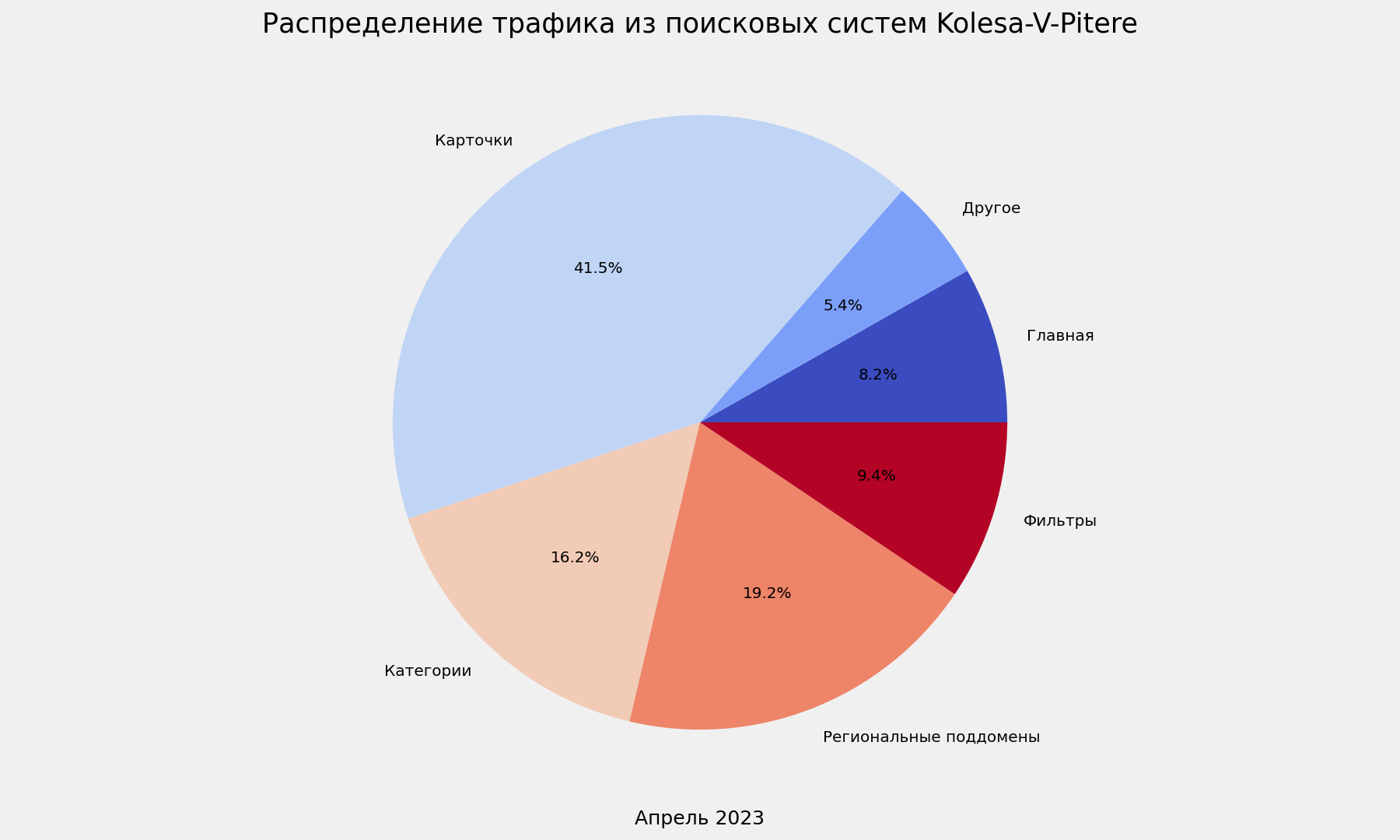
kvp_traffic_spread = kvp(kolesa_df)
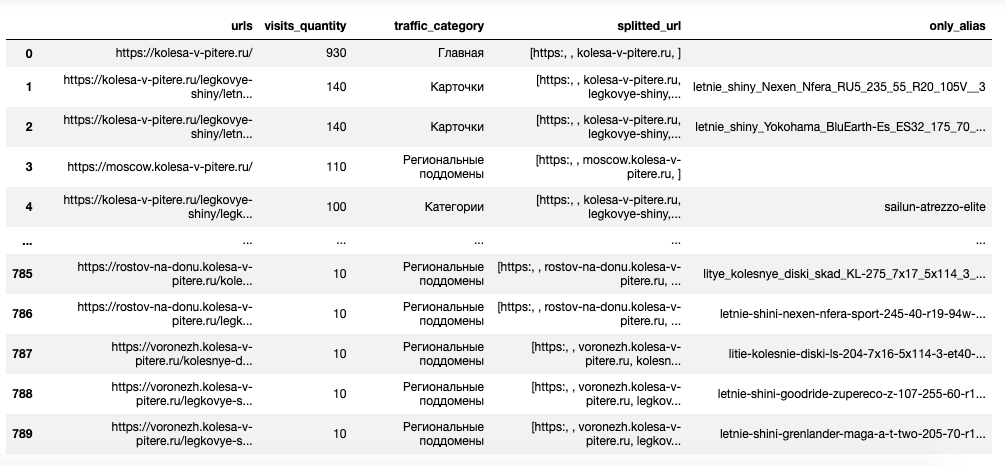
Создание сводной таблицы
kvp_traffic_spread_pivot = kvp_traffic_spread.pivot_table(index='traffic_category',
values='visits_quantity',
aggfunc='sum').reset_index()
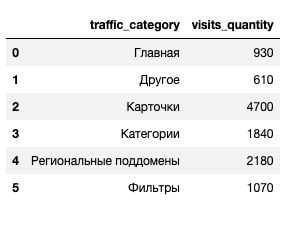
Визуализация
pie_plot_settings(kvp_traffic_spread_pivot, 'Апрель 2023', 'Kolesa-V-Pitere')
Распределение по месяцам
В этом разделе также будут получены данные и определены типы страниц, но не за конкретный период, а за каждый месяц в рамках какого-то периода, например за несколько лет. Данные будут визуализированы на столбчатой диаграмме с накоплением.
Функция для получения списка первых чисел месяца в рамках диапазона
Принимает начальную и конечную дату:
def create_list_of_fist_dates_of_months(date_from, date_to):
list_of_fist_dates_of_months = []
for month in pd.period_range(start=date_from,end=date_to, freq='M'):
list_of_fist_dates_of_months.append(str(month)+'-01')
return list_of_fist_dates_of_months
Пример списка:
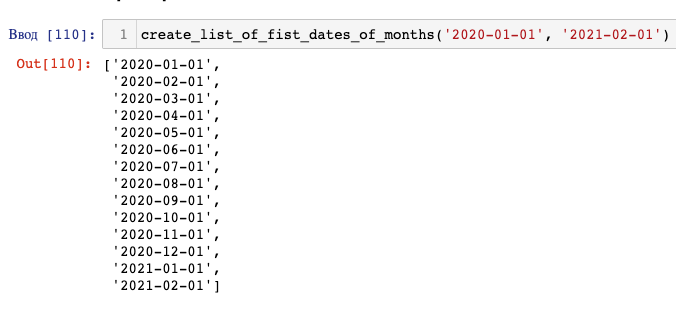
Функция для получения последнего числа месяца
Функция принимает первый день месяца и возвращает последний день месяца:
def get_last_day_of_month(first_day_of_month):
timestamp_date = pd.Timestamp(first_day_of_month)
return (timestamp_date + MonthEnd(0)).strftime('%Y-%m-%d')
Функция для получения данных за каждый месяц
Принимает номер счетчика, начальную и конечные даты.
Берет каждое первое число каждого месяца из диапазона,
получает последнее число месяца,
получается данные по страницам входа за месяц,
преобразует данные из Метрики в датафрейм,
добавляет в датафрейм поле с названием месяца,
которое получается из первого числа месяца,
превращает датафрейм в список словарей,
добавляет в общий список,
возвращает датафрейм с данными за все месяцы за указанный период:
def get_search_engine_start_urls_by_months(counter_id, date_from, date_to):
list_of_dicts = []
for first_day_of_month in create_list_of_fist_dates_of_months(date_from, date_to):
last_day_of_month = get_last_day_of_month(first_day_of_month)
data = get_search_engine_start_urls_data_from_metrika_api(counter_id,
first_day_of_month,
last_day_of_month)
df = extract_urls_and_visits_quantity(data)
df['month_name'] = pd.Timestamp(first_day_of_month).strftime('%B %Y')
list_of_dicts += df.to_dict('records')
return pd.DataFrame.from_dict(list_of_dicts)
Функция для создания столбчатой диаграммы с накоплением
Принимает датафрейм, название периода для вывода на ось Х, название проекта для вывода в заголовок:
def bar_plot_settings(df, period_name, project_name):
with plt.style.context('fivethirtyeight'):
df.set_index('traffic_category').reindex(df.set_index('traffic_category').sum().index, axis=1)\
.T.plot(kind='bar', stacked=True, figsize=(25,15), cmap=plt.get_cmap('coolwarm'))
plt.xlabel(period_name, fontsize = 25)
plt.ylabel('Количество визитов', fontsize = 25)
plt.title(f'Распределение трафика из поисковых систем {project_name}',fontsize = 35)
plt.legend(loc=0, prop={'size': 20})
plt.xticks(rotation=90, fontsize=18)
plt.tight_layout()
plt.savefig(f'{project_name}-traffic-spread-period.png')
plt.show()
Пример 1: распределение трафика da-vita.ru
DAVITA_COUNTER_ID = 19249012
Начальная и конечная дата:
date_from = '2017-01-01'
date_to = '2023-04-30'
Получение данных
davita_traffic_data_df = get_search_engine_start_urls_by_months(DAVITA_COUNTER_ID, date_from, date_to)
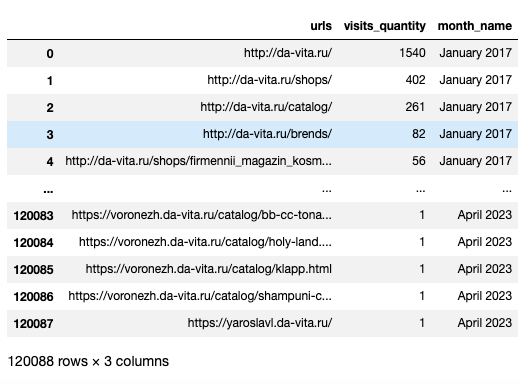
Определение типов страниц
Ранее был подготовлен шаблон для определения типов страниц:
davita_traffic_spread_period = davita(davita_traffic_data_df)
Создание сводной таблицы
davita_traffic_spread_period_pivot = (davita_traffic_spread_period.groupby(['traffic_category','month_name'],
sort=False)['visits_quantity']
.sum().unstack()).reset_index()
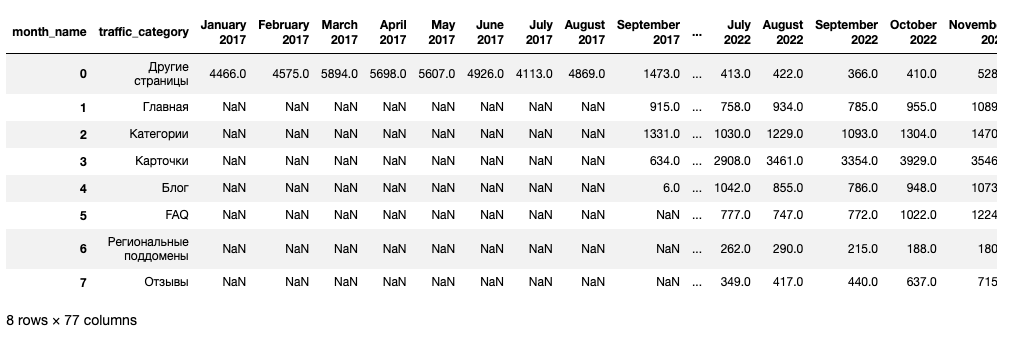
Визуализация
bar_plot_settings(davita_traffic_spread_period_pivot, 'Данные за 2017-2023', 'Da_Vita')
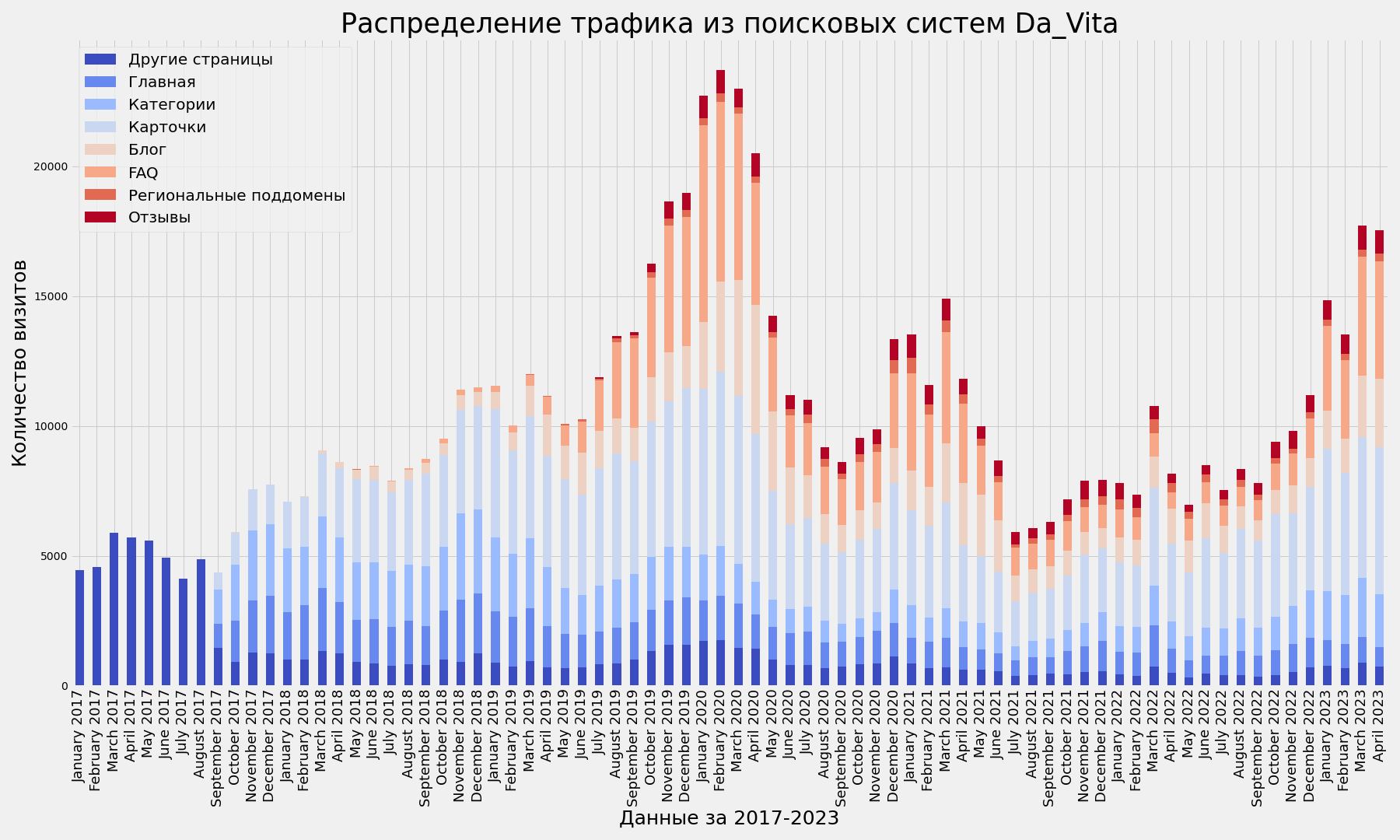
Пример 2: распределение трафика kolesa-v-pitere.ru
Пример со вторым проектом нужен для демонстрации другого способа определения типов страниц.
KOLESA_COUNTER_ID = 47281992
Начальная и конечная дата:
date_from = '2020-04-01'
date_to = '2023-04-30'
Получение данных
kolesa_traffic_data_df = get_search_engine_start_urls_by_months(KOLESA_COUNTER_ID, date_from, date_to)
Определение типов страниц
Ранее был подготовлен шаблон для определение типов страниц:
kolesa_traffic_spread_period = kvp(kolesa_traffic_data_df)
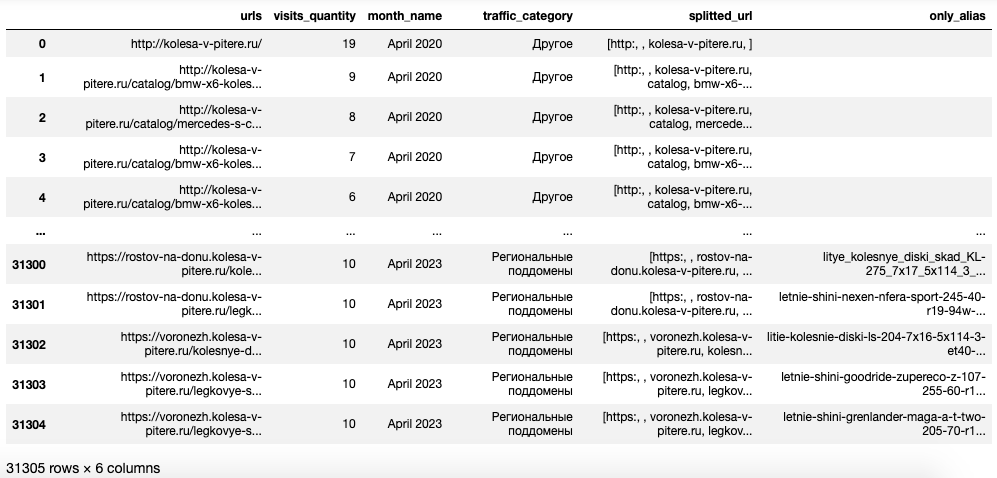
Создание сводной таблицы
kolesa_traffic_spread_period_pivot = (kolesa_traffic_spread_period.groupby(['traffic_category','month_name'],
sort=False)['visits_quantity']
.sum().unstack()).reset_index()
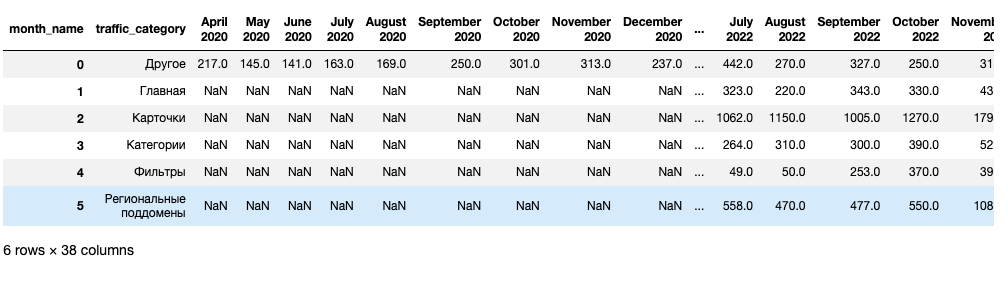
Визуализация
bar_plot_settings(kolesa_traffic_spread_period_pivot, 'Данные за 2020-2023', 'Kolesa-V-Pitere')
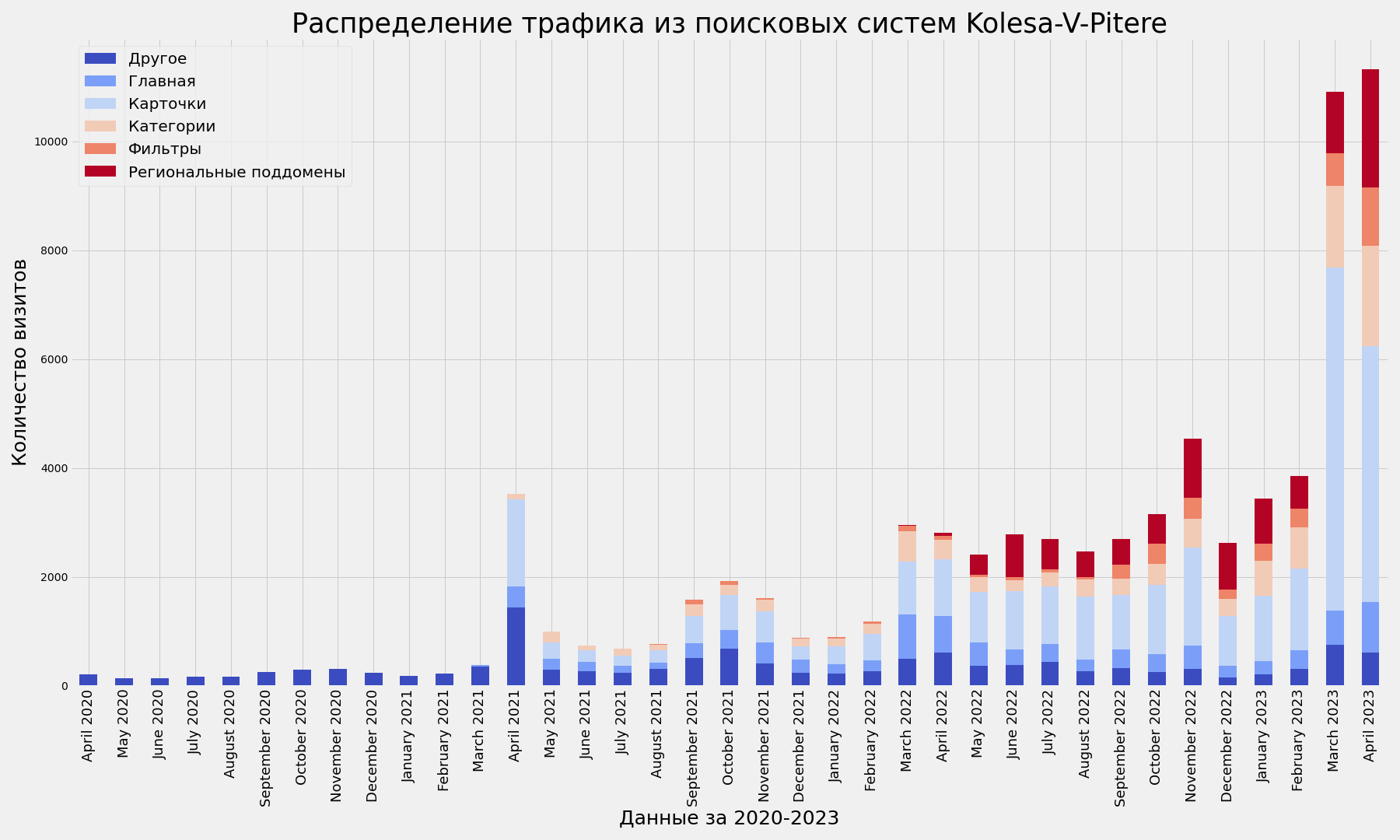
Часть 3: Получение визитов по страницам входа, анализ динамики трафика по каждому URL
В этой части будут те же функции, которые использовались для получения данных по страницам входа и анализа распределения трафика.
Пример 1: динамика трафика по URL da-vita.ru
DAVITA_COUNTER_ID = 19249012
Начальная и конечная дата:
date_from = '2021-01-01'
date_to = '2023-04-30'
Получение данных
davita_traffic_data_df = get_search_engine_start_urls_by_months(DAVITA_COUNTER_ID, date_from, date_to)
Определение типов страниц
Ранее был подготовлен шаблон для определение типов страниц:
davita_traffic_spread_period = davita(davita_traffic_data_df)
Создание сводной таблицы
Для такого анализа датафрейм слишком большой, нужно делать срез по какому-нибудь типу страниц.
Для примера сделаю срез по блогу:
davita_blog_traffic = davita_traffic_spread_period[davita_traffic_spread_period['traffic_category'] == 'Блог']
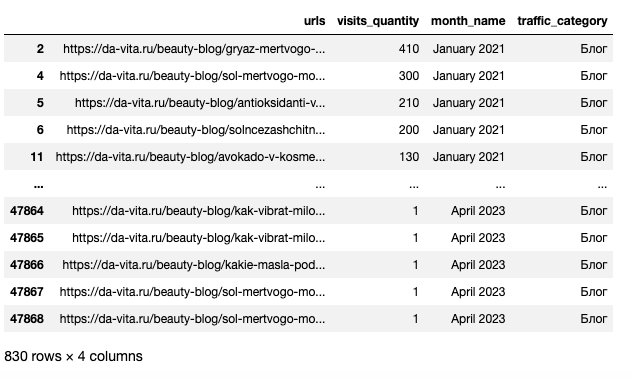
Создание сводной таблицы
davita_blog_traffic_pivot = (davita_blog_traffic.groupby(['urls','month_name'],
sort=False)['visits_quantity']
.sum().unstack()).reset_index()
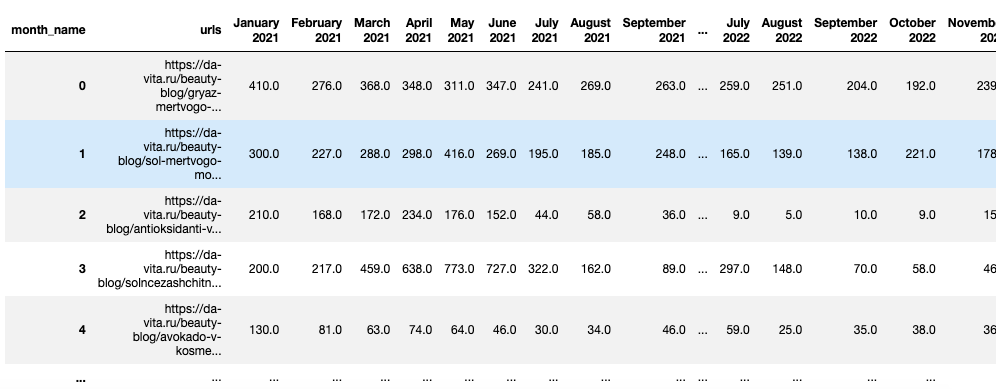
Все числовые данные стали float, для красоты всем колонкам начиная с January 2021 задам тип int:
davita_blog_traffic_pivot.fillna(0, inplace=True)
(davita_blog_traffic_pivot
[davita_blog_traffic_pivot.loc[:, 'January 2021':].columns]) = (davita_blog_traffic_pivot
[davita_blog_traffic_pivot.loc[:, 'January 2021':]
.columns].astype(int))
Визуализация
davita_blog_heatmap = davita_blog_traffic_pivot.style.background_gradient(axis=None)
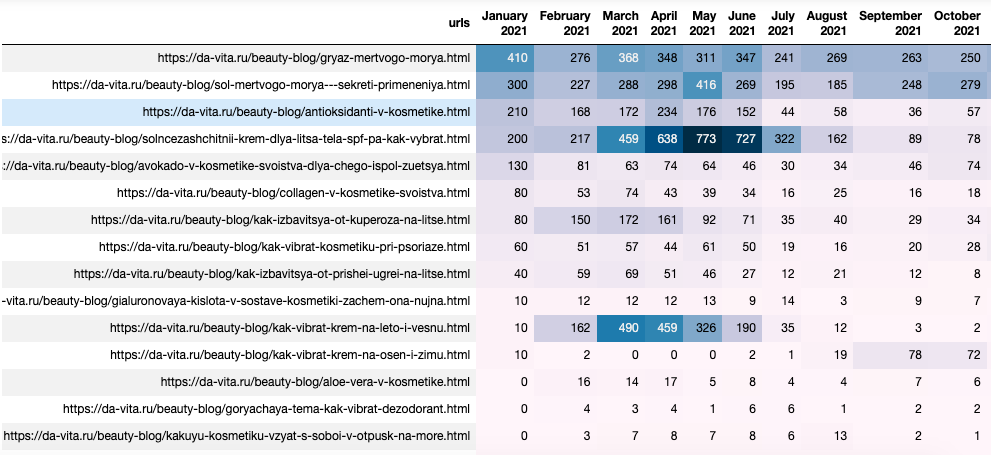
Экспорт для анализа в Excel
writer_kernel = pd.ExcelWriter('Da-Vita Blog URL Heatmap.xlsx', engine='xlsxwriter')
davita_blog_heatmap.to_excel(writer_kernel, index=False)
writer_kernel.save()Пример 2: динамика трафика по URL kolesa-v-pitere.ru
KOLESA_COUNTER_ID = 47281992
Начальная и конечная дата:
date_from = '2021-04-01'
date_to = '2023-04-30'
Получение данных
kolesa_traffic_data_df = get_search_engine_start_urls_by_months(KOLESA_COUNTER_ID, date_from, date_to)
Определение типов страниц
Ранее был подготовлен шаблон для определение типов страниц:
kolesa_traffic_spread_period = kvp(kolesa_traffic_data_df)
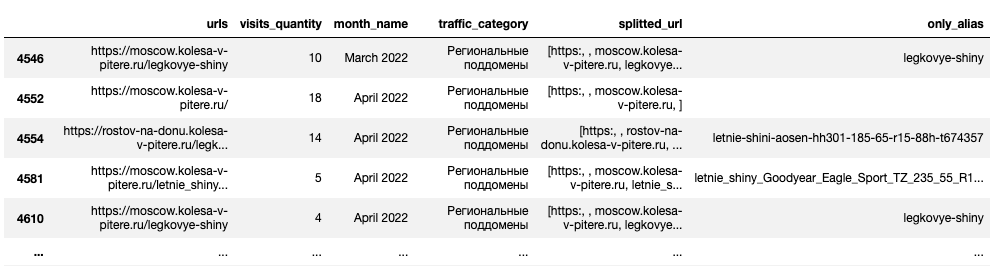
Создание сводной таблицы
Для примера сделаю срез по региональным поддоменам:
kolesa_subdomains_traffic = (kolesa_traffic_spread_period[kolesa_traffic_spread_period['traffic_category']
== 'Региональные поддомены'])
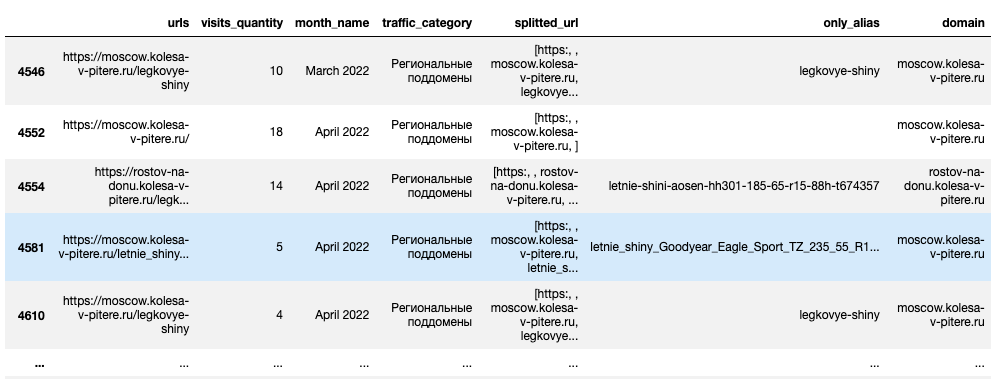
Из оставшихся URL нужно оставить домен:
kolesa_subdomains_traffic['domain'] = kolesa_subdomains_traffic['urls'].apply(lambda x: x.split('/'))kolesa_subdomains_traffic['domain'] = kolesa_subdomains_traffic['domain'].apply(lambda x: x[2])
kolesa_subdomains_traffic_pivot = (kolesa_subdomains_traffic.groupby(['domain','month_name'],
sort=False)['visits_quantity']
.sum().unstack()).reset_index()
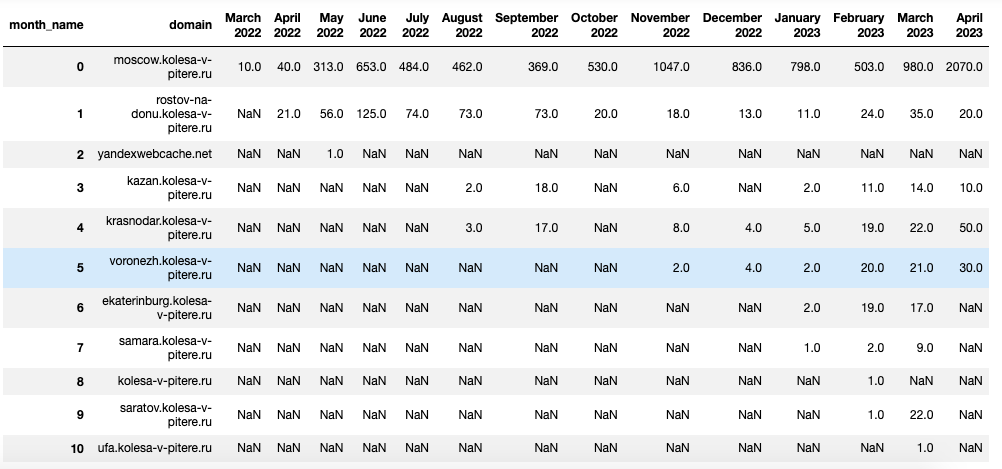
Все числовые данные стали float, для красоты всем колонкам начиная с March 2022 задам тип int:
kolesa_subdomains_traffic_pivot.fillna(0, inplace=True)
(kolesa_subdomains_traffic_pivot
[kolesa_subdomains_traffic_pivot.loc[:, 'March 2022':].columns]) = (kolesa_subdomains_traffic_pivot
[kolesa_subdomains_traffic_pivot.loc[:, 'March 2022':]
.columns].astype(int))
Визуализация
kolesa_blog_heatmap = kolesa_subdomains_traffic_pivot.style.background_gradient(axis=None)
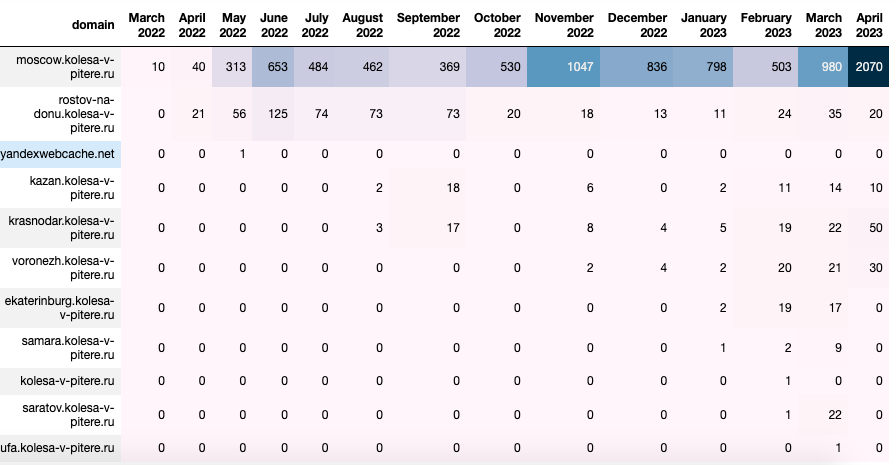
Экспорт для анализа в Excel
writer_kernel = pd.ExcelWriter('Kolesa-V-Pitere Subdomains URL Heatmap.xlsx', engine='xlsxwriter')
kolesa_blog_heatmap.to_excel(writer_kernel, index=False)
writer_kernel.save()


