Автоматизация - Анализ статистики поисковых запросов на Python
Содержание:
Поисковой спрос можно исследовать с помощью графиков и статистических метрик. Это может стать не только отличным дополнением к семантическому ядру, которое получается после кластеризации, очистки нерелевантых фраз и анализа интента, но и помочь пропустить этот этап в некоторых случаях, особенно если данных очень много.
В статье про создание семантического ядра я упоминал, что критическим моментом является скорость анализа поискового спроса, чем больше времени уходит на кластеризацию, очистку и анализ, тем сильнее падает кпд этого этапа. Ведь семантическое ядро само по себе не продвигает сайт, а просто помогает сформировать понимание спроса и определить вектор работы.
Кластеризация фраз и анализ поисковой выдачи является очень важным этапом при продвижении сайтов услуг и сложных товаров, но как правило статистика по таким отраслям не будет пугающе большой и может быть обработана в короткие сроки особенно, если вы будете использовать автоматические методы кластеризации по фразам и по поисковой выдаче.
Но что делать, если вы работаете над интернет-магазином с товарами из мейнстримных областей, например продукты питания, косметика, одежда, бытовая техника, автомобильные комплектующие? Собранная статистика может быть настолько объемной, что после автоматической кластеризации понадобится много времени разбор всего, что получилось, а в некоторых случаях (например, 80 000 + фраз) кластеризация на Python займет много времени, т.к с увеличением количества данных растет вычислительная сложность и время работы алгоритма.
С помощью графиков, статистических метрик и срезов данных можно составить представление о поисковых фразах, сделать выводы и попробовать реализовать гипотезы непосредственно на сайте.
Как использовать код из статьи
-
файл keyword_statistic_analyze.ipynb с кодом, который приведен в статье;
-
исходные данные: таблица frazy_kosmetika.xlsx с поисковыми фразами для исследования, таблица spisok_predlogov.xlsx со списком предлогов;
-
результат работы кода: таблица srezy_fraz_po_chastote.xlsx со срезами поисковых фраз для детального изучения, таблица analiz_slov.xlsx со значениями доли каждого уникального слова в общем наборе фраз.
Запустите Анаконду.
Запустите Jupyter Notebook и откройте скачанный файл keyword_statistic_analyze.ipynb:
Загрузка библиотек
import pandas as pd
import matplotlib.pyplot as plt
Pandas – инструмент для работы с данными. С его помощью легко загружать и экспортировать таблицы, осуществлять над ними различные манипуляции.
Matplotlib – библиотека для создания графиков.
Загрузка поисковых фраз
Для загрузки использую xlsx файл. На основном листе фразы, которые не содержат топонимов или относятся только к Санкт-Петербургу:
df = pd.read_excel('frazy_kosmetika.xlsx')На листе «Регионы» фразы, содержащие другие названия городов:
df_regions = pd.read_excel('frazy_kosmetika.xlsx', sheet_name='Регионы')Свойство shape показывает размер таблицы. Первое значение – количество строк, второе – количество столбцов:
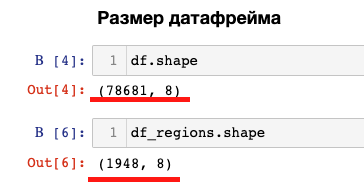
Основной список фраз содержит 78681 фразу, на листе «Регионы» - 1948 фраз.
8 столбцов:
- фразы, частота «» и частота «!», полученные с помощью программы Key Collector,
- леммы (фраз со словами в словарной форме), длина фразы без предлогов, наличие информационного слова, наличие коммерческого слова – как были рассчитаны эти признаки можно посмотреть в статье Кластеризация поисковых запросов на Python.
Фразы очищены от стоп-слов, об этом процессе также можно прочитать в статье про автоматическую кластеризацию.
Сами фразы не кластеризованы. 80 тысяч фраз – как раз тот случай, когда кластеризация имеет высокую вычислительную сложность и занимает много времени, к тому же на работу с результатами и очистку от нерелевантных фраз уйдет еще очень много времени.
Справедливо можно заметить, что из-за «шума» (нерелевантных фраз) в исходных данных в статистическом исследовании может быть много искажений. Думаю, что в случае простого анализа поисковых фраз это допустимо, мы не делаем социологическое или бизнес исследование со множеством признаков, у нас довольно «плоские» данные.
Анализ фраз по длине
Фразы какой длины представлены в статистике
df['Длина_фразы_без_предлогов'].value_counts(normalize=True)
Процентное соотношение фраз разной длины, где 1 = 100%, а 0,35 = 35% и т.д:

Фразы из 4 слов составляют 35%, из 3 слов – 27%, из 5 -22% и т.д. Больше всего фраз из 4 слов, меньше всего из 1 и 7 – менее 1%.
Визуализация на гистограмме:
with plt.style.context('fivethirtyeight'):
df['Длина_фразы_без_предлогов'].hist(figsize=(13, 6), bins=30)
plt.ylabel('Общее количество фраз')
plt.xlabel('Длина фраз')
plt.tight_layout()
plt.savefig('length_words_count.png')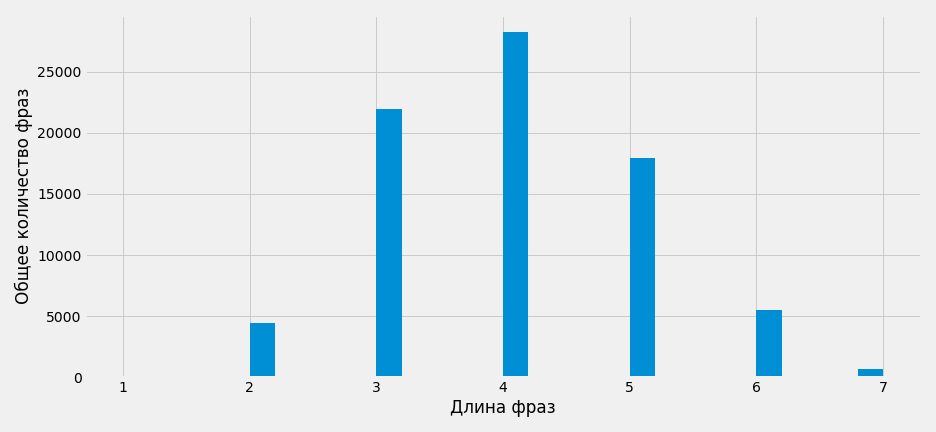
Попробуем понять какой объем частот содержат разные группы фраз. Для этого просто сложим частоту «» и частоту «!» и отобразим на графике:
with plt.style.context('fivethirtyeight'):
(
df.groupby('Длина_фразы_без_предлогов')[['Частота ""', 'Частота "!"']]
.sum()
.plot(kind = 'bar', figsize =(16,8))
)
plt.ylabel('Сумма частот для фраз каждой длины')
plt.xlabel('Длина фраз')
plt.xticks(rotation=360)
plt.tight_layout()
plt.savefig('lenght_words_freq_sum.png')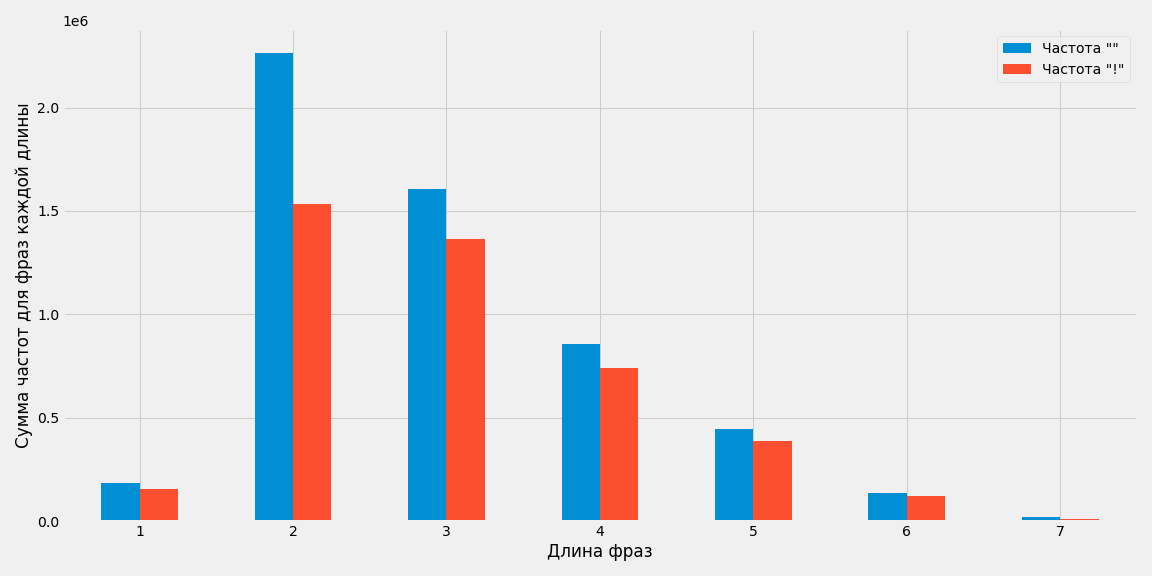
Не смотря на то, что большая часть фраз состоит из 4 слов, самые «увесистые» по частоте состоят из 2 слов, на долю которых приходится всего 5% - наверное там какие-то самые популярные фразы. На втором месте по сумме всех частот фразы из 3 слов, они же на втором месте по доле от всего количества фраз – 27%. Возможно это самые интересные для продвижения в плане ценности фразы. В целом диаграмма выглядит адекватно: чем длиннее поисковые запросы, тем они уникальнее и обладают более низкой частотой.
Я бы сделал промежуточный вывод, что в статистике по фразам о косметике преобладают фразы от 3 до 5 слов, большая часть которых приходится на довольно длинные фразы (4 и 5). Стоит рассмотреть каждую группу отдельно и попытаться сделать выводы. Сделаю это на этапе срезов, а пока перейду к анализу общей информации о частотности.
Распределение фраз по частотности
Для понимания, как распределяются поисковые фразы по частоте, можно посчитать максимальное и минимальное значение, среднее и медиану, визуализировать данные на гистограмме и диаграмме размаха. С помощью Python это сделать очень просто.
Общее описание данных
К столбцам с частотой «» и частотой «!» применим функцию describe():
df[['Частота ""', 'Частота "!"']].describe()
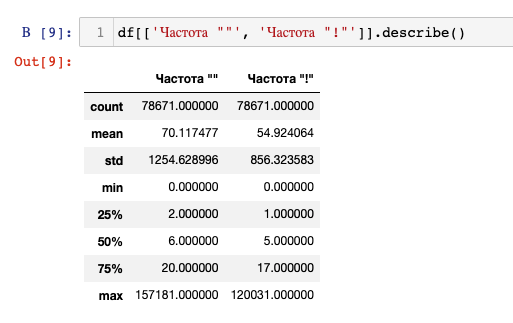
Mean – среднее арифметическое, 50% - медиана, min и max – минимальное и максимальное значение, std – стандартное отклонение.
Среднее является алгебраической характеристикой, т.к для расчетов используются все данные, из-за этого оно подвержено влиянию выбросов – экстремально больших или малых значений, которые выбиваются из общей выборки и «утягивают» среднее значение за собой.
Медиана (50%) – структурная характеристика, число которое находится по середине упорядоченного списка значений, т.е. 50% значений больше медианы, а другая половина меньше.
Разница между средним и медианой и структурной метрикой 75% показывает, что датасет «скошен» в сторону больших значений, которые сильно выбиваются из общей выборки и «утягивают» за собой среднее. Основная часть данных сконцентрирована около медианного значения (это хорошо будет видно на графиках).
Std (стандартное отклонение) – контринтуитивная метрика, которая говорит о сильном разбросе данных, в нашем случае от 0 до 157181. Чем дальше от 1 значение стандартного отклонения, тем сильнее разброс.
Гистограмма
Гистограмма — это график, который показывает, как часто в наборе данных встречается то или иное значение. Построим гистограмму по частоте «». Минимальное значение в нашем датасете 0, максимальное – 157 181, при этом частота 75% от всех фраз находится в диапазоне от 0 до 20. Если построить гистограмму без дополнительных настроек, то данные будут отображены некорректно. Примерно так:
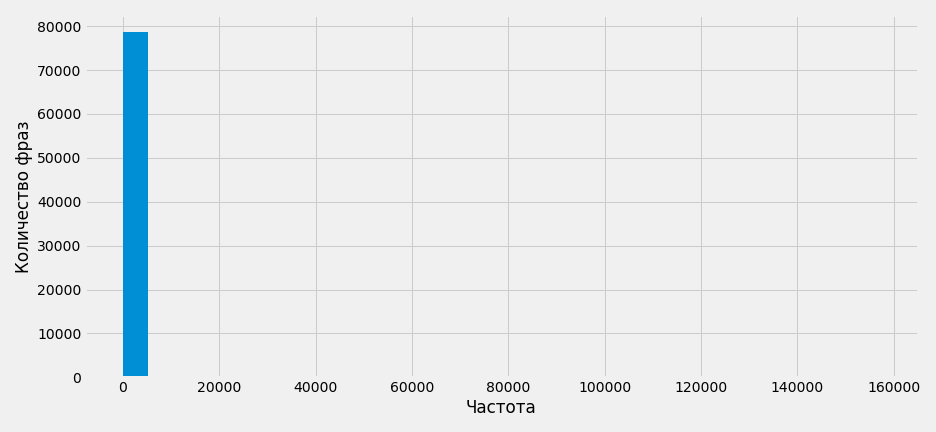
То есть почти все данные в районе от 0 до 20 000 и отображены неинформативно.
Ограничим диапазон по оси Х например до 125:
with plt.style.context('fivethirtyeight'):
df['Частота ""'].hist(figsize=(13, 6), bins=300, range=(0,125))
plt.ylabel('Количество фраз')
plt.xlabel('Частота')
plt.tight_layout()
plt.savefig('hist.png')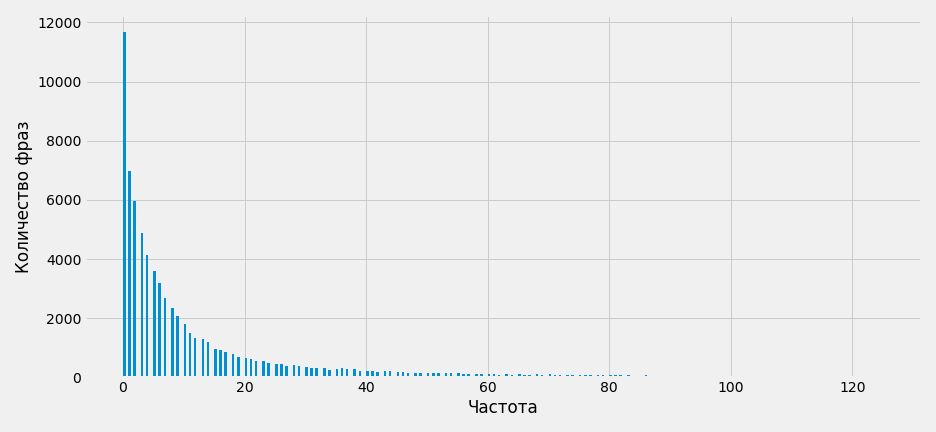
Стало намного нагляднее. Основное количество фраз сконцентрировано в районе от 0 до 20, на предыдущем этапе мы выяснили, что это 75% всех фраз, оставшиеся 25% имеют частоту больше 20, больше 40 имеют какие-то редкие фразы, а более 80 единицы. Медиана равна 6 и находится в самом крупном скоплении фраз, а среднее равно 70 и находится так далеко от медианы, потому что было «утянуто» супер частотными фразами.
Гистограмма наглядно отражает выводы, сделанные в предыдущем пункте.
Диаграмма размаха
Еще один способ составить мнение о распределении – построить диаграмму размаха, еще ее называют «ящик с усами». Построим график по частоте «» и частоте «!»:
with plt.style.context('fivethirtyeight'):
(
df[['Частота ""', 'Частота "!"']].boxplot(figsize = (8, 8))
)
plt.xticks(fontsize=18)
plt.tight_layout()
plt.savefig('boxplot_global.png')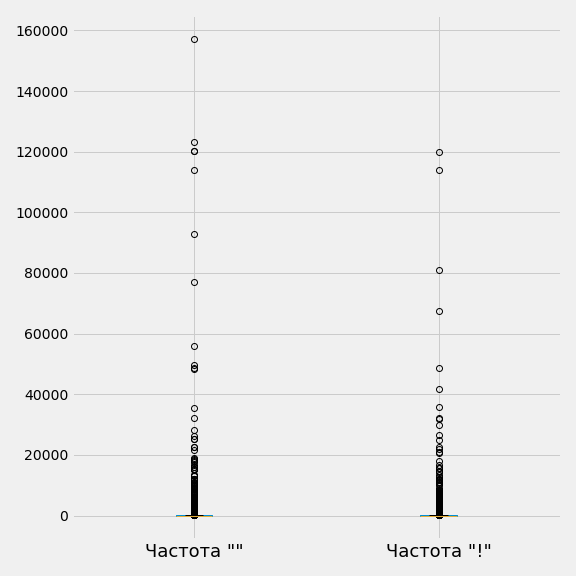
Ничего непонятно. График выглядит неинформативно, потому что большая часть данных имеет частоту до 20, они «схлопнулись» в районе 0 на графике. Отдельными кругами и скоплениями кругов являются выбросы – экстремальные значения, которые выбиваются из общей выборки. Мы помним, что самое максимальное значение в колонке с частотой «» - 157 181, последний круг около 160 000 и есть это максимальное значение. После частоты 20 000 круги можно посчитать, глядя на график, то есть это совсем небольшое количество фраз. До 20 000 большое скопление выбросов.
Переделаем график с ограничением по частоте. На гистограмме мы видели, что с частотой больше 80 фраз почти нет. Построим ящик с усами для столбцов частота «» и частота «!», где значения меньше 80:
with plt.style.context('fivethirtyeight'):
df[(df['Частота ""'] < 80) & (df['Частота "!"'] < 80)][['Частота ""', 'Частота "!"']].boxplot(figsize = (8, 8))
plt.xticks(fontsize=18)
plt.tight_layout()
plt.savefig('boxplot_less_80.png')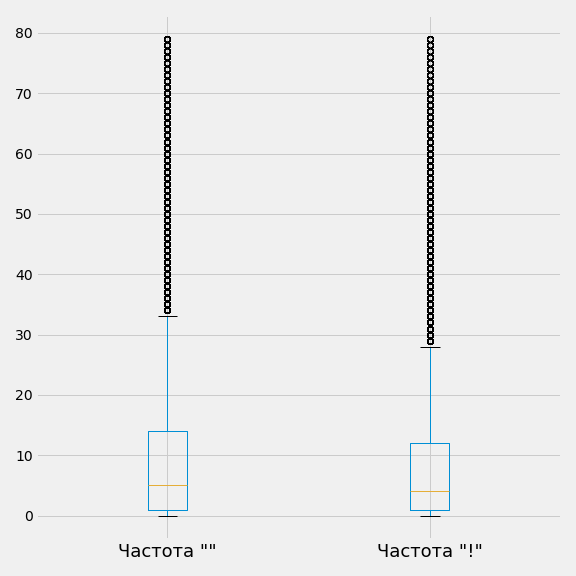
Если говорить сжато диаграмма размаха показывать межквартильный размах – от первого «уса» в районе 0 до последнего около 32 для частоты «» и примерно 28 для частоты «!». Желтая линия – медиана. Все, что находится за пределами «усов» является выбросом.
Вывод по анализу частотности
Общий обзор с помощью числовых метрик, гистограммы и диаграммы размаха говорит о том, что почти все фразы из рассматриваемой тематики обладают небольшой частотой:
-
75% фраз имеют частоту от 0 до 20,
-
небольшая часть фраз имеют частоту от 20 до 32 (частота «»),
-
все фразы больше 32 являются выбросами.
Можно сконцентрировать свое внимание на фразах от 0 до 32, остальные проигнорировать или рассмотреть все отдельно.
Срезы
На всех предыдущих шагах мы анализировали ситуацию в общем, теперь нужно перейти к деталям.
Известно, какой частотой обладает основная часть датасета, а с каких значений начинаются выбросы. Для лучшего понимания семантики лучше не удалять выбросы, а ознакомиться с ними.
Сделаем 3 среза:
-
фразы с экстремально частотными выбросами - от 20 000,
-
выбросы с менее экстремальными частоты – от 20 000 до 1000,
-
выбросы от 1000 до 32,
-
и срез с нормальными частотами.
Все срезы экспортируем в таблицу на разные листы.
Срез от 20 000 и больше
Количество фраз - 20.
most_extreme_frequency = df[df['Частота ""'] > 20000]
Срез от 20 000 до 1000
Количество фраз - 715.
twenty_k_1k_frequency = df[(df['Частота ""'] < 20000) & (df['Частота ""'] > 1000)]
Срез от 1000 до 32
Количество фраз - 13 032.
onek_32_frequency = df[(df['Частота ""'] < 1000) & (df['Частота ""'] > 32)]
Основные данные
64 579 фраз.
most_common_frequency = df[df['Частота ""'] <= 31]
Экспорт таблицы со срезами
writer_kernel = pd.ExcelWriter('srezy_fraz_po_chastote.xlsx', engine='xlsxwriter')
most_extreme_frequency.to_excel(writer_kernel, sheet_name='20 000 и больше', index=False)
twenty_k_1k_frequency.to_excel(writer_kernel, sheet_name='от 20 000 до 1000', index=False)
onek_32_frequency.to_excel(writer_kernel, sheet_name='от 1000 до 32', index=False)
most_common_frequency.to_excel(writer_kernel, sheet_name='Основные данные', index=False)
writer_kernel.save()Всю дальнейшую работу удобно выполнять в экселе – для детального изучения там все нагляднее, фразы можно двигать руками, помечать цветом, сортировать. Для фильтрации удобно использовать колонки: «Длина фраз без предлогов», «Информационный характер», «Коммерческий характер».
Кратко опишу свои действия.
Срез от 20 000 и больше
Ну тут все понятно - самые экстремально частотные фразы не имеют никакого отношения к интернет-магазину, который надо продвинуть.
Срез от 20 000 до 1000
На самой первой строчке находится самый главный запрос в нашей тематике - «израильская косметика». Далее явно информационные запросы, например «маски для роста волос в домашних условиях», «какой шампунь от перхоти самый эффективный» и т.д. Больше всего нерелевантных запросов про сериал «Маска».
Мне известно заранее, что в этой тематике, если нет коммерческих слов или другого яркого признака, например название бренда, косметической линейки или принадлежность к стране производителя, то по запросу будет информационная выдача со статьями. Об этом подробно написано в нашем кейсе.
Отфильтрую фразы по наличию коммерческих слов:
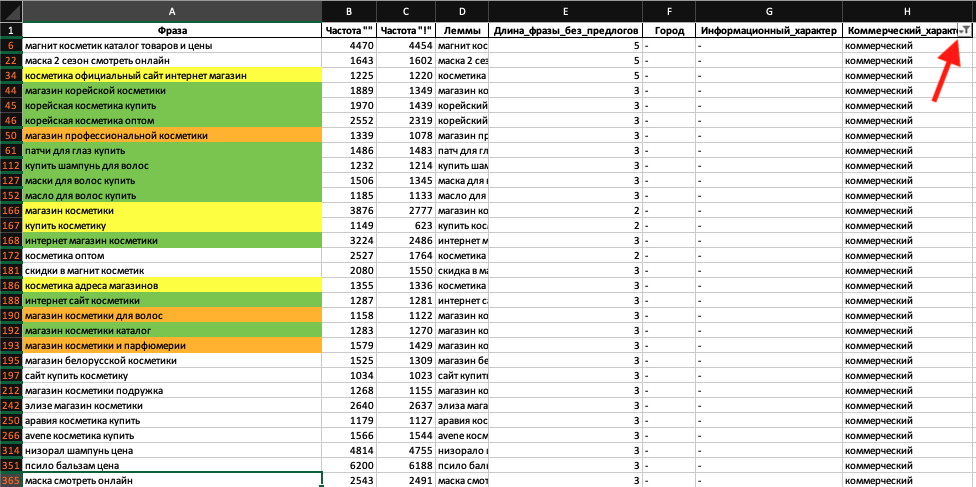
Из 716 фраз отфильтровалось 75. Зеленым отметил релевантные фразы для продвигаемого магазина, стоит попытаться оптимизировать соответствующие категории для таких запросов. Желтым отметил слишком общие и непонятные запросы, по ним можно посмотреть поисковую выдачу. Оранжевым – запросы, по которым скорее всего буду ранжироваться более специализированные магазины. Далее при просмотре отфильтрованных фраз мне встретились в основном нерелевантные запросы.
Отфильтровал фразы, исключая коммерческие признаки:
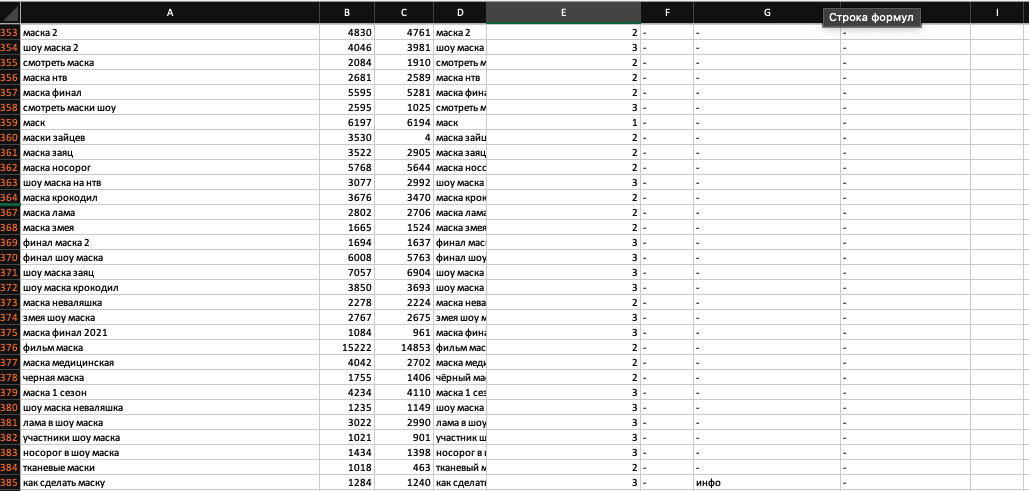
В основном я встречал нерелевантные фразы наподобие тех, что изображены на скриншоте.
В этой группе я нашел всего несколько фраз, которые можно отнести к продвигаемому сайту.
Срез от 1000 до 32
В этой группе 13032 фразы – очень много, чтобы просто просмотреть этот список.
Прежде всего отфильтрую по наличию коммерческих слов:
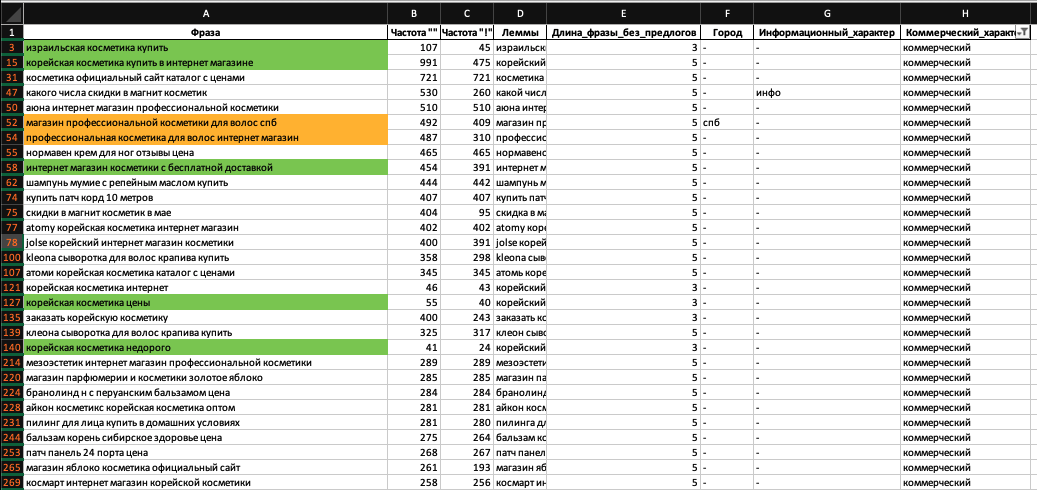
Отфильтровалось 1092 фразы. В целом запросы стали интереснее, но релевантных фраз по-прежнему немного. Если просматривать список дальше, они встречаются редко.
Далее можно попробовать делать срезы по длине фраз. Что представляют собой фразы из 2 слов:

Почти все 1800 отфильтрованных фраз – полная ерунда, встречаются редкие информационные запросы, например «коллаген в косметике», «косметика от купероза».
Фразы из 3 слов:
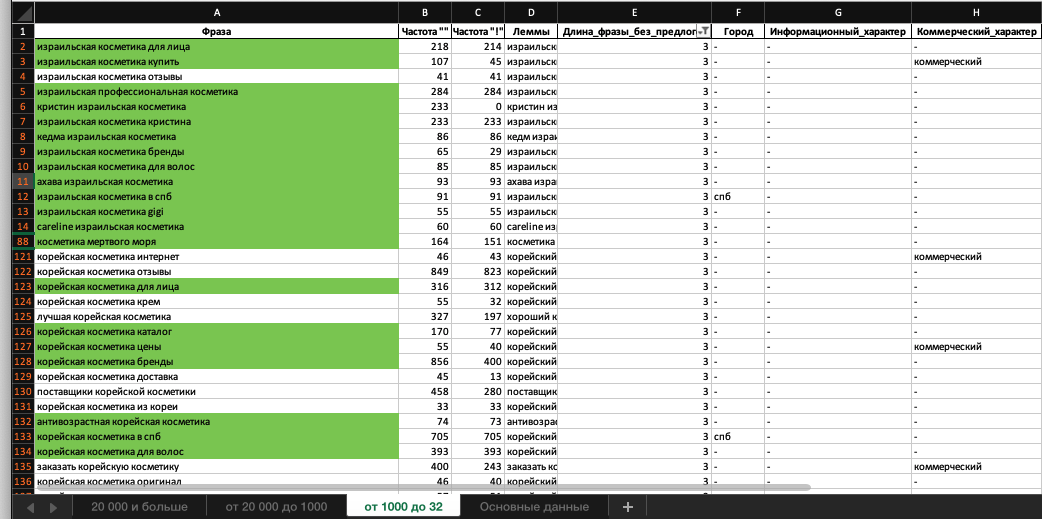
Намного больше релевантных фраз. Посмотрим еще:
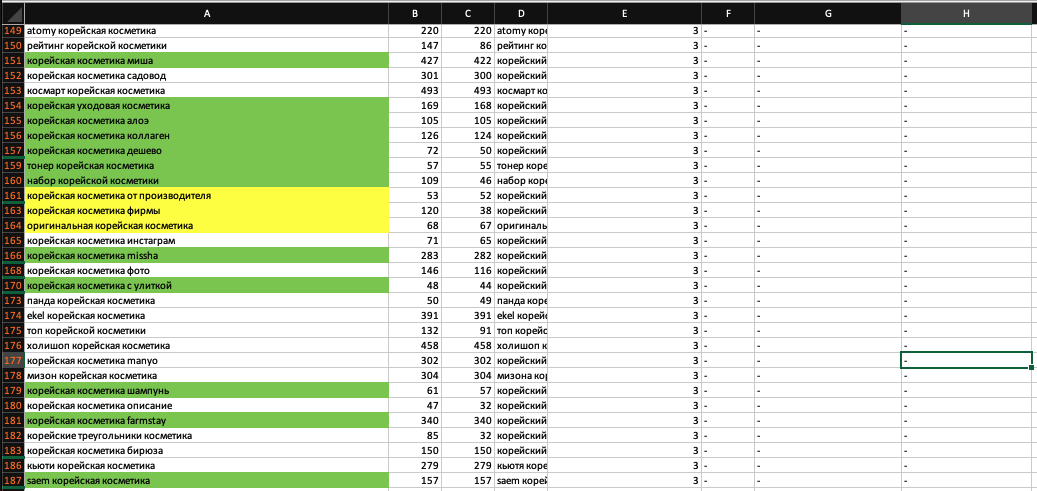
Все так же присутствуют хорошие фразы. Предположу, что с помощью фраз из 3 слов можно сделать коммерческие запросы, например «корейская косметика купить», «израильская косметика купить». Или запросы с брендом – «корейская косметика farmstay», «careline израильская косметика». Также из 3 слов (предлоги не учитываются) состоят запросы, которые описывают категорию или состав, например «израильская косметика для лица», «корейская косметика с алоэ», «корейская косметика с улиткой».
Фразы из 4 слов:
Этот срез мне совсем не нравится. Практически нет релевантных фраз. В целом большинство запросов информационные.
Такая же ситуация в срезах с фразами из 5,6 и 7 слов.
В этой группе можно найти действительно ценные фразы для продвигаемого сайта среди запросов, состоящих из 3 слов.
Основные данные – срез по частотности от 32 до 0
Самая большая группа из 64 580 фраз, которая является отражением реального спроса в тематике. Делаю такие шаги же шаги, фильтруя фразы, как на предыдущих срезах. В этом срезе на мой взгляд интересные данные в длинных фразах, начиная с 4 слов:
Группа фраз из 4 слов самая крупная – 23 967, это отражает ранее полученные данные на графиках, где на гистограмме фразы из 4 слов занимают самый большой сегмент.
В коммерческих и информационных запросах появляется больше подробностей по назначению средства и по составу, например «крем с коллагеном для лица антивозрастной», «limoni антивозрастной крем для лица».
Фразы из 5 слов:

Большая группа – 15 873 фразы. Чем длиннее запрос, тем больше подробностей по составу и назначению косметического средства, например «маска для лица на основе живого коллагена», «лосьон кондиционер лонда для кудрявых волос».
Фразы из 6 слов:
В запросах еще больше подробностей.
Вывод по срезам
Конечно, просмотр фраз в каждом срезе не ограничивался просмотром первых десятков фраз, как показано на скриншоте, мне потребовалось гораздо больше времени. Я попытался кратко продемонстрировать подход.
В срезе с самой большой частотой ничего полезного.
В срезе с частотой от 20 000 до 1000 встретилось несколько важных фраз, которые и так были очевидны: «израильская косметика», «интернет магазин косметики» и т.д.
Немало полезных фраз в срезе по частоте от 1000 до 32 во фразах, которые состоят из 3 слов. Кроме коммерческих фраз вроде «израильская косметика купить», есть релевантные с хорошей частотностью, которые содержат название бренда - «корейская косметика farmstay», «careline израильская косметика». В этом сегменте прослеживаются признаки, которые люди используют для конкретизации запроса, например «израильская косметика для лица», «корейская косметика с алоэ», «корейская косметика с улиткой».
Срез по частотности от 32 до 0 представляет основу собранной поисковой статистики, именно таких фраз больше всего. Исследуя длинные запросы 4-7 слов, можно выявить признаки, которые люди используют для конкретизации запроса – это бренд, линейка бренда, точное название косметического средства, ключевые ингредиенты в составе, назначение.
Анализ слов
Дополнительно к графикам и срезам можно посмотреть из каких слов состоят фразы, и какие слова доминируют. Для этого нам пригодится столбец «Леммы», в котором все слова во фразах приведены в словарную форму. Еще понадобится список предлогов, который хранится в отдельной таблице «spisok_predlogov».
Фразу, состоящую из лемм, разобьем на отдельные слова в формате списка. В качестве разделителя используется пробел split(‘ ’):
df['Леммы_по_словам'] = df['Леммы'].apply(lambda x: x.split(' '))Весь датафрем с фразами, частотой и другими признаками превратим в словарь:
df_dict = df.to_dict('record')Каждое слово в словарной форме (лемму) добавим в общий список всех слов list_of_words:
list_of_words = []
for row in df_dict:
list_of_lemmas = row['Леммы_по_словам']
for word in list_of_lemmas:
list_of_words.append(word)
Получился список из 374221 слов:

Из списка всех слов удалим предлоги. Тут нам понадобится загруженный список предлогов:
for pretext in spisok_predlogov['predlogi']:
for word in list_of_words:
if pretext == word:
list_of_words.remove(word)
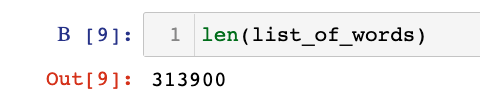
Осталось 313900 слов:
Полученный список передадим в pandas и превратим его в DataFrame:
df_words = pd.DataFrame(list_of_words, columns=['Слова'])
Визуализация
Визуализируем на столбчатой диаграмме, выведем ТОП-50 слов:
with plt.style.context('fivethirtyeight'):
(
df_words['Слова']
.value_counts(normalize=True)
.head(50)
.sort_values(ascending=True)
.plot(kind='barh', figsize =(8,12))
)
plt.ylabel('ТОП-50 слов')
plt.xlabel('Доля от общего количества в %')
plt.tight_layout()
plt.savefig('words_percentage.png')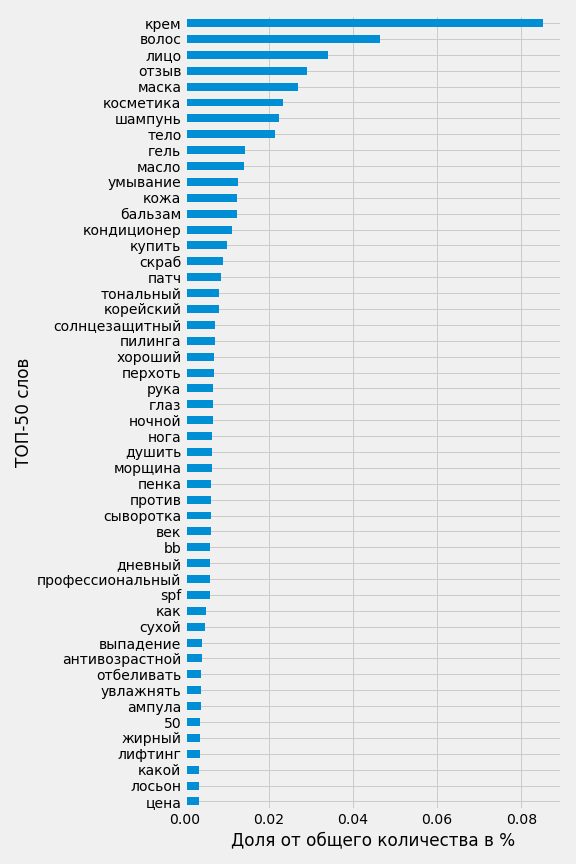
По оси Х указана доля в %, которую занимает слова от общего числа слов. 1 – это 100%, поэтому 0.08 – это 8%.
Лидирует среди всех слово «крем» - больше 8% от всех слов, а это примерно 25 112 раз в общем списке слов (313 900 слов). Примерно в таком количестве фраз из общей статистики может встречаться это слово. В общем – кремы самое популярное средство.
На втором месте «волосы», на третьем – «лицо», можно предположить, что это очень популярные категории. На четвертом месте «отзывы» - почти 4%, конкретно с этой тематике это очень важный формат для проработки. Об этом можно прочитать в нашем кейсе.
Запишем эти данные в таблицу, чтобы можно было ознакомиться с большим количеством слов.
Создание списка всех слов
Посчитаем количество каждого слова:
quantity = df_words.value_counts().reset_index()
Первые пять строк:

Странное название колонки можно объяснить тем, что value_counts() подсчитывает все значения в столбце (Series) и возвращает сводный отчет с уникальным значением и его количеством:

Посчитаем долю каждого слова от общего количества:
percentage = df_words.value_counts(normalize=True).reset_index()
Объединим в одну таблицу:
ready_df = quantity.merge(percentage, on='Слова')
Первые 5 строк:

Переименуем название столбцов:
ready_df.rename(columns={'0_x':'Количество', '0_y':'Доля'}, inplace=True)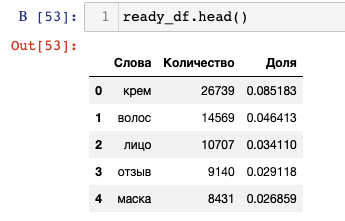
Экспорт
writer_kernel = pd.ExcelWriter('analiz_slov.xlsx', engine='xlsxwriter')
ready_df.to_excel(writer_kernel)
writer_kernel.save()Распределение частоты по городам
Всего 158 уникальных названий городов встерчается во фразах:
Сделаем сводную таблицу с суммой частоты «» для каждого города:
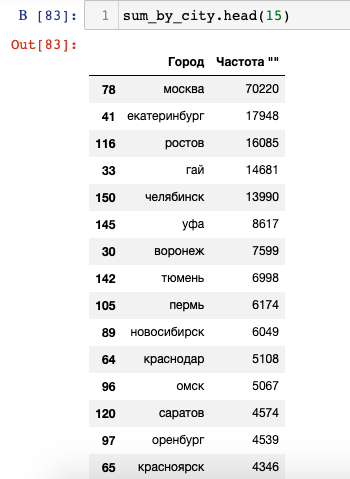
sum_by_city = df_regions.groupby('Город')['Частота ""'].sum().reset_index().sort_values(by='Частота ""', ascending=False)ТОП-15 городов:
Визуализация для 30 городов
with plt.style.context('fivethirtyeight'):
names_x = sum_by_city['Город'].head(30)
values_y = sum_by_city['Частота ""'].head(30)
plt.figure(figsize=(35,15))
plt.bar(names_x, values_y)
plt.xticks(rotation=90, fontsize=30)
plt.yticks(fontsize=20)
plt.ylabel('Частота ""', fontsize=40)
plt.xlabel('Город', fontsize=40)
plt.tight_layout()
plt.savefig('frequency_by_city.png')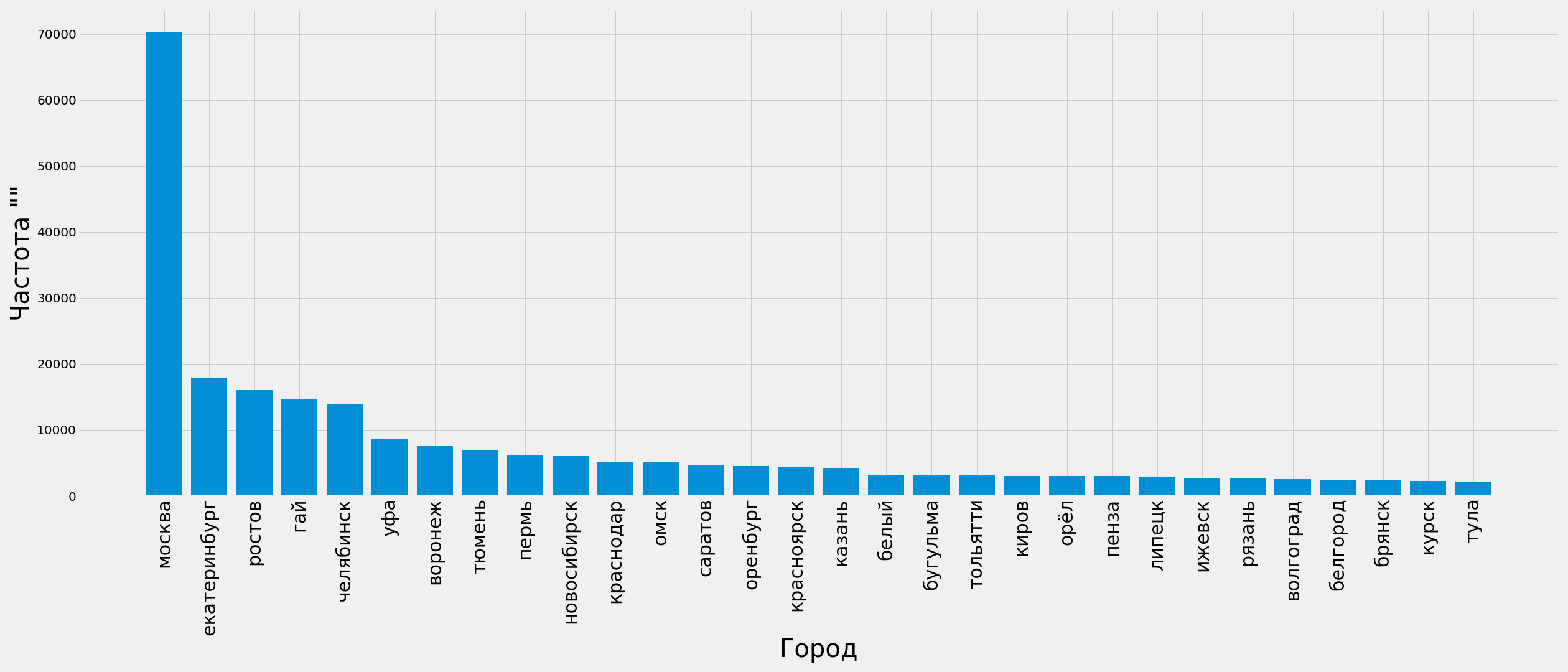
Используя такую информацию, можно принимать решение о создании региональных поддоменов. Обратите внимание на 4 место город Гай, впервые встречаю такое название. Скорее всего это ошибка. Сделаю срез по названию города:

Ошибка понятна – город Гай действительно существует, и на этапе определения города было обнаружено совпадение со словарными формами слов из нерелевантных фраз, которые обладают большой частотой. Так Гай оказался на 4 месте среди других российских мегаполисов.
Общий вывод
Была исследована статистика поисковых запросов для интернет-магазина косметики. В основном наборе данных содержится 78 681 фраз.
Основываясь на полученных данных на графиках и детальном изучении срезов, можно сказать, что спрос в тематике состоит из длинных низкочастотных запросов. В основном пользователи не используют простые общие запросы, например «израильская косметика», «корейская косметика купить», а вводят в поисковых системах длинные запросы с уточнениями, например «маска для лица на основе живого коллагена», которые соответствуют индивидуальными потребностям.
Такие «личные» поисковые запросы обладают низкой частотой. Частотность 75% всех фраз находится в диапазоне 0-20. Для привлечения такого трафика лучшим форматом будут карточки товаров, они содержат все необходимы ключевые слова: бренд, линейка бренда, название продукта, тип средства, ингредиенты и описание задач, которые решаются с помощью этого продукта.
Для оптимизации менее точных запросов, например «израильская косметика для лица» и т.п. необходимо создать соответствующие категории.
Конечно, стоит пытаться сделать максимум усилий для выхода в ТОП по самым частотным запросам, например «израильская косметика», «интернет-магазин косметики», но при этом следует помнить, что основной трафик будет приходить по низкочастотным запросам.
С помощью анализа по словам можно попытаться выявить доминирующие категории, например на долю слова «крем» приходится 8% от всего количества слов, а на слово «отзывы» - 4% - важно разобраться, как собирать трафик по отзывам.
Важным нюансом в этой тематике является интент. В этой статье эта тема не была затронута. Если фраза не содержит явный коммерческий признак, т.е. слова «купить», «цена» и т.п. или название бренда, линейки или продукта, то поисковая выдача будет информационной. В тематике доминирует информационный интент. Работа с блогом или другими информационными форматами может стать еще одной точкой роста трафика, помимо карточек и категорий.
Такой анализ может быть отличным дополнением к кластеризованному семантическому ядру или помочь обойти этап кластеризации, если данных непосильно много. Весь смысл анализа поискового спроса для SEO не в готовой табличке с фразами, а в понимании поискового спроса. Такое понимание может дать описанный в статье подход.


