Автоматизация - Анализ поисковой выдачи, кластеризация по серпам с помощью Python
Содержание:
В статье о создании семантического ядра в разделе «Можно ли обойтись без семантического ядра» я упоминал о важности анализа поисковой выдачи по каждой группе запросов. Иногда этот этап можно пропустить или просто проверить поисковую выдачу по нескольким фразам с коммерческими словами «купить», «цена» и т.д. и без них. Таким образом можно обнаружить разделение на информационную и коммерческую выдачу, об этом подробно описано в нашем кейсе.
Простой проверкой можно обойтись, если вы продвигаете интернет-магазин, который продает товары из самых мейнстримных тематик, например одежду, косметику, автомобильные шины и диски. Тщательная проверка состава поисковой выдачи поможет продвинуть какие-либо b2b или b2c услуги или интернет-магазин со сложными товарами, например эксклюзивными сортами меда для ценителей.
Что дает анализ поисковой выдачи
-
Понимание, какая страница ранжируется по запросу – главная, категория, карточка, страница с ценами, блог, отзывы и другое.
-
Возможность сразу подготовить такие же типы страниц как на поиске и оптимизировать их под соответствующие запросы.
-
Если вы решите продвигать другие страницы, руководствуясь не SEO, а пониманием своего бизнеса и клиентов, вы будете знать, какие страницы предпочитает поисковая система. На этапе оценки позиций станет понятно, подходит ли подготовленная вами структура, или нужно изменить подход и пытаться продвигать другие страницы, типы которых вы выявили на этапе анализа поисковой выдачи.
-
Получите список сайтов конкурентов, которые ранжируются по вашему списку запросов.
Что нужно для анализа поисковой выдачи
Подготовленный список запросов
Для анализа выдачи я использую список фраз, который прошел очистку, автоматическую кластеризацию и ручную доработку - об этом написано в статье Автоматизация - Кластеризация поисковых запросов на Python. Т.е. собирать URL из поисковой выдачи я буду по списку, в котором нет мусорных фраз со стоп-словами или нерелевантных фраз. Только адекватные фразы, которые соответствуют по смыслу продвигаемому сайту.
Для примера буду использовать семантику сайта MuchEnergy, который оказывает услуги подключения электричества и юридического сопровождения при решении вопросов с энергетическими компаниями.
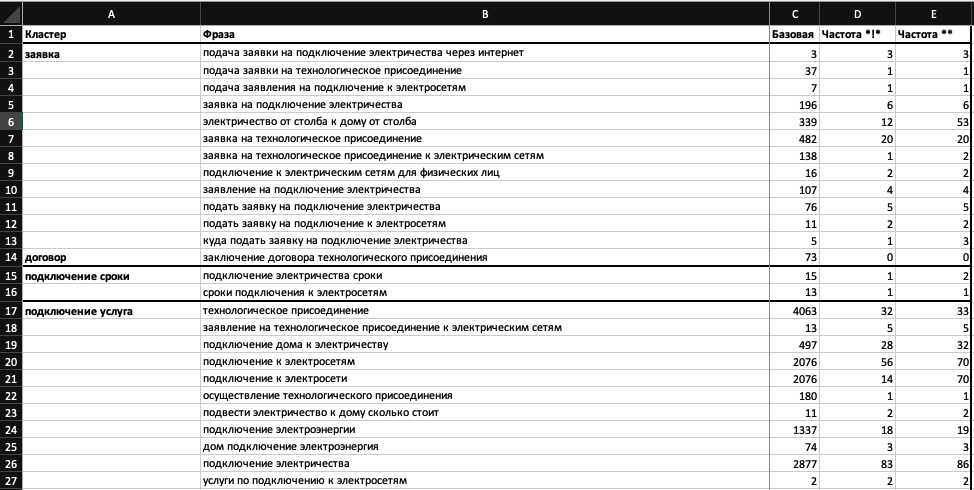
Сбор урлов из поисковой выдачи
Для этого можно использовать Key Collector.
На каждую фразу собралось по 10 URL из выдачи:

Добавляю таблицу из коллектора в файл с кластеризованными фразами на разных листах.
Анализ ТОП10 по каждому запросу
Подход 1 – ручная проработка в экселе
Небольшой список фраз несложно проработать в экселе. Можно фильтровать список по фразам, вручную перебирая фразы или воспользовавшись поиском, чтобы отфильтровывать целые кластеры:
Можно сделать сводную таблицу:
И фильтровать в таком режиме:

В этом процессе нет конкретных критериев для определения характеристик поисковой выдачи. Вы просматриваете URL ваших конкурентов и пытаетесь определить, какой характер носят эти страницы – ранжируется статья или коммерческая страница, страница с описанием услуги или отдельная страница с прайсами, вложенная страница или главная и т.д. Вы проводите собственное эмпирическое исследование, в результате которого планируете, какую страницу собственного сайта будете пытаться продвигать.
Выводы о характере выдачи я пишу в соседнюю колонку в качестве комментария:

-
Инфо – когда на выдаче преобладают информационные ресурсы. Если буду уверен, что кластер носит информационный характер, для продвижения буду создавать страницу, которая будет обладать всеми атрибутами статьи – картинки, схемы, видео, ответы на ключевые вопросы по темею.
-
Коммерческий – когда на выдаче явно преобладают страницы с услугами.
-
Смешанный – когда выдача состоит из информационных страниц, форумов, соц сетей, агрегаторов, страниц с услугами. Это актуально для компании MuchEnergy, на примере которой пишу эту статью – низкая конкуренция и частотность фраз, по многим запросам поиск показывает смешанную выдачу.
При этом внутри логических групп, где фразы объединены по смыслу может быть часть фраз, у которых характер я определил как информационный, а у части – коммерческий, например как в группе «столб». Конкретно в этой ситуации вместе с заказчиком будем создавать коммерческую страницу, и на этапе проверки позиций станет ясно, получается ли продвинуть информационные запросы, или все-таки отдельная информационная страница необходима.
Рядом с комментариями о характере выдачи создаю дополнительное поле, где фиксирую URL страницы, которую буду продвигать – напротив кластера пишу адрес существующей подходящей под запросы страницы или комментарий о том, какую страницу нужно создать. На этапе проверки позиций это поле пригодится для сопоставления запланированных URL с адресами, которые реально ранжируются по запросу.
Подход 2 – автоматическая кластеризация в сервисах
Такой метод называют «кластеризая по топу» или «кластеризация по серпам» (SERP – Search engine result page – Страница результатов поисковой выдачи).
Некоторые программы и сервисы предоставляют возможность кластеризации по поисковой выдаче. Это платный вариант – вы платите сервисам за объем слов или за лицензию Key Collector. Не буду подробно останавливаться на этом пункте. Обязательно изучите и попробуйте этот вариант кластеризации.
Key Collector: группировка по поисковой выдаче, группировка по конкурентам.
Подход 3 – автоматическая кластеризация по серпам с помощью Python
Еще один вариант кластеризации на Python, опубликованный Михаилом Жуковцом в статье на Searchengines. Первый вариант кластеризации описан в этой статье.
Как использовать код из статьи
-
файл serps_clustering.ipynb с кодом, который приведен в статье;
-
исходная таблица: таблица sem_yadro_krovelnye_raboty.xlsx с 2 листами:
-
кластеризованные по смыслу фразы,
-
ТОП10 поисковой выдачи Яндекса по каждой фразе.
-
таблица с результатами gotovoe_sem_yadro_krovelnye_raboty.xlsx.
Запустите Анаконду.
Запустите Jupyter Notebook и откройте скачанный файл serps_clustering.ipynb.
Загрузка библиотек
import pandas as pd
from openpyxl import load_workbook
from sklearn.feature_extraction.text import CountVectorizer
from scipy.cluster.hierarchy import linkage, fcluster
Pandas – инструмент для работы с данными. С его помощью легко загружать и экспортировать таблицы, осуществлять над ними различные манипуляции.
Openpyxl – библиотека для чтения и редактирования Excel.
Sklearn – библиотека для машинного обучения. Из всего арсенала будет использован CountVectorizer для векторизации данных.
Scipy – библиотека для расчетов. Будет использован linkage, fcluster для кластеризации.
Загрузка данных
Загрузка данных таблицы xlsx с листа “serp” - ТОП10 поисковой выдачи Яндекса по каждой фразе:
df = pd.read_excel('sem_yadro_krovelnye_raboty.xlsx', sheet_name = 'serp')Поиск и удаление строк с пропусками:
df.dropna(inplace=True)
Переименование столбцов:
df.rename(columns={'URL [Yandex]':'URL', 'Title [Yandex]':'Title'}, inplace=True)Отбрасывание строк, в URL которых есть "yandex":
filt =~(df['URL'].str.contains('yandex', regex=True))
df = df[filt]
Сервисы Яндекса могут встречаться по каждому запросу и занимать много позиций в выдаче. Есть вероятность, что алгоритм кластеризации будет выбирать урлы Яндекса как самые релевантные, поэтому лучше исключить их из выборки.
Кластеризация
Векторизация
На этом этапе URL для кластеризации превращаются в понятную для алгорима кластеризации форму.
Создание экземпляра класса векторизатора:
vectorizer = CountVectorizer(min_df=2, token_pattern='[^\ ]+')
Обучение векторизатора:
ml_df = vectorizer.fit_transform(df['URL'])
Кластеризация
link_ml_df = linkage(ml_df.toarray(), method='ward')
df['Кластер_serp'] = fcluster(link_ml_df, 70, criterion = 'maxclust')
Обратите внимание на второй параметр:

Это ручная настройка количества кластеров, на которые будут разбиты данные. Я просто решил, что 70 групп мне подойдет, вы можете попробовать другие варианты.
Алгоритм работает таким образом, что образуется один или несколько крупных кластеров, которые содержат признаки более мелких групп:
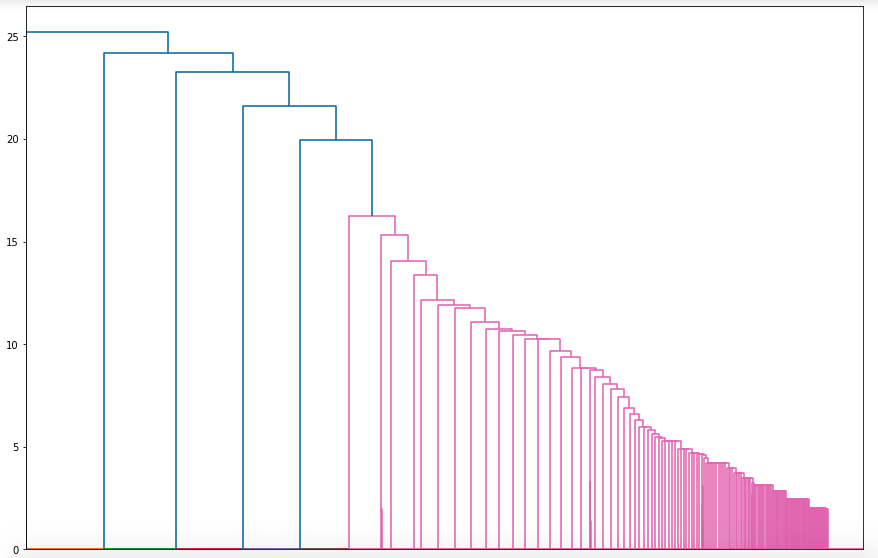
Подсчет значений внутри кластеров:
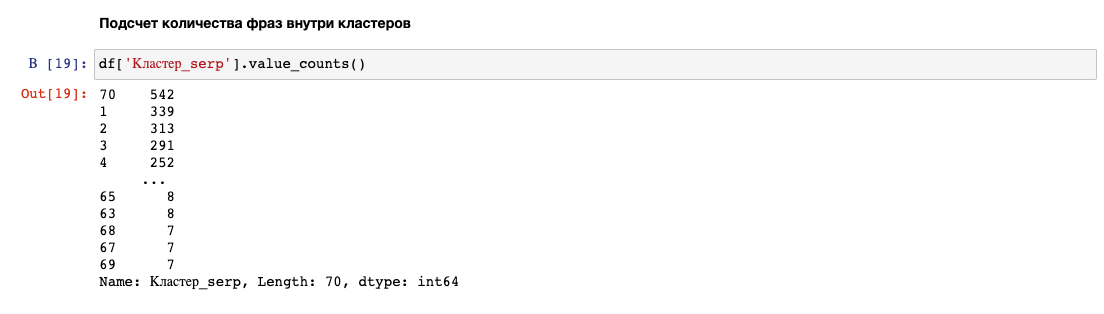
Большие группы под номером 70, 1, 2, 3 и 4.
Я предпочитаю отбрасывать строки с номером кластера, в котором самое большое количество значений:
cluster_filtering = df['Кластер_serp'] != 70
df = df[cluster_filtering]
Можно отбросить сразу несколько кластеров:
cluster_filtering = (df['Кластер'] != 70)&(df['Кластер'] != 1)&(df['Кластер'] != 2)
df = df[cluster_filtering]
Экспорт результатов
Экспорт результатов кластеризации на новый лист «Кластеризация SERP» в исходную таблицу:
with pd.ExcelWriter('sem_yadro_krovelnye_raboty.xlsx', engine='openpyxl') as report:
report.book = load_workbook('sem_yadro_krovelnye_raboty.xlsx')
df.to_excel(report, 'Кластеризация SERP', index=False)На этом кластеризация завершена, можно переходить к детальному рассмотрению результатов в Excel.
Но для полноты картины можно сделать еще пару операций.
Добавление номера кластера по серпам в таблицу с кластеризованными по смыслу фразами
Загрузка таблицы с первого листа с кластеризованными по смыслу фразами:
df_clustered_by_words = pd.read_excel('sem_yadro_krovelnye_raboty.xlsx')Удаление дубликатов фраз в таблице с кластеризованными серпами и удаление ненужных столбцов:
df_clustered_by_serps = df.drop_duplicates(subset='Фраза')
df_clustered_by_serps = df_clustered_by_serps[['Фраза','Кластер_serp']]
Слияние двух таблиц:
new_df = df_clustered_by_words.merge(df_clustered_by_serps, on='Фраза')
Получаем номер кластера напротив каждой фразы:
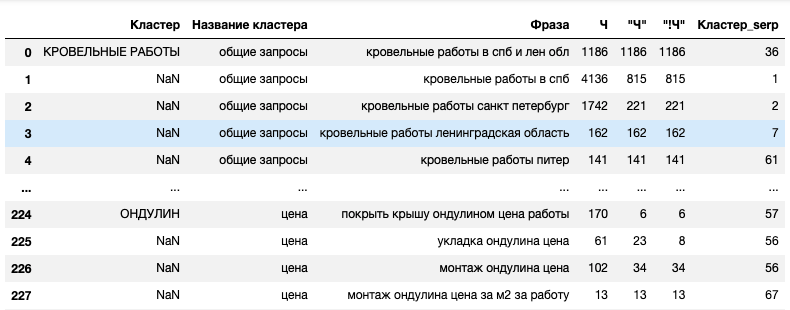
Экспорт
Создание нового листа в исходной таблице:
with pd.ExcelWriter('sem_yadro_krovelnye_raboty.xlsx', engine='openpyxl') as report:
report.book = load_workbook('sem_yadro_krovelnye_raboty.xlsx')
new_df.to_excel(report, 'ядро+кластер serp', index=False)Определение списка конкурентов
Запишем на отдельный лист список доменов, которые встречаются в ТОП10 по нашему списку фраз.
Получение домена из URL и подсчет количества:
domain_list = (df['URL']
.apply(lambda x: x.split('/'))
.apply(lambda x: x[2])
.value_counts().reset_index()
.rename(columns={'index':'Домен','domain':'Видимость'})
)
Получаем список доменов и количество раз, когда встречаются адреса этих доменов – это можно назвать уровнем видимости конкурентов по нашему списку фраз:

Экспорт на новый лист
with pd.ExcelWriter('sem_yadro_krovelnye_raboty.xlsx', engine='openpyxl') as report:
report.book = load_workbook('sem_yadro_krovelnye_raboty.xlsx')
domain_list.to_excel(report, 'Список конкурентов', index=False)Анализ результатов кластеризации
В результате получается таблица, которая содержит несколько листов:

-
«Ядро» - список фраз, кластеризованный по словам, оформленный визуально для лучшего восприятия.
-
«Serp» - список URL из ТОП10 Яндекса по каждой фразе, это список можно фильтровать или сделать из него сводную таблицу.
-
«Ядро+кластер serp» - результат слияния данных с листа «Ядро» и «Кластеризация SERP», если данные покажутся полезными, можно скопировать столбец кластер в оформленную таблицу «Ядро».
-
«Список конкурентов» - уникальные домены и их уровень видимости по этому списку запросов.
Как интерпретировать результаты кластеризации
Можно начать анализ с листа «Кластеризация SERP», фильтровать столбец «Кластер» и пытаться выявить признаки URL, по которым алгоритм осуществлял кластеризацию:

Или пойти с листа «Ядро+кластер serp». Нужно посмотреть, какие номера кластеров присвоились каждой фразе, перейти на лист «Кластеризация SERP» и нафильтровать нужные номера.
Например, общие запросы по кровельным работам имеют разные кластеры – 1,2,7,36,61:
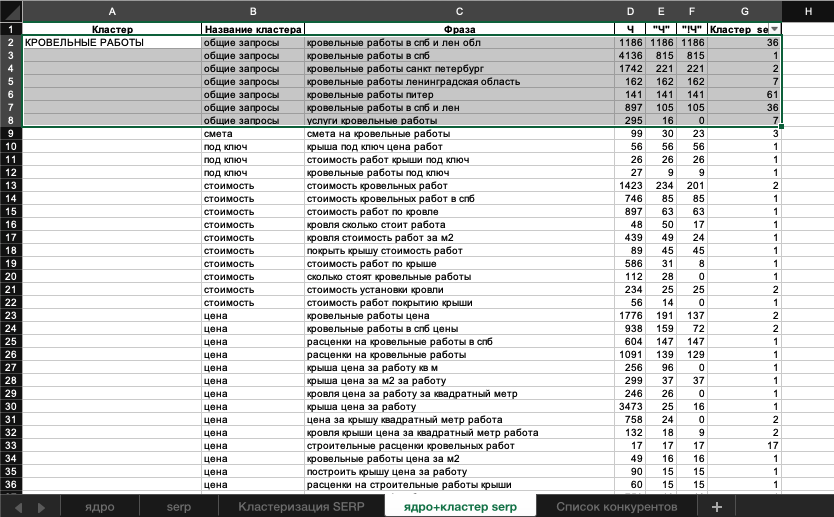
Фильтрую по этим номерам лист «Кластеризация SERP». Кластер 36:
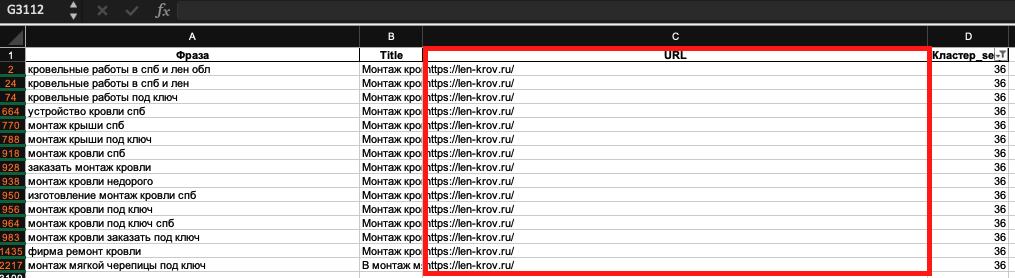
Эта группа сформирована по главной странице.
Кластер 61:

В этой группе вложенная страница – категория.
Кластер 7:
Центром для этого кластера стал домен Avito. Можно игнорировать этот кластер, т.к. авито нам не подскажет, какую страницу лучше подготовить для нашего сайта.
Кластер 1,2:
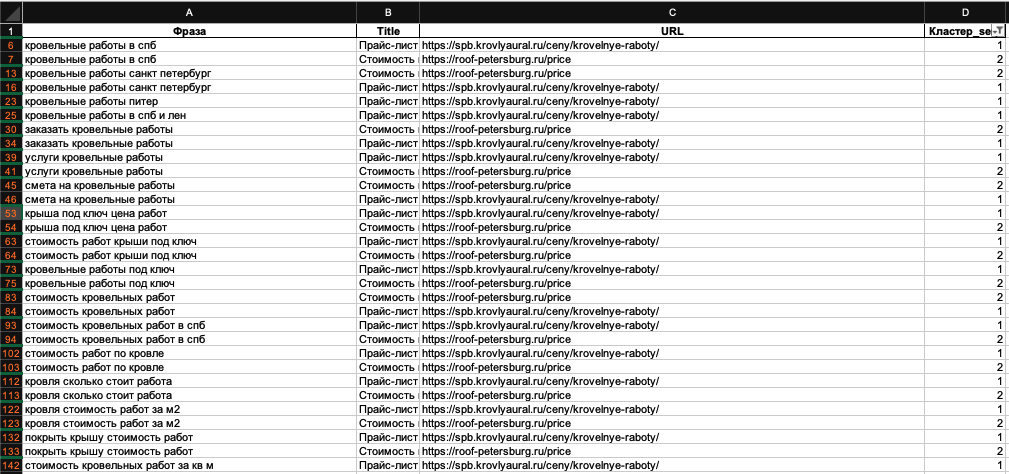
Большие группы, в которых URL объединены одним признаком – это вложенные страницы с ценами и прайсами.
Какие предположения можно выдвинуть на счет кластера с общими запросами по кровельным работам?
Для продвижения этих запросов нам может подойти главная или вложенная страница. Еще у нас есть очень большая группа запросов, где основной признак URL – вложенная страница с ценами. В этой группе оказались не только фразы со словами «цена, стоимость, смета», но еще и общие запросы вроде «кровельные работы в спб».
Можно попробовать оптимизировать главную под общие запросы и нужно обязательно создать страницу с ценами и прайс-листами для оптимизации соответствующих запросов. На этапе проверки позиций определить, какие страницы были выбраны поиском для ранжирования по запросам. Возможно будет все четко – по общим запросам будет показываться главная или категория, а по запросам со словами «цена,стоимость» - вложенная страница, но возможен вариант, что общие запросы начнут «мигать» - по ним будет показывать то главная, то перетягивающая на себя релевантность страница с ценами, в этой ситуации придется принимать новое решение. Но еще можно попробовать сразу оптимизировать общие и коммерческие запросы на страницу с ценами, особенно если у бизнеса более широкий профиль, и главная может подойди для каких-нибудь других общих запросов.
Выводы статьи
Изучив состав поисковой выдачи, вы лучше поймете, каким образом оптимизировать сайт под какие-либо поисковые запросы. В некоторых случаях продвижение без прохождения этого этапа может быть затруднительным.
Для сбора URL из ТОПа поисковой выдачи используйте подготовленный и очищенный список запросов.
Сбор URL можно сделать с помощью Key Collector.
Чтобы сделать анализ можно использовать:
-
Excel – используйте режим сводных таблиц и фильтр.
-
Автоматическую кластеризацию в сервисах.
-
Алгоритм кластеризации на Python, который представлен в статье.


