Автоматизация - Получение позиций с использованием Topvisor API на Python
Содержание:
- Как использовать код из статьи
- Подготовка
- Получение информации о проектах в Топвизоре:
- Библиотеки
- Настройки
- Функции
- Запуск
- Экспорт
- Получение позиций проекта:
- Библиотеки
- Настройки
- Функции
- Запуск
- Раскрашивание позиций
- Экспорт
- Объединение полученных данных с рабочей таблицей:
- Функции для получения релевантной страницы
- Запуск
- Слияние таблиц
- Окрашивание
- Экспорт
Как использовать код из статьи
Я размещу код на Гитхабе в формате Jupyter Notebook – думаю, что так нагляднее.
Установите питон и сборку библиотек Anaconda.
Скачайте папку с Гитхаба. В ней будет:
-
файл topvisor_api.ipynb с кодом и комментариями,
-
таблица settings.xlsx, в которой содержится список проектов с ID, таблица используется для получения информации из Топвизора по всем проектам, для которых сервис собирает позиции,
-
таблица info_about_projects_from_topvisor.xlsx - результат получения общей информации по каждому проекту,
-
таблица Megaposm_2022-11-27.xlsx - результат выгрузки позиций для одного проекта,
-
Megaposm_semantic_kernel.xlsx - рабочая таблица или семантическое ядро, в которую нужно добавить позиции,
-
Megaposm_semantic_kernel_ready.xlsx - результат слияния рабочей таблицы с выгруженными данными из Топвизора.
Подготовка
Для работы необходимо получить API ключ. Инструкция.

Также необходимо знать ID вашего аккаунта:
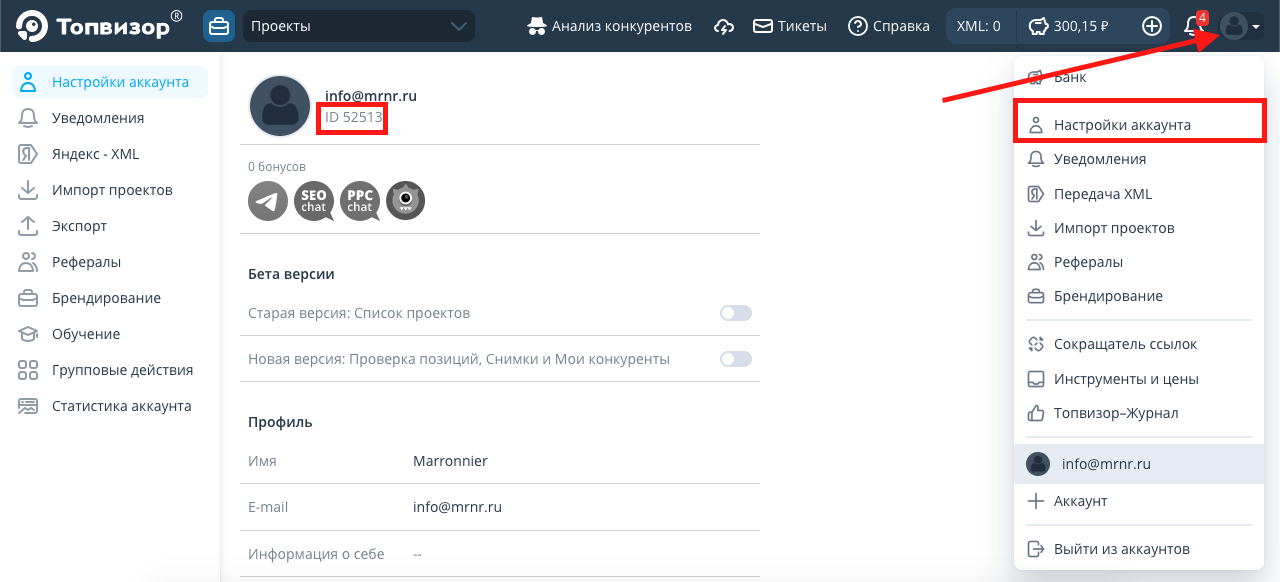
Получение информации о проектах в Топвизоре
Библиотеки
import requests
import json
import pandas as pd
Настройки
API ключ
key = 'dc56f44224b07e0ggm667899f9649f5a5'
User ID проекта
user_id = '67190'
Ресурс для получения информации
GET_PROJECT_SETTINGS = 'https://api.topvisor.com/v2/json/get/projects_2/projects'
Функции
Загрузка таблицы
В таблице settings.xlsx список проектов с id в Топвизоре:
def get_settings():
return pd.read_excel('settings.xlsx').to_dict('records')
Авторизация
def get_auth_headers(user_id, key):
return {'User-Id': user_id, 'Authorization': key}
Параметры
def get_params_info_about_projects():
return {
'show_searchers_and_regions': True
}
Получение информации
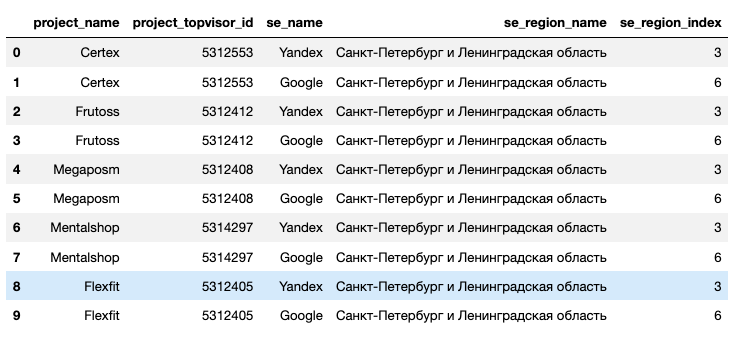
Для получения позиций по проекту нужно знать индекс поисковой системы, дополнительно функция получает название поисковой системы и название региона. Функция возвращает списко словарей:
def get_info_about_projects():
settings_table = get_settings()
r = requests.post(GET_PROJECT_SETTINGS, headers=get_auth_headers(user_id,key),json=get_params_info_about_projects())
data = json.loads(r.text)
list_of_dicts = []
for row in settings_table:
project_name, project_id = row['name'], row['project_id']
#print(project_name)
for element in data['result']:
if element['id'] == project_id:
for index_1 in range(len(element['searchers'])):
se_name = element['searchers'][index_1]['name']
#print(se_name)
for index_2 in range(len(element['searchers'][index_1]['regions'])):
se_region_name = element['searchers'][index_1]['regions'][index_2]['areaName']
#print(se_region_name)
se_region_index = element['searchers'][index_1]['regions'][index_2]['index']
#print(se_region_index)
d = dict()
d['project_name'] = project_name
d['project_topvisor_id'] = project_id
d['se_name'] = se_name
d['se_region_name'] = se_region_name
d['se_region_index'] = se_region_index
list_of_dicts.append(d)
return list_of_dicts
Запуск
info_about_projects = get_info_about_projects()
Запись в DataFrame
df = pd.DataFrame.from_dict(info_about_projects)
Экспорт
Сделайте экспорт, если необходимо:
export = pd.ExcelWriter('info_about_projects_from_topvisor.xlsx', engine='xlsxwriter')
df.to_excel(export, index=False)
export.save()Экспортируется таблица info_about_projects_from_topvisor.xlsx.
Получение позиций проекта
Библиотеки
import requests
import json
import traceback
import time
import datetime
from datetime import timedelta
import pandas as pd
Настройки
API ключ
key = 'dc56f44224b07e0ggm667899f9649f5a5'
User ID аккаунта
user_id = '67190'
Ресурс для получения позиций
GET_POSITIONS = 'https://api.topvisor.com/v2/json/get/positions_2/history'
Начальная дата
DATE_FROM = datetime.datetime(2022,10,1)
Конечная дата
DATE_TO = datetime.datetime(2022,10,25)
Название проекта
project_name = 'Megaposm'
Id проекта
project_id = 5312408
Индекс региона
Получение индекса региона описано в разделе Получение информации о проектах в Топвизоре. Индекс региона в примере соответствует Yandex Санкт-Петербург:
region_index = 3
Функции
Авторизация
def get_auth_headers(user_id, key):
return {'User-Id': user_id, 'Authorization': key}
Параметры
def get_params(project_id, first_date, last_date, region_index):
return {
'project_id': project_id,
'date1': first_date,
'date2': last_date,
'type_range': '0',
'regions_indexes': [region_index],
'positions_fields': ['position']
}
Список дат
Функция принимает начальную и конечнуб дату, возвращает список всех дат между начальной и конечной точкой. Эта функция необходисма для подсчета количества дней между заданными датами, потому что за 1 раз Топвизор дает позиции максимум за 31 день:
def get_list_of_dates(DATE_FROM, DATE_TO):
list_of_dates = []
delta = timedelta(days=1)
while DATE_FROM <= DATE_TO:
list_of_dates.append(DATE_FROM.strftime("%Y-%m-%d"))
DATE_FROM += delta
return list_of_dates
Также список дат можно получить, используя pandas:
list_of_dates = pd.period_range(start='2022-10-01',end='2022-11-25', freq='D')
Отчет об ошибках
def error_report():
print('Ошибка')
traceback.print_exc()
Получение позиций
Функция принимает список дат, определяет первую и последнюю в списке, получает позиции, возвращает DataFrame. Если за указанный период по фразе нет данных, пишет об этом, пишет отчет об ошибке:
def get_positions_from_topvisor(user_id, key, list_of_dates, project_id, region_index):
first_date = list_of_dates[0]
last_date = list_of_dates[-1]
r = requests.post(GET_POSITIONS,
headers=get_auth_headers(user_id, key),
json=get_params(project_id, first_date, last_date, region_index))
data = json.loads(r.text)
list_of_dicts = []
for index in range(len(data['result']['keywords'])):
keyword = data['result']['keywords'][index]['name']
dates_and_positions = data['result']['keywords'][index]['positionsData']
try:
for date, position in data['result']['keywords'][index]['positionsData'].items():
d = dict()
d['keyword'] = keyword
d['dates'] = date
d['position'] = position['position']
list_of_dicts.append(d)
except:
time.sleep(0.1)
print(f'Период: {first_date}-{last_date}')
print('Не получены данные по фразе', f"'{keyword}'")
error_report()
return pd.DataFrame.from_dict(list_of_dicts)
На выходе получается таблица:
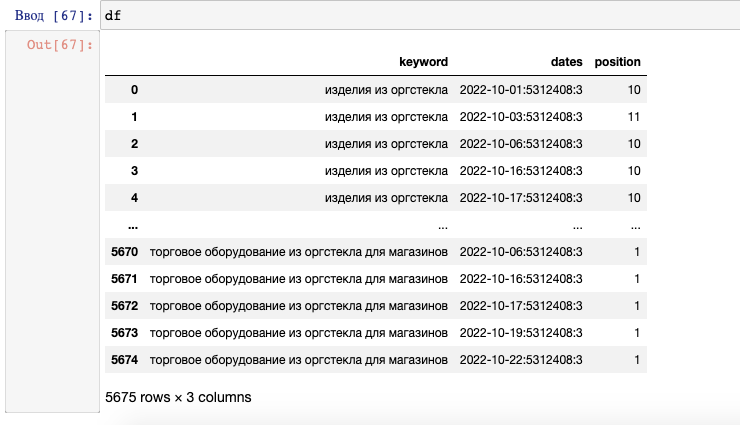
Получение позиций за период больше чем 31 день
def get_positions_for_more_than_31_days(user_id, key, list_of_dates, project_id, region_index):
step = 31
end = len(list_of_dates)
start = 0
df = pd.DataFrame()
for number in range(start, end, step):
limited_list_of_dates = list_of_dates[number:number+step]
df = df.append(get_positions_from_topvisor(user_id,
key,
limited_list_of_dates,
project_id,
region_index), ignore_index=True)
start += step
return df
Преобразование типов данных и превращение в сводную таблицу
Топвизор возвращает не только дату, но и id проекта и id региона в одной строке, функция оставляет только дату. Если по фразе нет позиции, топвизор возвращает --, функция заменяет это значение на 101. Значения всех позиций преобразуются в целые числа. Таблица преобразуется в сводную, где столбцами становятся даты. Если по ключевому слову за какую-либо дату нет позиции, получается Nan, который преобразуется в 0 параметром fill_value:
def edit_dates_positions_convert_to_pivot(df):
df['dates'] = df['dates'].apply(lambda x: x.split(':')[0])
df['position'] = df['position'].str.replace('--', '101')
df['position'] = df['position'].astype(int)
df_pivot = df.pivot_table(index=['keyword'], values='position',
columns='dates',
aggfunc='first',
fill_value=0).reset_index()
return df_pivot
Результатом будет преобразованная таблица, удобная для просмотра позиций:
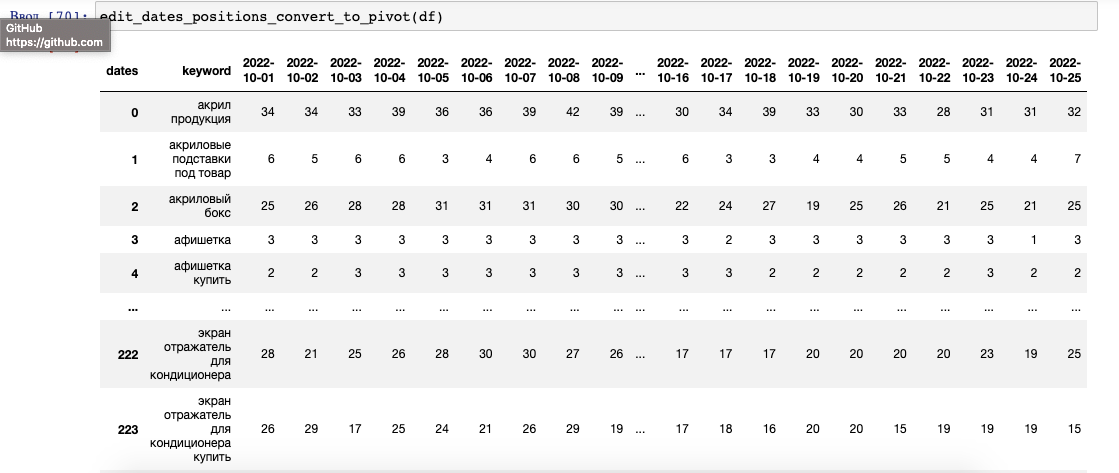
Главная функция
def main_get_positions_and_export():
list_of_dates = get_list_of_dates(DATE_FROM, DATE_TO)
if len(list_of_dates) <= 31:
df = get_positions_from_topvisor(user_id, key, list_of_dates, project_id, region_index)
df_pivot = edit_dates_positions_convert_to_pivot(df)
return df_pivot
else:
df = get_positions_for_more_than_31_days(user_id, key, list_of_dates, project_id, region_index)
df_pivot = edit_dates_positions_convert_to_pivot(df)
return df_pivot
Запуск
df = main_get_positions_and_export()
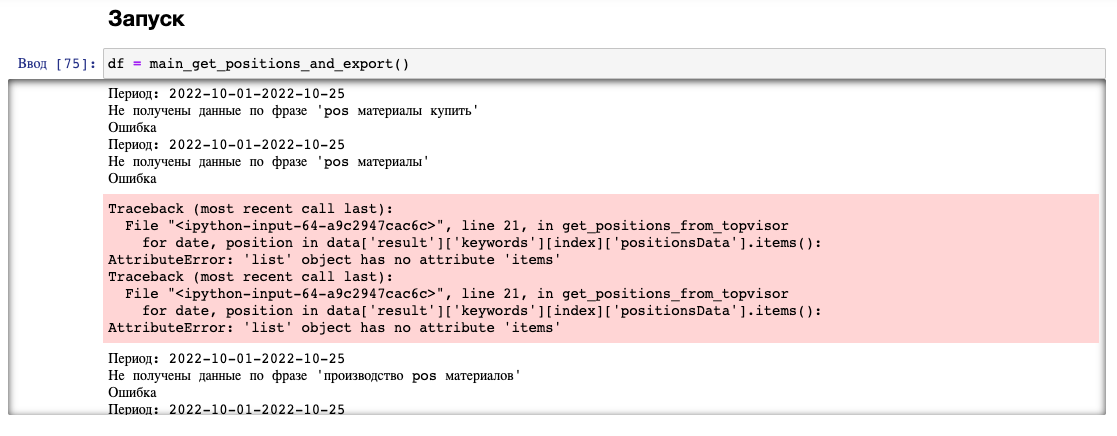
Результаты записываются в переменную df, выводится отчет по каким фразам не были получены данные и по какой причине.
Раскрашивание позиций
df = df.style.background_gradient(axis=0, vmin=1,vmax=101)
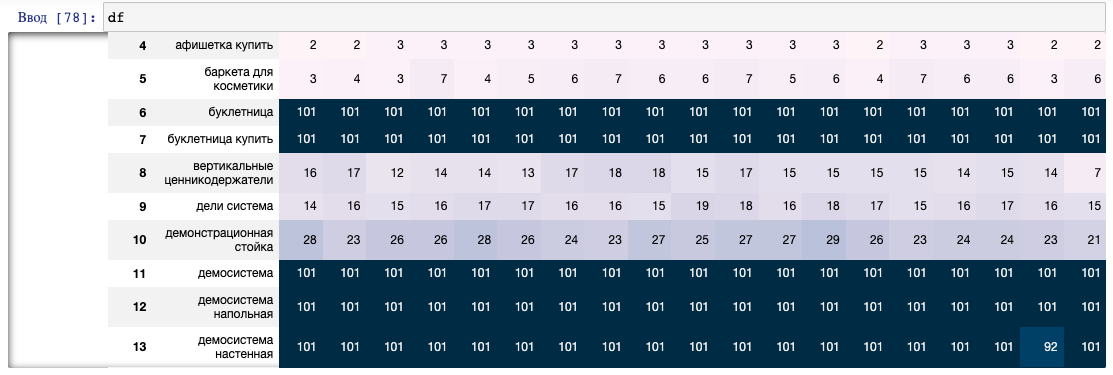
Экспорт
Можно сделать экспорт, чтобы рассмотреть результаты в Excel или перейти к следующему шагу:
datetime_now = datetime.datetime.now().strftime("%Y-%m-%d")export = pd.ExcelWriter(f'{project_name}_{datetime_now}.xlsx', engine='xlsxwriter')
df.to_excel(export, index=False)
export.save()Объединение полученных данных с рабочей таблицей
Данные выгружаются из Топвизора в том порядке, в котором они загружены при создании проекта и дальнейшим добавлением фраз. Ваша рабочая таблица (семантическое ядром) может иметь другой порядок. Нужно объединить основную таблицу с выгруженными данными.
У нас уже есть таблица с позициями, записанная в df:
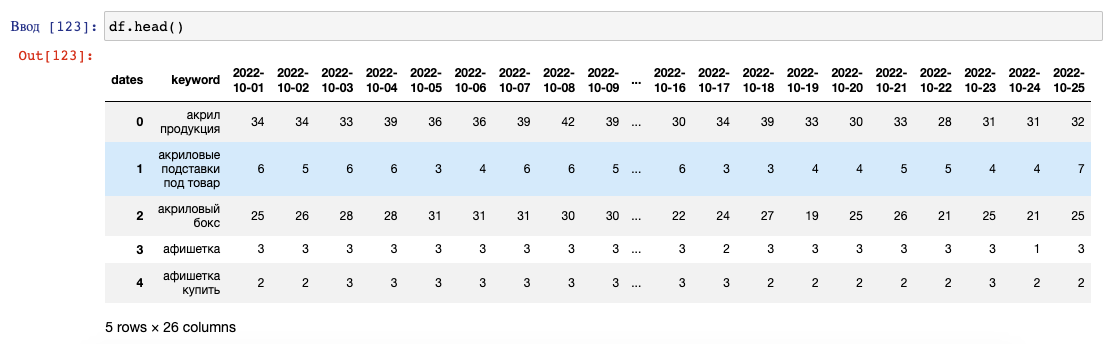
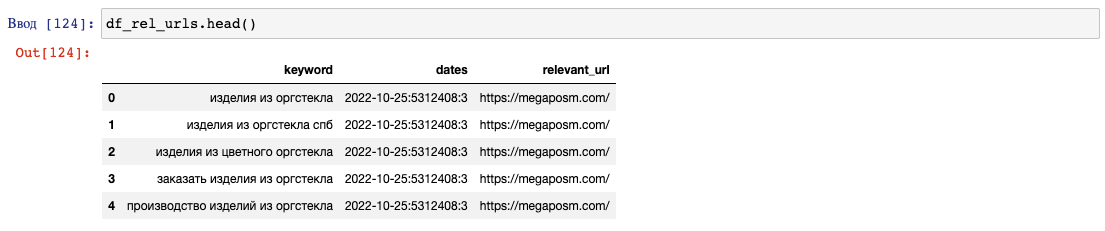
Еще нам нужно получить URL на поиске по каждой фразе за последнюю дату в интервале.
Функции для получения релевантной страницы
Для этого нужно указать в relevant_url в параметре positions_fields:
def get_params_for_rel_url(project_id, first_date, last_date, region_index):
return {
'project_id': project_id,
'date1': first_date,
'date2': last_date,
'type_range': '0',
'regions_indexes': [region_index],
'positions_fields': ['relevant_url']
}
Выгрузка будет за последнюю дату DATE_TO, которая указана выше:
first_date = DATE_TO.strftime('%Y-%m-%d')
last_date = DATE_TO.strftime('%Y-%m-%d')Получение релевантных страниц, функция возвращает DataFrame:
def get_rel_page_from_topvisor(user_id, key, first_date, last_date, project_id, region_index):
r = requests.post(GET_POSITIONS,
headers=get_auth_headers(user_id, key),
json=get_params_for_rel_url(project_id, first_date, last_date, region_index))
data = json.loads(r.text)
list_of_dicts = []
for index in range(len(data['result']['keywords'])):
keyword = data['result']['keywords'][index]['name']
dates_and_positions = data['result']['keywords'][index]['positionsData']
try:
for date, relevant_url in data['result']['keywords'][index]['positionsData'].items():
d = dict()
d['keyword'] = keyword
d['dates'] = date
d['relevant_url'] = relevant_url['relevant_url']
list_of_dicts.append(d)
except:
time.sleep(0.1)
print(f'Период: {first_date}')
print('Не получены данные по фразе', f"'{keyword}'")
error_report()
return pd.DataFrame.from_dict(list_of_dicts)
Запуск
df_rel_urls = get_rel_page_from_topvisor(user_id, key, first_date, last_date, project_id, region_index)
Слияние таблиц
Загрузка основной таблицы
Основная таблица, в которую будет добавлена релевантная страница и позиции за период:
megaposm = pd.read_excel('Megaposm_semantic_kernel.xlsx')
Изменение названий столбцов в датафрейме с позициями и релевантными URL Для слияния нужно чтобы поля, по которым будет производится слияние имели одинаковое название. В рабочей таблице megaposm поле с ключевыми фразами называется "Фраза", в датафреймах с позициями и релевантными URL - "keyword":
df.rename(columns={'keyword':'Фраза'}, inplace=True)
df_rel_urls.rename(columns={'keyword':'Фраза', 'relevant_url': 'URL в поиске'}, inplace=True)
df_rel_urls = df_rel_urls[['Фраза','URL в поиске']]
Слияние с релевантной страницей:
megaposm = megaposm.merge(df_rel_urls, on='Фраза', how='left')
Слияние с позициями:
megaposm = megaposm.merge(df, on='Фраза', how='left')
Результат слияний:
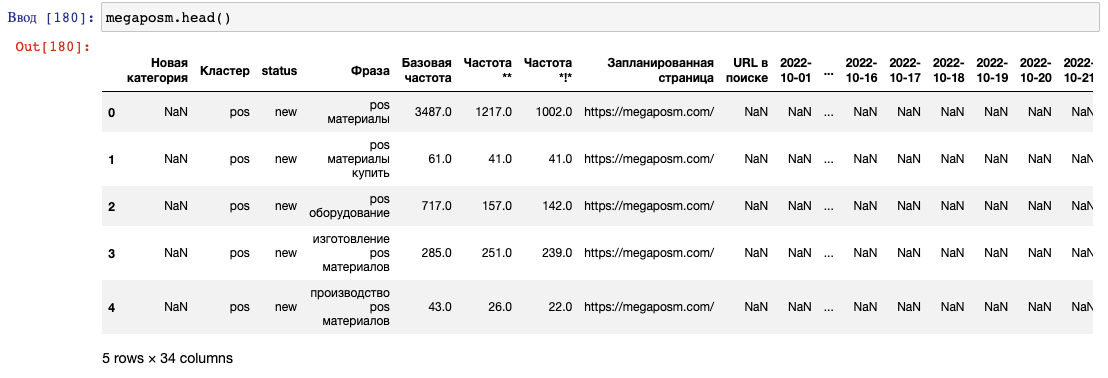
Таблица уже готова к экспорту.
Окрашивание
Дополнительно можно раскрасить динамику позиций.
Чтобы не раскрашивать все значения в таблице, а только позиции, нужно указать срез полей:
sliced = megaposm.loc[:, '2022-10-01':].columns
Срез начинается с первой даты с позициями и до конца таблицы.
Если в таблице присутствует Nan, он окрашивается в черный цвет:

Можно заменить Nan на 0:
megaposm = megaposm.fillna(0)
Окрашивание:
megaposm = megaposm.style.background_gradient(axis=0, vmin=1,vmax=101, subset=sliced)
Экспорт
export = pd.ExcelWriter('Megaposm_semantic_kernel_ready.xlsx', engine='xlsxwriter')
megaposm.to_excel(export)
export.save()
Экспортирована таблица Megaposm_semantic_kernel_ready.xlsx.



