Автоматизация - Кластеризация поисковых запросов на Python
Содержание:
- Библиотеки
- Загрузка ключевых фраз
- Загрузка дополнительных файлов
- Удаление стоп-слов
- Лемматизация ключевых слов
- Векторизация
- Кластеризация
- Постобработка:
- Определение названия кластера
- Определение длины фраз
- Определение города
- Определение является ли запрос информационным
- Определение является ли запрос коммерческим
- Экспорт
- Ручная доработка списка запросов
В 2016 году мне попалась интересная статья на searchengines с объяснением процесса автоматической кластеризации ключевых слов на языке Python, на тот момент я работал сеошником уже год и не понаслышке знал, что перебирать слова руками, используя базовые функции Excel, очень монотонно, трудно, долго и непродуктивно. Выражаю огромный респект Михаилу Жуковцу (автору) за статью, которая показала мне, что рутинные сложные задачи можно автоматизировать и значительно ускорить и вдохновила меня заниматься программированием.
Код на Python из этой статьи, вы можете скачать на GitHub. Я использовал код Михаила и внес некоторые изменения.
Возможно, вас напрягут термины «машинное обучение», «векторизация», «лемматизация», которые встречаются в статье. Пугаться точно не стоит, этот скрипт легко использовать без вникания вглубь этих понятий.
Как использовать код из статьи
Установите питон и сборку библиотек Anaconda.
Скачайте папку с Гитхаба. В ней будет:
-
файл с кодом keyword_clustering.ipynb,
-
исходный список слов, который используется для кластеризации в этом примере keywords.xlsx,
-
таблица с результатами кластеризации и дополнительной обработки ready_table.xlsx,
-
дополнительные таблицы-словари в формате xlsx,
-
таблица ready_table_clean.xlsx с финальной версией списка запросов после ручной доработки.
Запустите Анаконду.
Запустите Jupyter Notebook и откройте скачанный файл keyword_clustering.ipynb:
Чтобы запустить код нажмите на первую ячейку и кнопку «Запуск»:
Подробная статья по работе в Jupyter Notebook.
Загрузка библиотек
import pandas as pd
import numpy as np
from pymorphy2 import MorphAnalyzer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
Pandas – инструмент для работы с данными. С его помощью легко загружать и экспортировать таблицы, осуществлять над ними различные манипуляции.
Numpy – старший брат pandas. В этом скрипте используется для вычислений.
Pymorphy2 – морфологический анализатор. Используется для приведения слов к словарной форме (лемматизация).
Sklearn – библиотека для машинного обучения. Из всего арсенала будет использован TfidfVectorizer для векторизации слов, KMeans – алгоритм кластеризации.
Загрузка ключевых фраз
Для загрузки данных можно использовать xlsx, csv и txt файлы. Данные записываются в переменную df (общепринятое сокращение от DataFrame).
xlsx
df = pd.read_excel('keywords.xlsx')csv
df = pd.read_csv('keywords.csv')txt
keywords = [phrase.rstrip() for phrase in open('keywords.txt')]
df = pd.DataFrame(keywords, columns=['Фраза'])В примере я буду использовать xlsx. В Jupyter строки с загрузкой из csv и txt закомментированы #:
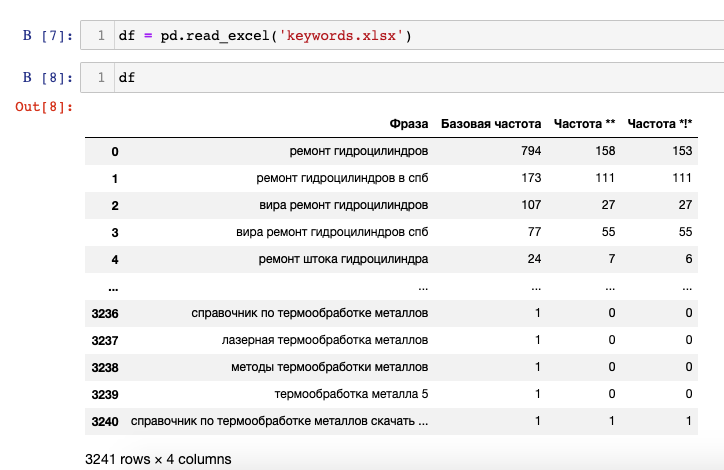
Я загружаю файл со столбцами «Фраза», «Базовая частота», «Частота **», «Частота *!*»:
Вы можете загрузить файлы с любыми другими столбцами, например «Источник» с уточнениями откуда была получена фраза – из Вордстата или поисковых подсказок. Все фразы будут кластеризованы с любыми другими признаками.
Можно загрузить экспортированый файл из Key Collector без удаления ненужных столбцов:

Оставить только нужные столбцы:
Оставить только нужные столбцы:
df = df[['Фраза', 'Источник', 'Базовая частота', 'Частота * * [YW]', 'Частота *!* [YW]']]
Удалить какие-то конкретные, например «IsChecked» и «Дата добавления»:
df.drop(columns=['IsChecked', 'Дата добавления'], axis=1, inplace=True)
Удалить срез, например начиная с '[QUERY] [YW]', заканчивая 'ChildInfo':
df.drop(df.loc[:, '[QUERY] [YW]':'ChildInfo'].columns, axis = 1, inplace=True)
Загрузка дополнительных файлов
Загружаю дополнительные файлы-словари в формате xlsx, которые будут использоваться для определения признаков во фразах. Каждый список вы можете расширить как угодно, просто добавьте свои слова в общий столбец.
Список стоп-слов - spisok_stop_slov:
list_of_stop_words = pd.read_excel('spisok_stop_slov.xlsx', names=['stop_slova'])Список городов – spisok_gorodov:
list_of_cities = pd.read_excel('spisok_gorodov.xlsx', names=['goroda'])Список предлогов – spisok_predlogov:
list_of_pretext = pd.read_excel('spisok_predlogov.xlsx', names=['predlogi'])Список «информационных слов» - spisok_vopros_slov:
list_of_questions = pd.read_excel('spisok_vopros_slov.xlsx', names=['vopros'])Список «коммерческих слов» - spisok_kommercheskih_slov:
list_of_commerce_words = pd.read_excel('spisok_kommercheskih_slov.xlsx', names=['komm'])Удаление стоп-слов
Если вы не указали стоп-фразы в Key Collector, можно удалить их на месте.
Разделение фраз на слова методом strip() и запись в новый столбец «Фраза по словам»:
df['Фраза_по_словам'] = df['Фраза'].str.split()
Функция для определения стоп-слова. В функцию передается разбитая на слова фраза, внутри начинается цикл, который перебирает все слова в списке стоп-слов (spisok_stop_slov) и сравнивает со всеми словами в каждой фразе:
def find_stop_words(splitted_phrase):
for word in list_of_stop_words['stop_slova']:
if word in splitted_phrase:
return 'stop'
Применение функции к столбцу «Фраза по словам», весь результат записывается в новый столбец «Содержит стоп слово»:
df['Содержит_стоп_слово'] = df['Фраза_по_словам'].apply(find_stop_words)
Появится новый столбец, который будет содержать отметку «stop», если в фразе будет стоп-слово.
Стоп-слова можно удалить. Отбрасывание строк, которые содержат «stop» в столбце «Содержит стоп слово»:
df.drop(df[df['Содержит_стоп_слово'] == 'stop'].index, inplace=True)
Столбцы, которые использовались для выявления стоп-слов можно удалить:
df.drop(columns = ['Содержит_стоп_слово', 'Фраза_по_словам'], inplace=True)
Лемматизация ключевых слов
Во фразах «ремонт гидроцилиндр», «ремонт гидроцилиндра» и «ремонт гидроцилиндров» один и тот же смысл, но алгоритм кластеризации «не поймет», что это разные склонения. Для этого каждое слово в фразах нужно привести в словарную форму.
Каждая фраза в столбце «Фраза» разбивается на слова, слова приводятся в словарную форму и записываются в новый столбец «Леммы»:
m = MorphAnalyzer()
df['Леммы'] = [' '.join([m.parse(word)[0].normal_form for word in x.split()]) for x in df['Фраза']]
Векторизация
В статье Михаила подробно описано, зачем нужна векторизация.
Цитата:
„Чтобы сделать наши ключевые слова удобными для обработки, необходимо провести их векторизацию. Звучит пугающе, но на самом деле все очень просто – все ключевые фразы разбиваются на уникальные слова и кодируются. По сути они преобразуются в большой список и дальше вместо каждого ключевого слова мы размещаем длинную строчку цифр, соответствющую нашему списку всех уникальных слов. Если слово есть в фразе – то ставим 1, если нет , то 0. Получается что-то вроде такой таблицы.“

„Поскольку все SEO-специалисты не понаслышке знают, что количество слов редко переходит в качество вместо CountVectroizer лучше использовать TfidfVectorizer. Он очень похож на предыдущий векторизатор, но вместо числа 1 или 0 проставляет значимость каждого слова рассчитывая её по Tf-Idf.“

Создание экземпляра класса TfidfVectorizer(min_df=1):
tvidf_v = TfidfVectorizer(min_df=1)
Обучение векторизатора леммам и преобразование набора данных:
vectorized_lemmas = tvidf_v.fit_transform(df['Леммы'])
Можете посмотреть, как выглядят ваши векторизованные данные:
pd.DataFrame(data=vectorized_lemmas.toarray(), columns=tvidf_v.get_feature_names(), index=df['Леммы'])
Кластеризация
Настройка кластеризатора:
km_clustering = KMeans(
n_clusters=int(np.round(np.divide(len(df['Леммы']), 5))),
init='k-means++',
n_init=10,
max_iter=300,
tol=0.0001
)
Недостатком алгоритма является необходимость указывать количество кластеров в параметре n_clusters, которые будут созданы и присвоены фразам. В этом примере для указания количества кластеров длина списка делится на 5.
Кластеризация. Номер кластера будет записан в новый столбец «Кластер»:
df['Кластер'] = km_clustering.fit_predict(vectorized_lemmas)
Чем больше фраз, тем дольше работает алгоритм. Если загрузить 30 тысяч ключевых слов, процесс может занять около 20 минут.
Каждой фразе присвоился номер кластера:
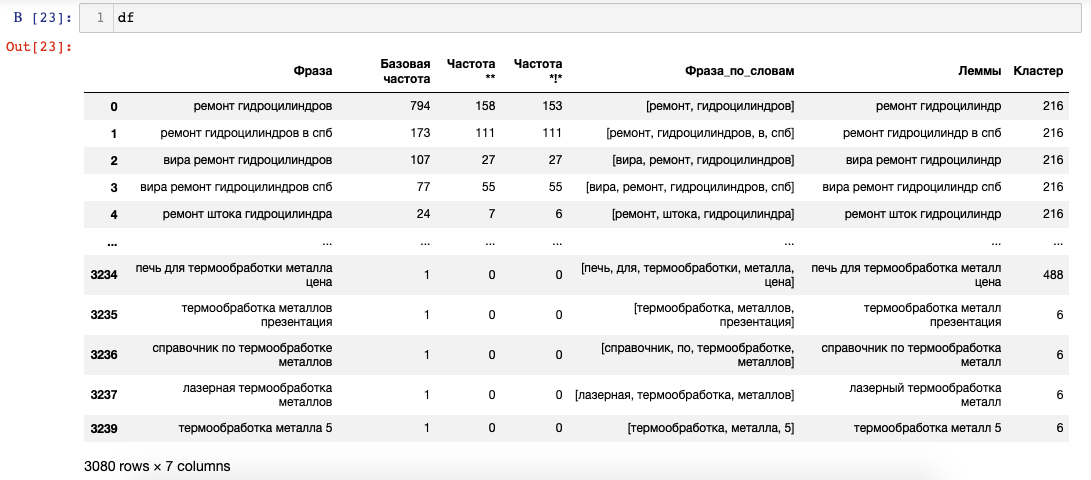
Фразы с одинаковым номером кластера разбросаны по всей таблице. Например, фильтрую таблицу по 45 номеру в столбце «Кластер»:
df[df['Кластер'] == 45]
Фразы расположены на отмеченных сточках таблицы:

Сортировка таблицы по возрастанию в столбце «Кластер»:
writer_kernel = pd.ExcelWriter('ready_table.xlsx', engine='xlsxwriter')
df.to_excel(writer_kernel)
writer_kernel.save()Этот метод не является идеальным и не решает всех задач по подготовке семантического ядра. Скорее всего в таблице будут нерелевантные фразы, слова из которых не были учтены в списке стоп-слов. Например, я кластеризовал фразы, которые собрал для продвижения услуг по металлообработке, но не учел, что в статистику попадут фразы со словами «уголок», «подрядчик», «оборудование» и многое другое. Или например, при сборе фраз по названию бренда Vesa (одежда для танцев), соберутся фразы про кронштейны для телевизоров Vesa. В статистику могут попасть фразы с названиями других городов, даже если вы ставили ограничение по региону при сборе.
Всю дальнейшую обработку я делаю в Экселе, но для этого над таблицей нужно еще поработать.
Постобработка
Определение названия кластера
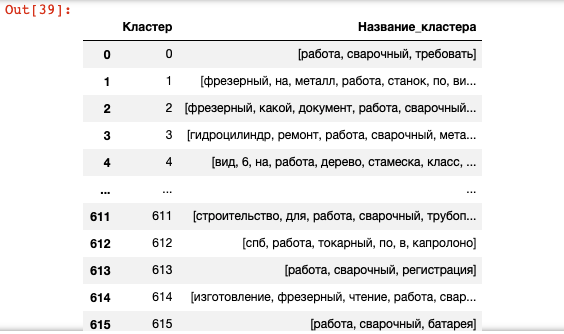
Результатом работы алгоритма кластеризации KMeans является число. Для более удобной фильтрации по полученным кластерам и последующей доработки создам еще один столбец, который будет содержать название кластера. Название будет состоять из всех слов, которые есть в кластере без повторов.
Создание копии таблицы:
df2 = df.copy()
Создание нового столбца "Название кластера" и запись в него разбитых на слова фраз из столбца "Леммы":
df2['Название_кластера'] = df2['Леммы'].str.split()
Название каждого кластера будет состоять из всех слов, которые встречаются во фразах во всем кластере.
Для этого делаю сводную таблицу по номеру кластера и сложение всех слов в нем, сведенные данные сохраняются в новой таблице df_cluster_with_name:
df_cluster_with_name = df2.pivot_table(index=['Кластер'], values='Название_кластера', aggfunc='sum').reset_index()

Теперь все слова из фраз в кластере объединены в один список. Почти в каждом списке могут быть неуникальные слова.
Удаление дубликатов слов. Превращение каждого списка (list) в формат множества (set), а потом обратно в список:
df_cluster_with_name['Название_кластера'] = df_cluster_with_name['Название_кластера'].apply(lambda x: list(set(x)))
Удаление предлогов из оставшихся слов в списках. Здесь пригодится таблица-словарь с предлогами:
for pretext in list_of_pretext['predlogi']:
for cluster_name in df_cluster_with_name['Название_кластера']:
if pretext in cluster_name:
cluster_name.remove(pretext)
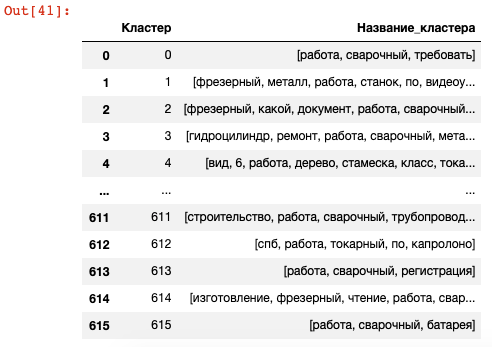
Удаление квадратных скобок:
def extract_words(cluster_name):
return ', '.join(cluster_name)
df_cluster_with_name['Название_кластера'] = df_cluster_with_name['Название_кластера'].apply(extract_words)

Чтобы в основной таблице напротив каждой фразы помимо номера кластера было название, нужно свести таблицу с кластерами и названиями df_cluster_with_name с общей таблицей df. Результат записывается в df:
df = df.merge(df_cluster_with_name, on='Кластер')

Определение дополнительных признаков
Тут пригодятся остальные таблицы-словари:
-
список городов – spisok_gorodov,
-
список «информационных слов» - spisok_vopros_slov,
-
список «коммерческих слов» - spisok_kommercheskih_slov.
Эти признаки могут пригодиться для более гибкой фильтрации и сортировки в Экселе, а также для статистического анализа.
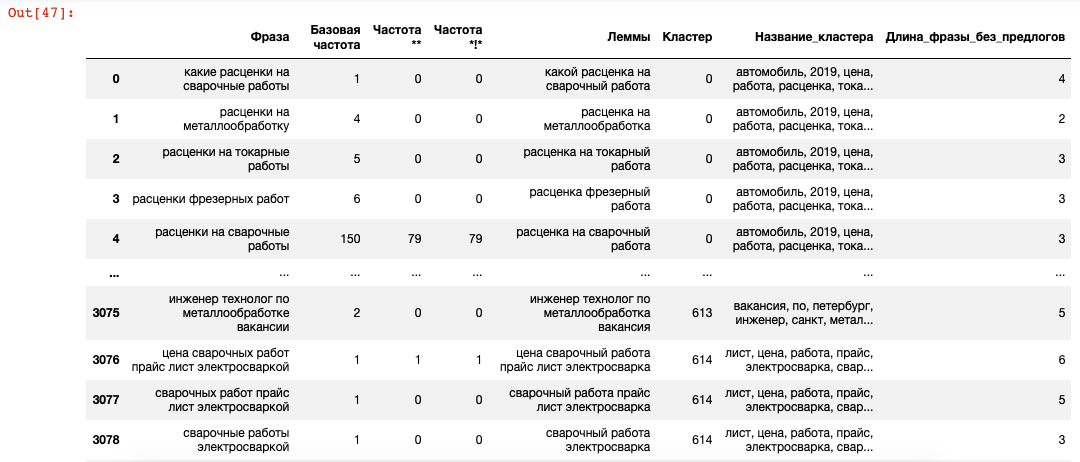
Определение длины фраз
В новый столбец «Длина фразы без предлогов» записываются разбитые на слова фразы:
В новый столбец «Длина фразы без предлогов» записываются разбитые на слова фразы:
df['Длина_фразы_без_предлогов'] = df['Фраза'].str.split()
Удаление предлогов:
for pretext in list_of_pretext['predlogi']:
for splitted_phrase in df['Длина_фразы_без_предлогов']:
if pretext in splitted_phrase:
splitted_phrase.remove(pretext)
Замена всех списков со словами на длину этих списков:
df['Длина_фразы_без_предлогов'] = df['Длина_фразы_без_предлогов'].apply(lambda x: len(x))
Определение топонима в составе фразы
В новый столбец «Город» записываются разбитые на слова лемматизированные фразы:
df['Город'] = df['Леммы'].str.split()
Функция, которая принимает разбитые на слова лемматизированные фразы, внутри запускается цикл, который берет название каждого города из таблицы spisok_gorodov и сравнивает со словами в разбитых фразах:
def find_city(splitted_lemmas):
for city in list_of_cities['goroda'].str.lower():
if city in splitted_lemmas:
return city
Функция применяется к столбцу «Город»:
df['Город'] = df['Город'].apply(find_city)
Где город не определен ставится прочерк «-»:
df['Город'].fillna(value='-', inplace=True)
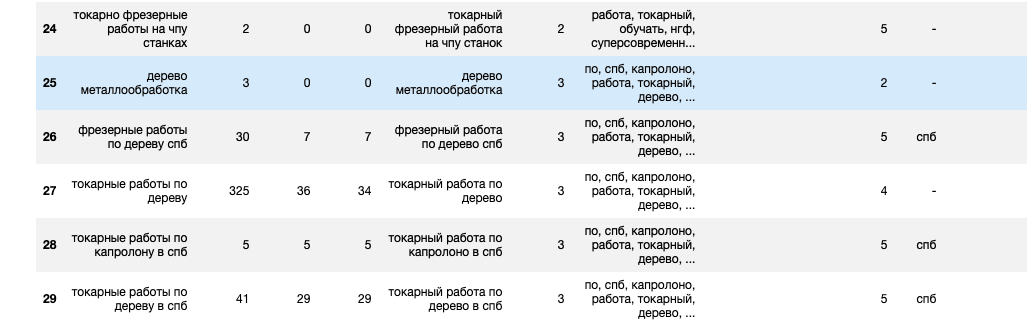
Определение является ли запрос информационным
Похожие действия с использованием таблицы-словаря с вопросительными словами spisok_vopros_slov. «Информационность» определяется по наличию в фразе слова «как», «какой» и т.д:
df['Информационный_характер'] = df['Фраза'].str.split()
def find_questions(splitted_phrase):
for word in list_of_questions['vopros'].str.lower():
if word in splitted_phrase:
return 'инфо'
df['Информационный_характер'] = df['Информационный_характер'].apply(find_questions)
df['Информационный_характер'].fillna(value='-', inplace=True)
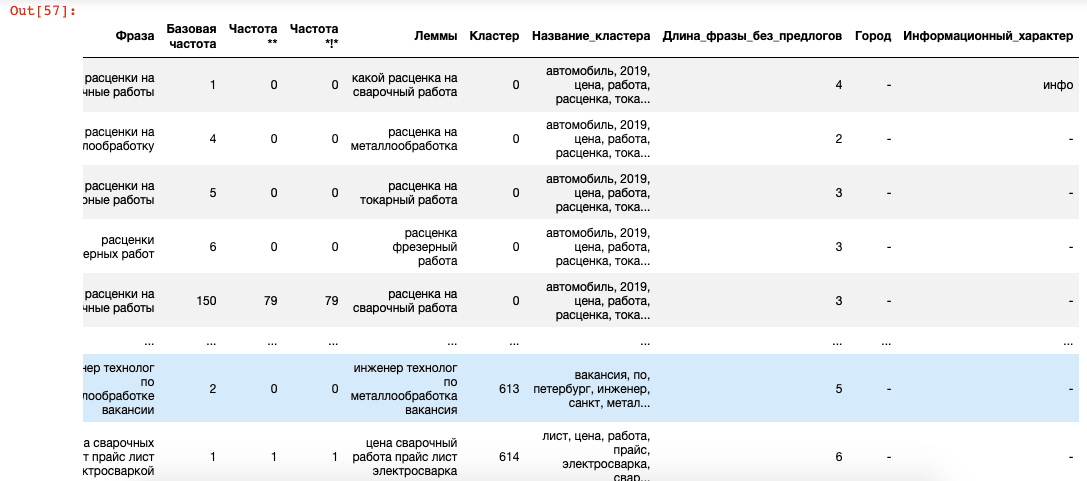
Определение является ли запрос коммерческим
Похожие действия с использованием таблицы-словаря с коммерческими словами spisok_kommercheskih_slov:
df['Коммерческий_характер'] = df['Леммы'].str.split()
def find_commerce(splitted_lemmas):
for word in list_of_commerce_words['komm'].str.lower():
if word in splitted_lemmas:
return 'коммерческий'
df['Коммерческий_характер'] = df['Коммерческий_характер'].apply(find_commerce)
df['Коммерческий_характер'].fillna(value='-', inplace=True)
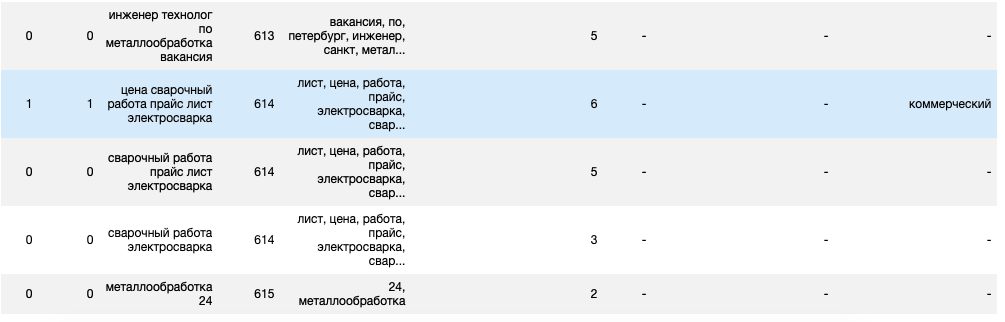
Экспорт
Для удобства запишу фразы с неприоритетными названиями регионов в отдельную таблицу df_ready_regions.
Фильтрация по условию: «не спб», «не санкт-петербург», «не -»:
df_ready_regions = df[(df['Город'] != 'спб') & (df['Город'] != 'санкт-петербург') & (df['Город'] != '-')]
Запись фраз с приоритетным регионом в таблицу df_ready:
df_ready = df[(df['Город'] == 'спб') | (df['Город'] == 'санкт-петербург') | (df['Город'] == '-')]
Если у вас используется только одно название города.
Например, все, что «не Псков»:
df_ready_regions = df[df['Город'] != 'псков']
Все фразы с «Псков и «-»»:
df_ready = df[(df['Город'] == 'псков') | (df['Город'] == '-')
Экспорт готовой таблицы
Создание таблицы с названием ready_table.xlsx. Фразы с приоритетным регионом записываются на лист таблицы «Основной список запросов», регионы – на «Регионы»:
writer_kernel = pd.ExcelWriter('ready_table.xlsx', engine='xlsxwriter')
df_ready.to_excel(writer_kernel, sheet_name='Основной список запросов', index=False)
df_ready_regions.to_excel(writer_kernel, sheet_name='Регионы', index=False)
writer_kernel.save()Ручная очистка таблицы в Excel
Выше я писал о том, что скорее всего возникнет необходимость очищать готовую таблицу от нерелевантных фраз, которые не были учтены в стоп-листе. Для решения этой задачи я фильтрую столбец «Название кластера», просматриваю каждое название, которое состоит из всех слов в кластере, чтобы выявить нерелевантные слова. Когда вижу слово в названии, которое вызывает у меня подозрение, включаю этот кластер в фильтр, чтобы детально рассмотреть его:

Просматриваю все нафильтрованные кластеры фраз и понимаю, что они никак не отнсятся к бизнесу, который мне нужно продвинуть:
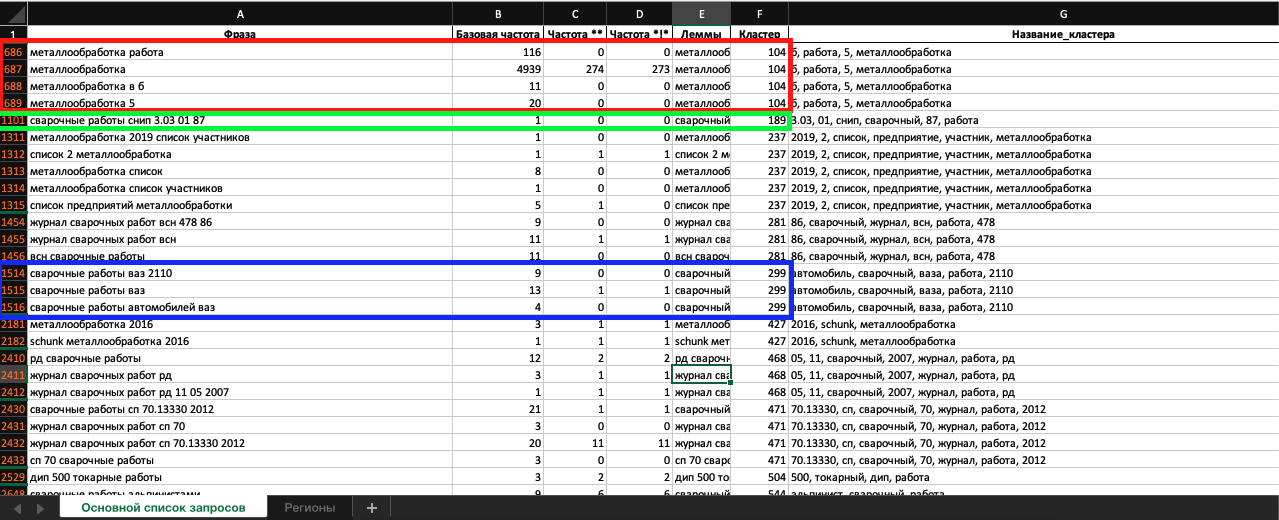
Принимаю решение о полном удалении. Выделяю строки и нажимаю удалить:

Готово, все строки удалены. Снова нажимаю на фильтр и продолжаю фильтровать названия, в которых мне не нравятся какие-либо слова:
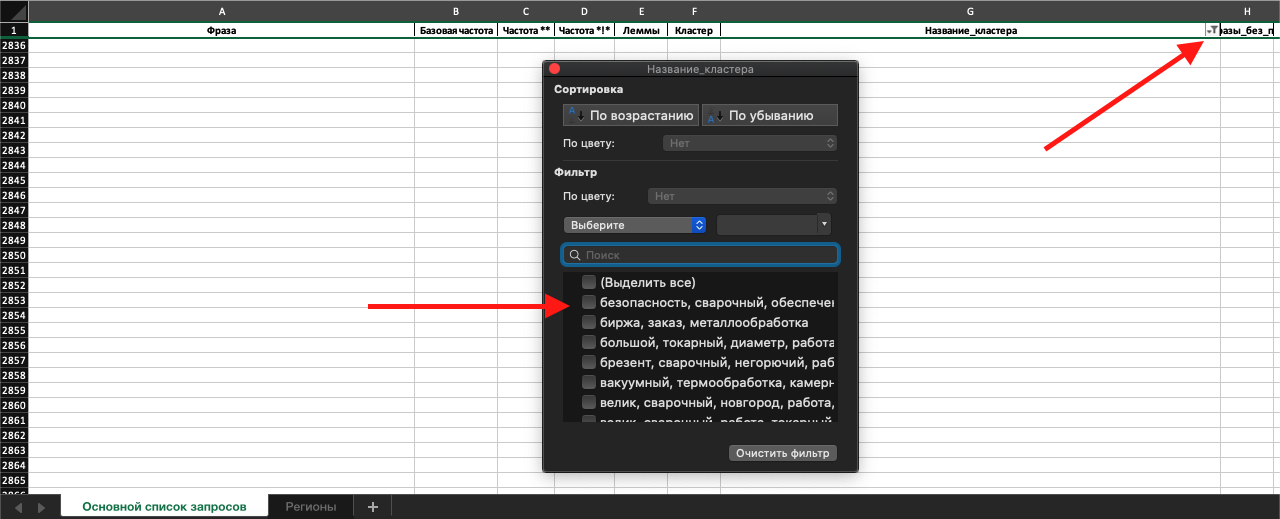
И так продолжаю очистку пока в списке не останутся только релевантные фразы.
В конце анализирую оставшиеся релевантные фразы, оцениваю адекватность кластеризации и дорабатываю, если меня что-то не устраивает. Дополнительно переименновываю названия кластеров в более удобные для восприятия, чтобы презентовать список фраз клиенту. Посмотреть пример подготовленного списка запросов можно в таблице ready_table_clean.
На этом этапе вы совершенно не ограничены в способах просмотра и удаления фраз - используйте фильтр, сортировки, выделяйте фразы маркером, в общем все, что вас приведет к очищенному списку фраз.
Можно попробовать еще один вариант: во время фильтрации по столбцу «Название кластера» и просмотра названий, которые состоят из слов, выписывайте слова, которые вам не нравятся, добавляйте их в таблицу со стоп-словами spisok_stop_slov, потом выполните весь процесс кластеризации и обработки фраз заново.
Описанный в статье процесс обработки поисковых запросов не является идеальным и не решает все задачи и проблемы, но значительно ускоряет работу по созданию семантического ядра.


