Автоматизaция - Индексирование сайтов с помощью Index Now на Python
Содержание:
- Документация
- Зачем это нужно
- Эффективность инструмента
- Что делает эта программа
- Настройка Settings
- Процесс выполнения setup_projects:
- Загрузка данных из settings.xlsx
- Генерация ключей и запись в таблицу
- Создание папок
- Создание txt с ключами
- Подготовка пустой CSV базы
- Главная функция - генерация ключей, создание папок, txt и csv файлов
- Запуск
- Дополнение базы поддоменами из Яндекс Вебмастера
- Получение списка хостов по каждому проекту из Settings
- Извлечение поддоменов из хостов
- Добавление поддоменов в Settings
- Главная функция получение поддоменов из Яндекс Вебмастера и добавление в Settings
- Запуск
- Создание ключей для поддоменов
- Создание txt и добавление в папку по названию проекта
- Главная функция - создание ключей и добавление в таблицу, создание txt и добавление в папку
- Запуск
- Процесс выполнения IndexNow:
- Загрузка данных из settings.xlsx
- Парсинг Sitemap
- Открытие csv файла
- Список URL в csv конвертировать в set
- Список URL в csv конвертировать в list
- Определение новых URL (есть в парсинге Sitemap, нет в CSV)
- Определение URL без изменений (есть в CSV, есть в Sitemap)
- Определение удаленных URL (есть в CSV, нет в Sitemap)
- Функция, отправляющая не более 10 тыс. URL
- Функция, отпраляюшая более 10 тыс. URL
- Получение списка поддоменов
- Генерация адресов для поддоменов из основного csv файла
- Процесс отправки страниц в IndexNow
- Главная функция отправки в IndexNow для проектов с одной картой
- Главная функция отправки в IndexNow для проектов с мульти картой
- Запуск
IndexNow – программный интерфейс, с помощью которого можно сообщить поисковой системе о страницах, которые нужно проиндексировать.
Документация
На текущий момент протокол поддерживают две поисковые системы – Яндекс и Bing. Этот список наверное будет пополняться, посмотреть можно тут.
Зачем это нужно
Наряду с классическими средствами индексирования, это просто еще один дополнительный инструмент, что является несомненным плюсом – чем больше средств, чтобы запихать страницы сайта в поисковую базу, тем лучше. Еще отмечу, что в IndexNow нет квоты, как например в инструменте «Переобход страниц» в Яндекс Вебмастере, поэтому этот инструмент может облегчить жизнь, когда нужно добавить в поиск сайт с десятками-сотнями тысяч страниц, у которого могут быть региональные поддомены и/или языковые версии.
Эффективность инструмента
IndexNow довольно свежее явление, работая с ним пару месяцев, пока не могу утверждать о его 100% эффективности. Мне показалось, что результат есть, но эксперимент не был чистым, т.к. сайты, отправленные через IndexNow, в то же время регистрировались в Яндекс Вебмастере с указанием Sitemap.
Как использовать код из статьи
Я размещу код на Гитхабе в формате Jupyter Notebook – думаю, что так нагляднее.
Установите питон и сборку библиотек Anaconda.
Скачайте папку с Гитхаба. В ней будет:
-
код, два скрипта - setup_projects.ipynb и indexNow.ipynb;
-
settings.xlsx таблица, которая является примитивным интерфейсом для управления;
-
папки, в которых находится база URL в csv и приватный ключ в txt для проектов, которые представлены в примере.
Что делает эта программа
В settings.xslx нужно указать проект/проекты и все необходимые параметры.
Программа setup_projects:
Основные задачи:
-
получает список проектов из settings.xslx,
-
создает для каждого проекта приватный ключ и записывает его в settings.xslx,
-
создает папку для каждого проекта из settings.xslx,
-
создает txt-файл с сгенерированным ключом, добавляет файл в соответствующую папку,
-
создает пустую csv-таблицу с названием полей, добавляет таблицу в соответствующую папку.
Дополнительные задачи:
-
подключается к Яндекс Вебмастеру и получает список поддоменов, добавляет поддомены в settings.xslx,
-
создает для каждого поддомена приватный ключ и записывает его в settings.xslx,
-
создает txt-файл с сгенерированным ключом, добавляет файл в папку.
Программа indexNow:
-
получает список проектов с данными из settings.xslx,
-
парсит карты сайтов, добавляет полученные URL в CSV,
-
при каждом запуске нового парсинга и добавления полученных URL в CSV программа определяет и записывает статус URL,
-
если URL есть в Sitemap, но отсутствует в CSV, он добавляется в CSV и получает статус «NEW»,
-
eсли URL есть и в Sitemap и CSV, в CSV URL получает статус «UPDATED»,
-
если URL отсутствует в Sitemap, но есть в CSV, в CSV URL получает статус «DELETED»,
-
после обновления CSV базы происходит отправка всех URL в IndexNow.
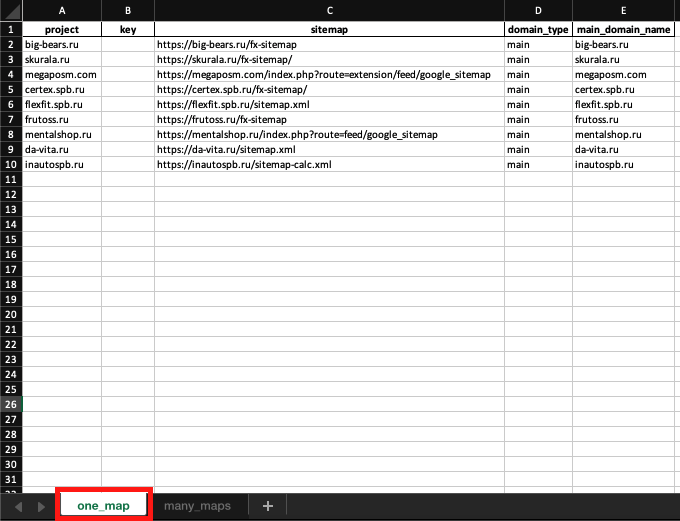
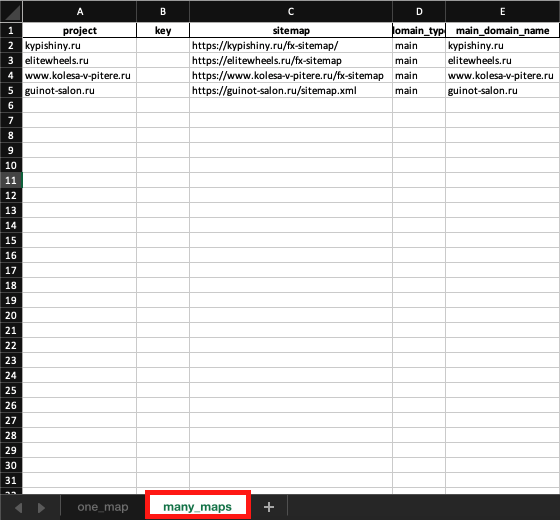
Настройка Settings.xlsx
Эта табличка представляет из себя базу данных, в которой хранятся параметры необходимые для работы программы:
-
Project - название проекта, которое будет использовано для создания папки и дальнейшего обращения к ней, формирования названия CSV-таблицы и названия txt-файла с приватным ключом. Заполните поле полным названием домена без указания протокола, например da-vita.ru или megaposm.com.
-
Key – приватный ключ. Подробности. Ключ будет сгенерирован в процессе работы setup_projects.
-
Sitemap – укажите полный адрес карты сайта.
-
Domain type – для всех перечисленных проектов укажите main, этот признак нужен для получения и отправки в IndexNow поддоменов.
-
Main domain name – скопируйте сюда домен, который вы указываете в Project, , этот признак нужен для получения и отправки в indexNow поддоменов.
В settings.xlsx два листа:
-
one_map – тут я указываю проекты с одной картой сайта,
-
many_maps – проекты с мульти картой (sitemap, которая содержит много других sitemap).
Процесс выполнения setup_projects
Необходимые библиотеки:
import requests
import json
import re
import secrets
import os
import pandas as pd
import numpy as np
from openpyxl import load_workbook
Запись в константы путей к settings.xlsx и будущим папкам:
PROJECT_SETTINGS_PATH = 'settings.xlsx'
FOLDERS_PATH = '{}'
Загрузка данных из settings.xlsx
one map:
def get_projects_with_one_map():
return pd.read_excel(PROJECT_SETTINGS_PATH)
many maps:
def get_projects_with_many_maps():
return pd.read_excel(PROJECT_SETTINGS_PATH, sheet_name = 'many_maps')
Экспорт новых данных на определенный лист. Функция в качестве аргумента получает DataFrame и название листа xlsx:
def export_data_to_specified_sheet(data, export_sheet_name):
with pd.ExcelWriter(PROJECT_SETTINGS_PATH, engine='openpyxl', mode='a', if_sheet_exists='replace') as writer:
data.to_excel(writer, export_sheet_name, index=False)
Генерация ключей и запись в таблицу
Функция в качестве аргумента получает DataFrame, преобразованный в словарь и название листа xlsx:
def create_private_key_and_export_settings_xlsx(project_settings, export_sheet_name):
for row in project_settings:
row['key'] = secrets.token_hex(64)
updated_project_settings = pd.DataFrame.from_dict(project_settings)
export_data_to_specified_sheet(updated_project_settings, export_sheet_name)
Создание папок
Функция в качестве аргумента получает DataFrame и по названиям в поле project создает папки:
def create_folders(project_settings):
for row in project_settings:
os.makedirs(FOLDERS_PATH.format(row['project']),exist_ok=True)
Создание txt с ключами
Функция в качестве аргумента получает название проекта для поиска нужной папки и название проекта для названия txt-файла, которое генерируется по шаблону project_name_private_key_indexnow.txt:
def create_private_key_txt(project_name, project_txt_name, key):
with open(os.path.join(FOLDERS_PATH.format(project_name), f'{project_txt_name}_private_key_indexnow.txt'), 'w') as f:
f.write(key)
Подготовка пустой CSV базы
Функция в качестве аргумента получает название проекта для поиска нужной папки и название проекта для названия csv-таблицы, которое генерируется по шаблону project_name _url_base_indexnow.csv. Таблица содержит пустые поля url и status:
def create_empty_csv_base(project_folder, project_csv_name):
data = {
'url':np.nan,
'status':np.nan,
}
base = pd.DataFrame(data, index=[0])
base.to_csv(f'{project_folder}/{project_csv_name}_url_base_indexnow.csv',index=False)
Главная функция - генерация ключей, создание папок, txt и csv файлов
Происходит вызов всех созданных ранее функций. Сначала для проектов с листа one map, затем с листа many maps.
Загрузка данных в DataFrame и конвертация в словарь.
Создание ключей и запись в таблицу create_private_key_and_export_settings_xlsx().
Создание папок create_folders().
Снова загрузка данных в DataFrame и конвертация в словарь.
Для каждого проекта создание txt-файла и добавление в папку create_private_key_txt().
Для каждого проекта создание csv-файла и добавление в папку create_empty_csv_base().
def set_up_projects_first_time_main():
#one_map
project_settings = get_projects_with_one_map().to_dict('records')
create_private_key_and_export_settings_xlsx(project_settings,'one_map')
create_folders(project_settings)
project_settings = get_projects_with_one_map().to_dict('records')
for row in project_settings:
project, key = row['project'], row['key']
create_private_key_txt(project, project, key)
create_empty_csv_base(project, project)
#many_maps
project_settings = get_projects_with_many_maps().to_dict('records')
create_private_key_and_export_settings_xlsx(project_settings,'many_maps')
create_folders(project_settings)
project_settings = get_projects_with_many_maps().to_dict('records')
for row in project_settings:
project, key = row['project'], row['key']
create_private_key_txt(project, project, key)
create_empty_csv_base(project, project)
Запуск
Красные ворнинги не являются проблемой.
Результат
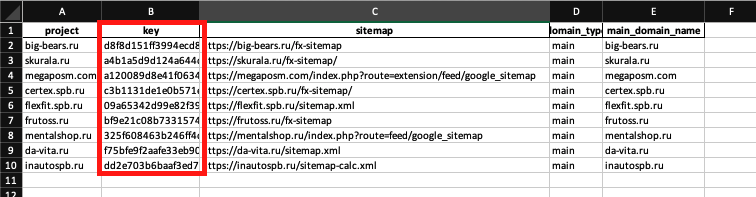
Для всех проектов созданы папки:

Внутри папок txt с ключом, и пустая таблица csv:
Добавление txt на сервер
Добавьте txt-файл на сервер в корневую папку вашего сайта. На сколько я понял, для txt-файла не получится создать отдельную папку, нужно, чтобы файлик лежал именно в корне. При использовании программы, когда txt лежат в отдельной директории, я получал ответ 422. Яндекс рекомендует хранить ключи в корневой папке:

Дополнение базы поддоменами из Яндекс Вебмастера
Константы
Токен Яндекса, ресурс для получения User ID, ресурс для получения списка хостов из Яндекс Вебмастера:
TOKEN = 'Ваш Токен'
USERID_URL = 'https://api.webmaster.yandex.net/v4/user'
GET_SITE_LIST = 'https://api.webmaster.yandex.net/v4/user/{}/hosts'
Как получить токен Яндекса - документация.
Авторизация
def get_auth_headers() -> dict:
return {'Authorization': f'OAuth {TOKEN}'}
Получение User ID
def get_user_id() -> str:
r = requests.get(USERID_URL, headers=get_auth_headers())
user_id = json.loads(r.text)['user_id']
return user_id
Получение списка хостов по каждому проекту из Settings
Пример написания хоста https:site.ru:443. Функция в качестве агрумента получает User ID и название проекта из settings. Получает список всех хостов, которые есть в вашем аккаунте Яндекс Вебмастера, по регулярному выражению находит поддомены по названию проекта:
def request_yandex_webmaster(user_id, project):
request = requests.get(GET_SITE_LIST.format(user_id), headers=get_auth_headers())
site_list = json.loads(request.text)
project_subdomains_hosts = []
for number in range(len(site_list['hosts'])):
regex = re.search(f'.*{project}.*', site_list['hosts'][number]['host_id'])
if regex:
project_subdomains_hosts.append(regex.group())
return project_subdomains_hosts
Извлечение поддоменов из хостов
Из хоста вида https:site.ru:443 получаю site.ru:
def extract_subdomains_from_hosts(project_subdomains_hosts):
project_subdomains_list = []
for domain in project_subdomains_hosts:
project_subdomains_list.append(domain.split(':')[1])
return project_subdomains_list
Добавление поддоменов в Settings
Функция принимает DataFrame, конвертированный в словарь, список поддоменов, название листа в settings для экспорта:
def add_subdomains_to_settings(project_settings, project_subdomains_list, export_sheet_name):
list_of_dicts = []
for domain in project_subdomains_list:
new_dict = {}
new_dict['project'] = domain
new_dict['domain_type'] = 'subdomain'
new_dict['main_domain_name'] = domain.split('.', 1)[1]
list_of_dicts.append(new_dict)
for element in list_of_dicts:
project_settings.append(element)
updated_project_settings = pd.DataFrame.from_dict(project_settings)
updated_project_settings.drop_duplicates(subset=['project'], inplace=True)
export_data_to_specified_sheet(updated_project_settings, export_sheet_name)
Объединяющая функция
Принимает User ID, словарь из DataFrame, срез по главным доменам (поле Domain Type, признак main), название листа в settings для экспорта:
def get_subdomains_from_webmaster_update_settings(user_id, project_settings, project_settings_slice, export_sheet_name):
for row in project_settings_slice:
project = row['project']
project_subdomains_hosts = request_yandex_webmaster(user_id, project)
project_subdomains_list = extract_subdomains_from_hosts(project_subdomains_hosts)
add_subdomains_to_settings(project_settings, project_subdomains_list, export_sheet_name)
Главная функция получение поддоменов из Яндекс Вебмастера и добавление в Settings
def update_settings_with_subdomains_main():
user_id = get_user_id()
#one_map
projects_one_map = get_projects_with_one_map()
projects_one_map_slice = projects_one_map[projects_one_map['domain_type'] == 'main'].to_dict('records')
projects_one_map = projects_one_map.to_dict('records')
get_subdomains_from_webmaster_update_settings(user_id, projects_one_map, projects_one_map_slice, 'one_map')
#many_maps
projects_many_maps = get_projects_with_many_maps()
projects_many_maps_slice = projects_many_maps[projects_many_maps['domain_type'] == 'main'].to_dict('records')
projects_many_maps = projects_many_maps.to_dict('records')
get_subdomains_from_webmaster_update_settings(user_id, projects_many_maps, projects_many_maps_slice, 'many_maps')
Запуск
Результат
Settings дополнен поддоменами по каждому проекту. В Domain Type указан признак subdomain. В Main Domain Name указан главный домен:

Создание ключей для поддоменов
Создание ключей и запись в таблицу
def replace_empty_key_value_in_settings(project_settings, sheet_name):
project_settings = project_settings.to_dict('records')
for row in project_settings:
if type(row['key']) != str:
row['key'] = secrets.token_hex(64)
projects_subdomain_with_keys = pd.DataFrame.from_dict(project_settings)
export_data_to_specified_sheet(projects_subdomain_with_keys, sheet_name)
Создание txt и добавление в папку по названию проекта
Для каждого отдельного поддомена должен быть свой отдельный ключ и файл, даже если поддомены формируются динамически, т.е. фактически это одна папка на сервере, меняется URL и подставляются названия городов в мета-теги. Уточнял этот момент в поддержке:

Функция принимает DataFrame и список поддоменов без ключа. С помощью isin() делает срез DataFrame по списку поддоменов без ключа:
def create_txt(project_settings, projects_subdomains_without_key_list):
projects_for_file_creating = project_settings[project_settings['project'].isin(projects_subdomains_without_key_list)]
projects_for_file_creating = projects_for_file_creating.to_dict('records')
for row in projects_for_file_creating:
subdomain, key, main_domain = row['project'], row['key'], row['main_domain_name']
create_private_key_txt(main_domain, subdomain, key)
Главная функция - создание ключей и добавление в таблицу, создание txt и добавление в папку
Происходит вызов всех созданных ранее функций. Сначала для проектов с листа one map, затем с листа many maps.
Загрузка данных в DataFrame.
Срез DataFrame по поддоменам, у которых нет ключа. Превращение среза в словарь.
Создание ключей и запись в таблицу replace_empty_key_value_in_settings().
Снова загрузка данных в DataFrame.
Для каждого поддомена создание txt-файла и добавление в папку create_txt().
def create_data_for_subdomains_main():
#one_map
projects_one_map = get_projects_with_one_map()
##Список поддоменов без ключа
projects_subdomains_without_key_list = projects_one_map[projects_one_map['key'].isna()]['project'].to_list()
replace_empty_key_value_in_settings(projects_one_map, 'one_map')
projects_one_map = get_projects_with_one_map()
create_txt(projects_one_map, projects_subdomains_without_key_list)
#many_maps
projects_many_maps = get_projects_with_many_maps()
#Список поддоменов без ключа
projects_subdomains_without_key_list = projects_many_maps[projects_many_maps['key'].isna()]['project'].to_list()
replace_empty_key_value_in_settings(projects_many_maps, 'many_maps')
projects_many_maps = get_projects_with_many_maps()
create_txt(projects_many_maps, projects_subdomains_without_key_list)
Запуск
Результат
В settings добавлены ключи для поддоменов:

В папки с проектами добавлены txt-файлы для поддоменов:
Добавление txt на сервер
Добавьте все txt-файлы на сервер в корневую папку вашего сайта.
Процесс выполнения IndexNow
Необходимые библиотеки:
import time
import requests
import json
import re
import traceback
import pandas as pd
from bs4 import BeautifulSoup
Загрузка данных из settings.xlsx
one map:
def get_projects_with_one_map():
return pd.read_excel(PROJECT_SETTINGS_PATH)
many maps:
def get_projects_with_many_maps():
return pd.read_excel(PROJECT_SETTINGS_PATH, sheet_name = 'many_maps')
Отчет об ошибках
def error_report():
print('Ошибка')
traceback.print_exc()
Парсинг Sitemap
Функции принимают адрес Sitemap и возвращают URL в формате set.
one map:
def parse_project_with_one_map(project_sitemap):
try:
request = requests.get(project_sitemap)
soup = BeautifulSoup(request.text, 'xml')
sitemap_url_set = set()
for url in soup.find_all('loc'):
sitemap_url_set.add(url.text)
return sitemap_url_set
except:
error_report()
many maps:
def parse_project_with_many_maps(project_sitemap):
try:
request = requests.get(project_sitemap)
soup = BeautifulSoup(request.text, 'xml')
maps = [sitemap.text for sitemap in soup.find_all('loc')]
print(f'Количество карт: {len(maps)}')
sitemap_url_set = set()
i=0
for sitemap in maps:
i+=1
print(f'Карта №: {i}')
request = requests.get(sitemap)
print(sitemap, request.status_code)
soup = BeautifulSoup(request.text, 'xml')
soup_list = soup.find_all('loc')
print(f'Количество URL: {len(soup_list)}')
for url in soup.find_all('loc'):
sitemap_url_set.add(url.text)
print(f'Длина общего списка: {len(sitemap_url_set)} URL')
time.sleep(10)
return sitemap_url_set
except:
error_report()
Актуализация CSV базы
Открытие csv файла
def open_project_csv_base(project_path, project_name):
try:
return pd.read_csv(PROJECT_CSV_BASE_PATH.format(project_path, project_name)).dropna().to_dict('records')
except:
error_report()
Список URL в csv конвертировать в set
def get_url_set_from_project_csv_base(project_csv_base):
try:
project_base_url_set = set()
for row in project_csv_base:
project_base_url_set.add(row['url'])
return project_base_url_set
except:
error_report()
Список URL в csv конвертировать в list
def get_url_list_from_project_csv_base(project_csv_base):
try:
project_base_url_list = []
for row in project_csv_base:
project_base_url_list.append(row['url'])
return project_base_url_list
except:
error_report()
Определение новых URL (есть в парсинге Sitemap, нет в CSV)
Функция принимает название проекта, URL из парсинга в формате set, URL из csv в формате set. Новые URL получают статус NEW в CSV:
def find_new_urls_and_set_status_in_csv(project_name, sitemap_url_list_set, project_base_url_list_set):
try:
project_csv_base = open_project_csv_base(project_name, project_name)
in_sitemap_not_in_csv_base = sitemap_url_list_set - project_base_url_list_set
print(f'Количество новых URL (есть в SITEMAP, но нет в CSV базе): {len(in_sitemap_not_in_csv_base)}')
if len(in_sitemap_not_in_csv_base) > 0:
for element in in_sitemap_not_in_csv_base:
new_dict = {}
new_dict['url'] = element
new_dict['status'] = 'NEW'
project_csv_base.append(new_dict)
print('Экспорт','\n')
export_csv_base = pd.DataFrame.from_dict(project_csv_base)
export_csv_base.to_csv(PROJECT_CSV_BASE_PATH.format(project_name, project_name), index=False)
except:
error_report()
Определение URL без изменений (есть в CSV, есть в Sitemap)
Такие URL получают статус UPDATED:
def find_existing_urls_and_set_status_in_csv(project_name, sitemap_url_list_set, project_base_url_list_set):
try:
project_csv_base = open_project_csv_base(project_name, project_name)
in_sitemap_and_in_csv_base = sitemap_url_list_set.intersection(project_base_url_list_set)
print(f'Количество URL без изменений: {len(in_sitemap_and_in_csv_base)}')
for row in project_csv_base:
for url in in_sitemap_and_in_csv_base:
if row['url'] == url:
row['status'] = 'UPDATED'
print('Экспорт','\n')
export_csv_base = pd.DataFrame.from_dict(project_csv_base)
export_csv_base.to_csv(PROJECT_CSV_BASE_PATH.format(project_name, project_name), index=False)
except:
error_report()
Определение удаленных URL (есть в CSV, нет в Sitemap)
Такие URL получают статус DELETED:
def find_deleted_urls_and_set_status_in_csv(project_name, sitemap_url_list_set, project_base_url_list_set):
try:
project_csv_base = open_project_csv_base(project_name, project_name)
in_csv_base_not_in_sitemap = project_base_url_list_set - sitemap_url_list_set
print(f'Количество удаленных с сайта URL (есть в CVS, нет в SITEMAP): {len(in_csv_base_not_in_sitemap)}')
if len(in_csv_base_not_in_sitemap) > 0:
for row in project_csv_base:
for url in in_csv_base_not_in_sitemap:
if row['url'] == url:
row['status'] = 'DELETED'
print('Экспорт','\n')
export_csv_base = pd.DataFrame.from_dict(project_csv_base)
export_csv_base.to_csv(PROJECT_CSV_BASE_PATH.format(project_name, project_name), index=False)
except:
error_report()
Объединяющая функция - Проверка и сопоставление URL в CSV c данными из Sitemap
def set_status_in_project_csv_base(project_name, sitemap_url_list_set, project_base_url_list_set):
### STATUS - NEW
csv_base_with_new_urls = find_new_urls_and_set_status_in_csv(project_name,
sitemap_url_list_set,
project_base_url_list_set)
### STATUS - UPDATED
csv_base_with_updated_urls = find_existing_urls_and_set_status_in_csv(project_name,
sitemap_url_list_set,
project_base_url_list_set)
### STATUS - DELETED
csv_base_with_deleted_urls = find_deleted_urls_and_set_status_in_csv(project_name,
sitemap_url_list_set,
project_base_url_list_set)
Отправка в IndexNow
Функция, отправляющая не более 10 тыс. URL
Принимает в качестве аргументов хост, ключ, главный домен и название отправляемого проекта. Функция работает, пока не будет получен ответ 200. Если ответ больше 202, процесс останавливается с информацией об ошибке:
def send_urls_index_now(host, key, main_domain, project_name, url_list):
status_code = 0
while status_code != 200:
data = {'host': f'{host}',
'key': f'{key}',
'keyLocation': f'https://{main_domain}/{project_name}_indexnow_key.txt',
'urlList': url_list
}
#Уберите комменты, если нужно посмотреть, какие данные отправляются
#print(data['host'])
#print(data['key'])
#print(data['keyLocation'])
#print(data['urlList'])
request = requests.post(YANDEX_URL, json=data)
status_code = request.status_code
if status_code == 202:
print(f'Ответ {status_code}, ожидание....')
time.sleep(5)
if status_code == 200:
print(f'IndexNow - количество отправленных страниц: {len(url_list)},'
f' ответ: {status_code}','\n')
return status_code
if status_code > 202:
print(f'Ошибка - ответ {status_code}')
print(f'Причина {request.text}')
return status_code
break
Функция, отпраляюшая более 10 тыс. URL
За один раз можно отправить список длиной не более 10 тысяч URL. Эта функция отправляет большой список частями:
def send_multiple_url_lists_index_now(project_name, project_key, url_list_from_project_csv_base):
step = 10000
end = len(url_list_from_project_csv_base)
start = 0
total_sent_page_quantity = 0
check_status_code = 0
for number in range(start, end, step):
limited_url_list = url_list_from_project_csv_base[number:number+step]
check_status_code = send_urls_index_now(host=project_name,
key=project_key,
main_domain=project_name,
project_name=project_name,
url_list=limited_url_list)
if check_status_code > 202:
return check_status_code
break
total_sent_page_quantity += len(limited_url_list)
start += step
return check_status_code
print(f'Общее количество отправленных страниц: {total_sent_page_quantity}','\n')
Получение списка поддоменов
Происходит срез DataFrame по столбцу Main domain name:
def get_subdomain_list(projects_settings, project_name):
try:
projects_subdomain = projects_settings[(projects_settings['domain_type'] == 'subdomain')&
(projects_settings['main_domain_name'] == project_name)].to_dict('records')
return projects_subdomain
except:
error_report()
Генерация адресов для поддоменов из основного csv файла
Список URL для поддомена получается из CSV. Основной домен заменяется на поддомен:
def generate_url_list_for_subdomains(project_domain, project_subdomain, url_list):
try:
new_url_list_with_subdomain_name = []
for url in url_list:
new_url_list_with_subdomain_name.append(re.sub(project_domain, project_subdomain, url))
return new_url_list_with_subdomain_name
except:
error_report()
Процесс отправки страниц в IndexNow
В процессе определяется длина списка URL и наличие поддоменов:
def send_urls_indexnow_algorithm(projects_settings, project_name, project_key, project_domain):
print(f'Проект: {project_name}')
project_subdomains_list = get_subdomain_list(projects_settings, project_name)
print(f'Количество доменов: {len(project_subdomains_list)}')
project_csv_base = open_project_csv_base(project_name, project_name)
url_list_from_project_csv_base = get_url_list_from_project_csv_base(project_csv_base)
print(f'Количество URL в базе: {len(url_list_from_project_csv_base)}','\n')
if len(url_list_from_project_csv_base) < 10000:
try:
check_status_code = send_urls_index_now(host=project_name,
key=project_key,
main_domain=project_name,
project_name=project_name,
url_list=url_list_from_project_csv_base)
if check_status_code > 202:
print(f'Процесс для проекта {project_name} остановлен')
if check_status_code <= 202:
if len(project_subdomains_list) > 0:
for row in project_subdomains_list:
project_subdomain, subdomain_key = row['project'], row['key']
print(f'Поддомен проекта: {project_subdomain}')
new_url_list_with_subdomain_name = generate_url_list_for_subdomains(project_domain=project_name,
project_subdomain=project_subdomain,
url_list = url_list_from_project_csv_base)
send_urls_index_now(host=project_subdomain,
key=subdomain_key,
main_domain=project_subdomain,
project_name=project_subdomain,
url_list=new_url_list_with_subdomain_name)
except:
error_report()
if len(url_list_from_project_csv_base) > 10000:
try:
check_status_code = send_multiple_url_lists_index_now(project_name,
project_key,
url_list_from_project_csv_base)
if check_status_code > 202:
print(f'Процесс для проекта {project_name} остановлен')
if check_status_code <= 202:
if len(project_subdomains_list) > 0:
for row in project_subdomains_list:
project_subdomain, subdomain_key = row['project'], row['key']
print(f'Поддомен проекта: {project_subdomain}')
new_url_list_with_subdomain_name = generate_url_list_for_subdomains(project_domain=project_name,
project_subdomain=project_subdomain,
url_list = url_list_from_project_csv_base)
send_multiple_url_lists_index_now(project_name,
project_key,
new_url_list_with_subdomain_name)
except:
error_report()
Удаление страниц 404 из CSV после завершения отправки в IndexNow
После завершения отправки страниц в IndexNow удаляются URL со статусом DELETED из CSV, чтобы не отправлять эти страницы при следующем использовании программы:
def delete_404_pages_from_base(project_name):
try:
project_csv_base = pd.read_csv(PROJECT_CSV_BASE_PATH.format(project_name, project_name))
quantity404_pages = len(project_csv_base[project_csv_base['status'] == 'DELETED']['url'])
quantity_new_pages = len(project_csv_base[project_csv_base['status'] == 'NEW']['url'])
quantity_updated_pages = len(project_csv_base[project_csv_base['status'] == 'UPDATED']['url'])
print(f'Количество страниц NEW: {quantity_new_pages}')
print(f'Количество страниц UPDATED: {quantity_updated_pages}')
print(f'Количество страниц 404: {quantity404_pages}','\n')
if quantity404_pages > 0:
project_csv_base.drop(project_csv_base[project_csv_base['status'] == 'DELETED'].index, inplace=True)
print(f'Удалено: {quantity404_pages}','\n')
project_csv_base.to_csv(PROJECT_CSV_BASE_PATH.format(project_name, project_name),index=False)
except:
error_report()
Главная функция отправки в IndexNow для проектов с одной картой
def send_project_one_map_to_indexnow_main():
projects_one_map = get_projects_with_one_map()
projects_main_domain = projects_one_map[projects_one_map['domain_type'] == 'main'].to_dict('records')
for project in projects_main_domain:
project_name, project_key = project['project'], project['key']
send_urls_indexnow_algorithm(projects_settings=projects_one_map,
project_name=project_name,
project_key=project_key,
project_domain=project_name)
delete_404_pages_from_base(project_name)
Главная функция отправки в IndexNow для проектов с мульти картой
def send_project_many_maps_to_indexnow_main():
projects_many_maps = get_projects_with_many_maps()
projects_main_domain = projects_many_maps[projects_many_maps['domain_type'] == 'main'].to_dict('records')
for project in projects_main_domain:
project_name, project_key = project['project'], project['key']
send_urls_indexnow_algorithm(projects_settings=projects_many_maps,
project_name=project_name,
project_key=project_key,
project_domain=project_name)
delete_404_pages_from_base(project_name)
Запуск
В процессе работы функции принтят сведения о процессе:
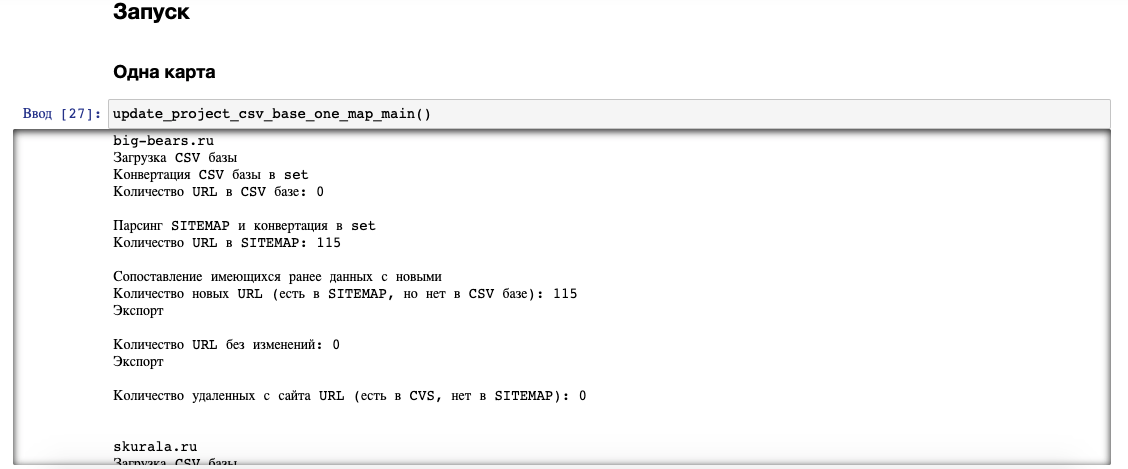
Пример отправки в IndexNow и ответ с ошибкой:
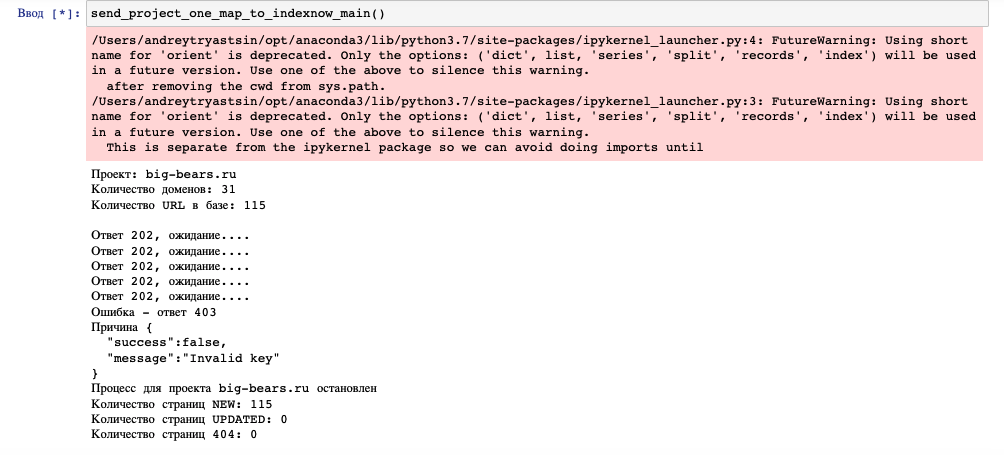
Пример успешной отправки основного домена и поддоменов:




